Hive 的基本概念

Hadoop开发存在的问题
只能用java语言开发,如果是c语言或其他语言的程序员用Hadoop,存在语言门槛。
需要对Hadoop底层原理,api比较了解才能做开发。
Hive概述
Hive是基于Hadoop的一个数据仓库工具。可以将结构化的数据文件映射为一张表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取、转化、加载(ETL Extract-Transform-Load ),也可以叫做数据清洗,这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HiveQL,它允许熟悉 SQL 的用户查询数据。
Hive的Hql
HQL - Hive通过类SQL的语法,来进行分布式的计算。HQL用起来和SQL非常的类似,Hive在执行的过程中会将HQL转换为MapReduce去执行,所以Hive其实是基于Hadoop的一种分布式计算框架,底层仍然是MapReduce,所以它本质上还是一种离线大数据分析工具。
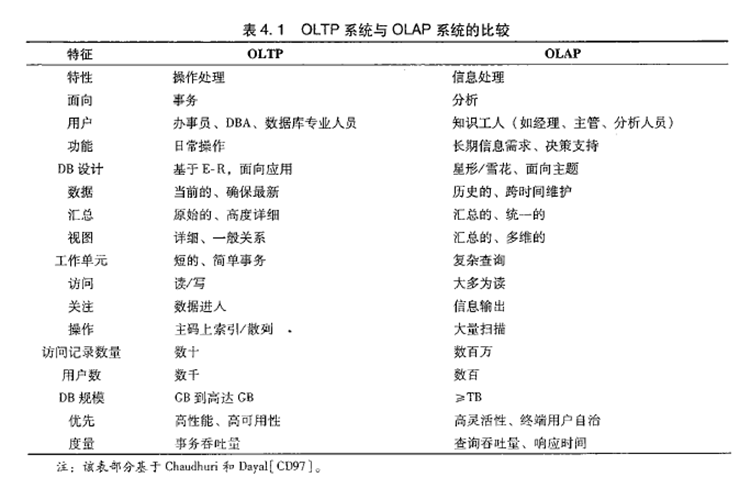
数据仓库的特征
1.数据仓库是多个异构数据源所集成的。
2.数据仓库存储的一般是历史数据。 大多数的应用场景是读数据(分析数据),所以数据仓库是弱事务的。
3.数据库是为捕获数据而设计,数据仓库是为分析数据而设计。
4.数据仓库是时变的,数据存储从历史的角度提供信息。即数据仓库中的关键结构都隐式或显示地包含时间元素。
5.数据仓库是弱事务的,因为数据仓库存的是历史数据,一般都读(分析)数据场景。
数据库属于OLTP系统。(Online Transaction Processing)联机事务处理系统。涵盖了企业大部分的日常操作,如购物、库存、制造、银行、工资、注册、记账等。比如Mysql,oracle等关系型数据库。
数据仓库属于OLAP系统。(Online Analytical Processing)联机分析处理系统。Hive,Hbase等
OLTP是面向用户的、用于程序员的事务处理以及客户的查询处理。
OLAP是面向市场的,用于知识工人(经理、主管和数据分析人员)的数据分析。
OLAP通常会集成多个异构数据源的数据,数量巨大。
OLTP系统的访问由于要保证原子性,所以有事务机制和恢复机制。
OLAP系统一般存储的是历史数据,所以大部分都是只读操作,不需要事务。
适用场景
Hive 构建在基于静态(离线)批处理的Hadoop 之上,Hadoop 通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,Hive 并不能够在大规模数据集上实现低延迟快速的查询,例如,Hive 在几百MB 的数据集上执行查询一般有分钟级的时间延迟。因此,Hive 并不适合那些需要低延迟的应用,例如,联机事务处理(OLTP)。Hive 查询操作过程严格遵守Hadoop MapReduce 的作业执行模型,Hive 将用户的HiveQL 语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。Hive 并非为联机事务处理而设计,Hive 并不提供实时的查询和基于行级的数据更新操作。Hive 的最佳使用场合是大数据集的离线批处理作业,例如,网络日志分析。
Hive 的基本概念的更多相关文章
- 【Hadoop离线基础总结】数据仓库和hive的基本概念
数据仓库和Hive的基本概念 数据仓库 概述 数据仓库英文全称为 Data Warehouse,一般简称为DW.主要目的是构建面向分析的集成化数据环境,主要职责是对仓库中的数据进行分析,支持我们做决策 ...
- 大数据核心知识点:Hbase、Spark、Hive、MapReduce概念理解,特点及机制
今天,上海尚学堂大数据培训班毕业的一位学生去参加易普软件公司面试,应聘的职位是大数据开发.面试官问了他10个问题,主要集中在Hbase.Spark.Hive和MapReduce上,基础概念.特点.应用 ...
- Hive的基本概念和常用命令
原文链接: https://www.toutiao.com/i6766571623727235595/?group_id=6766571623727235595 一.概念: 1.结构化和非结构化数据 ...
- Hive(1)-基本概念
一. 什么是Hive Hive:由Facebook开源用于解决海量结构化日志的数据统计. Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能. 本 ...
- Hive从概念到安装使用总结
一.Hive的基本概念 1.1 hive是什么? (1)Hive是建立在hadoop数据仓库基础之上的一个基础架构: (2)相当于hadoop之上的一个客户端,可以用来存储.查询和分析存储在hadoo ...
- Hive深入浅出
1. Hive是什么 1) Hive是什么? 这里引用 Hive wiki 上的介绍: Hive is a data warehouse infrastructure built on top of ...
- Hive分区(静态分区+动态分区)
Hive分区的概念与传统关系型数据库分区不同. 传统数据库的分区方式:就oracle而言,分区独立存在于段里,里面存储真实的数据,在数据进行插入的时候自动分配分区. Hive的分区方式:由于Hive实 ...
- Hive的HQL语句及数据倾斜解决方案
[版权申明:本文系作者原创,转载请注明出处] 文章出处:http://blog.csdn.net/sdksdk0/article/details/51675005 作者: 朱培 ID ...
- Hive篇--相关概念和使用二
一.基本概念 Hive分桶: 1.概念 分桶表是对列值取哈希值的方式,将不同数据放到不同文件中存储.对于hive中每一个表.分区都可以进一步进行分桶.(可以对列,也可以对表进行分桶)由列的哈希值除以桶 ...
随机推荐
- centos 端口开放及关闭 【转】
之前有讲过公司新买的服务器使用的是CentOS 5.5,部署好Tomcat之后却发现输入114.80.*.*:8080(即ip:8080)却无法显示Tomcat默认的首页.因为以前部署在Win Ser ...
- 2017.7.21 python statvfs方法读取磁盘容量
实地代码 [maintenance@localhost ~]$ python Python 2.7.5 (default, Nov 6 2016, 00:28:07) [GCC 4.8.5 20150 ...
- 03 重定向,请求转发,cookie,session
重定向: /* 之前的写法 response.setStatus(302); response.setHeader("Location", "login_success. ...
- acm 2057
////////////////////////////////////////////////////////////////////////////////#include<iostream ...
- 【HDOJ1043】【康拓展开+BFS】
http://acm.hdu.edu.cn/showproblem.php?pid=1043 Eight Time Limit: 10000/5000 MS (Java/Others) Memo ...
- 几种常见的微服务架构方案简述——ZeroC IceGrid、Spring Cloud、基于消息队列
微服务架构是当前很热门的一个概念,它不是凭空产生的,是技术发展的必然结果.虽然微服务架构没有公认的技术标准和规范草案,但业界已经有一些很有影响力的开源微服务架构平台,架构师可以根据公司的技术实力并结合 ...
- drone 0.8.8 集成gogs 进行ci/cd 处理
drone 是一个不错的基于容器的ci/cd 工具,运行简单,同时插件也挺多,基本常见的轻量级的任务都是可以搞定的 环境准备 使用docker in docker docker-compose 文件 ...
- Be Careful When Using Bit Field
Below illustration is based on MSP430, IAR. See the implementation below. typedef struct { uint8_t g ...
- 围棋术语 & 中英文 。
https://senseis.xmp.net/?ChineseGoTerms 一字 二字 三字 四字 一字 长(nobi,solid extension),是指仅靠着自己的棋盘上已有棋子继续向前延伸 ...
- 写一个递归函数DigitSum(n),输入一个非负整数,返回组成它的数字之和
例如,调用DigitSum(1729),则应该返回1+7+2+9,它的和是19. 思路:我们可以先将整数的每一个数字取出来,每次取个位数字,取完后退位(将数字除以10),在取个位数字,依次取出所有的数 ...