Hive 的基本概念

Hadoop开发存在的问题
只能用java语言开发,如果是c语言或其他语言的程序员用Hadoop,存在语言门槛。
需要对Hadoop底层原理,api比较了解才能做开发。
Hive概述
Hive是基于Hadoop的一个数据仓库工具。可以将结构化的数据文件映射为一张表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取、转化、加载(ETL Extract-Transform-Load ),也可以叫做数据清洗,这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HiveQL,它允许熟悉 SQL 的用户查询数据。
Hive的Hql
HQL - Hive通过类SQL的语法,来进行分布式的计算。HQL用起来和SQL非常的类似,Hive在执行的过程中会将HQL转换为MapReduce去执行,所以Hive其实是基于Hadoop的一种分布式计算框架,底层仍然是MapReduce,所以它本质上还是一种离线大数据分析工具。
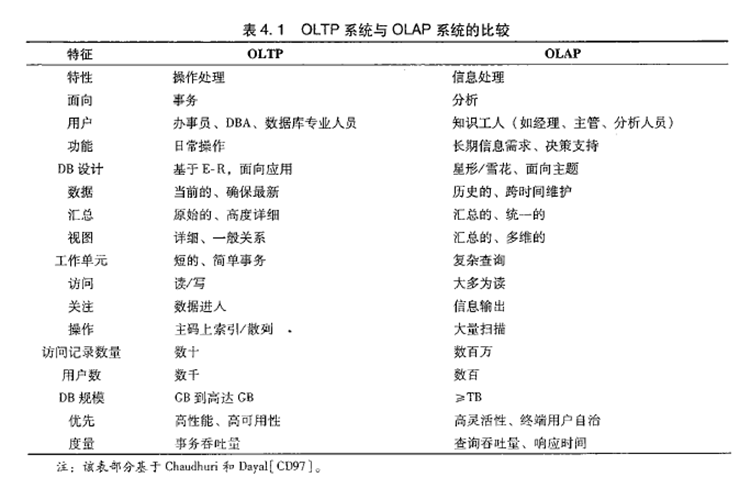
数据仓库的特征
1.数据仓库是多个异构数据源所集成的。
2.数据仓库存储的一般是历史数据。 大多数的应用场景是读数据(分析数据),所以数据仓库是弱事务的。
3.数据库是为捕获数据而设计,数据仓库是为分析数据而设计。
4.数据仓库是时变的,数据存储从历史的角度提供信息。即数据仓库中的关键结构都隐式或显示地包含时间元素。
5.数据仓库是弱事务的,因为数据仓库存的是历史数据,一般都读(分析)数据场景。
数据库属于OLTP系统。(Online Transaction Processing)联机事务处理系统。涵盖了企业大部分的日常操作,如购物、库存、制造、银行、工资、注册、记账等。比如Mysql,oracle等关系型数据库。
数据仓库属于OLAP系统。(Online Analytical Processing)联机分析处理系统。Hive,Hbase等
OLTP是面向用户的、用于程序员的事务处理以及客户的查询处理。
OLAP是面向市场的,用于知识工人(经理、主管和数据分析人员)的数据分析。
OLAP通常会集成多个异构数据源的数据,数量巨大。
OLTP系统的访问由于要保证原子性,所以有事务机制和恢复机制。
OLAP系统一般存储的是历史数据,所以大部分都是只读操作,不需要事务。
适用场景
Hive 构建在基于静态(离线)批处理的Hadoop 之上,Hadoop 通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,Hive 并不能够在大规模数据集上实现低延迟快速的查询,例如,Hive 在几百MB 的数据集上执行查询一般有分钟级的时间延迟。因此,Hive 并不适合那些需要低延迟的应用,例如,联机事务处理(OLTP)。Hive 查询操作过程严格遵守Hadoop MapReduce 的作业执行模型,Hive 将用户的HiveQL 语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。Hive 并非为联机事务处理而设计,Hive 并不提供实时的查询和基于行级的数据更新操作。Hive 的最佳使用场合是大数据集的离线批处理作业,例如,网络日志分析。
Hive 的基本概念的更多相关文章
- 【Hadoop离线基础总结】数据仓库和hive的基本概念
数据仓库和Hive的基本概念 数据仓库 概述 数据仓库英文全称为 Data Warehouse,一般简称为DW.主要目的是构建面向分析的集成化数据环境,主要职责是对仓库中的数据进行分析,支持我们做决策 ...
- 大数据核心知识点:Hbase、Spark、Hive、MapReduce概念理解,特点及机制
今天,上海尚学堂大数据培训班毕业的一位学生去参加易普软件公司面试,应聘的职位是大数据开发.面试官问了他10个问题,主要集中在Hbase.Spark.Hive和MapReduce上,基础概念.特点.应用 ...
- Hive的基本概念和常用命令
原文链接: https://www.toutiao.com/i6766571623727235595/?group_id=6766571623727235595 一.概念: 1.结构化和非结构化数据 ...
- Hive(1)-基本概念
一. 什么是Hive Hive:由Facebook开源用于解决海量结构化日志的数据统计. Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能. 本 ...
- Hive从概念到安装使用总结
一.Hive的基本概念 1.1 hive是什么? (1)Hive是建立在hadoop数据仓库基础之上的一个基础架构: (2)相当于hadoop之上的一个客户端,可以用来存储.查询和分析存储在hadoo ...
- Hive深入浅出
1. Hive是什么 1) Hive是什么? 这里引用 Hive wiki 上的介绍: Hive is a data warehouse infrastructure built on top of ...
- Hive分区(静态分区+动态分区)
Hive分区的概念与传统关系型数据库分区不同. 传统数据库的分区方式:就oracle而言,分区独立存在于段里,里面存储真实的数据,在数据进行插入的时候自动分配分区. Hive的分区方式:由于Hive实 ...
- Hive的HQL语句及数据倾斜解决方案
[版权申明:本文系作者原创,转载请注明出处] 文章出处:http://blog.csdn.net/sdksdk0/article/details/51675005 作者: 朱培 ID ...
- Hive篇--相关概念和使用二
一.基本概念 Hive分桶: 1.概念 分桶表是对列值取哈希值的方式,将不同数据放到不同文件中存储.对于hive中每一个表.分区都可以进一步进行分桶.(可以对列,也可以对表进行分桶)由列的哈希值除以桶 ...
随机推荐
- php基础-5
php的面相对象 <?php class Hello { public function say_hello() { echo "hello"; } } $say = ne ...
- 踩坑tomcat8.5的cookie机制
https://www.pomelolee.com/1601.html tomcat升级到8.5版本 发现登录和退出报错,报错日志为下 [http-nio-8080-exec-20] 2016 Aug ...
- vue全家桶+Koa2开发笔记(4)--redis
redis用来在服务器端存放session 1 安装redis brew install redis 启动redis redis-server 2 安装两个中间件 npm i koa-ge ...
- adx-desc-adtype统计
数据分析脚本: filepath="request.log.2017-12-01-15" File.open("#{filepath}").each do |l ...
- MySQL--NUMA与MySQL
============================================================= NUMA(Non-Uniform Memory Access),非一致性内存 ...
- tile38 server 密码保护
默认tile38 是没有密码保护的,我们可以通过配置指定密码,类似redis 的,但是redis 的一般我们是配置在 配置文件中的 环境准备 docker-compose 文件 version: ...
- SCS Characteristics
Each SCS is an autonomous web application. For the SCS's domain, all data, the logic to process that ...
- 区块链 blockchain
区块链是去中心化的记账方式.没有中心,安全,高效.区块链是属于分布式计算的一种.是一种数据库. 区块链不是什么比特币,xx币.而是比特币他们用了区块链的技术. 区块链具有去中心化.无须中心信任.不可篡 ...
- java_oop_类与对象
类与对象包方法 ========================================= 对象的概念类与对象的关系 万物皆对象 属性(名词) 对象的 ...
- Cobbler自动装机--1
cobbler介绍 cobbler官网:http://cobbler.github.io/用个人的话来说就是cobbler就是一款通过网络快速安装Linux操作系统的产品.cobbler可以配置,管理 ...