浅谈C++之冒泡排序、希尔排序、快速排序、插入排序、堆排序、基数排序性能对比分析之后续补充说明(有图有真相)
如果你觉得我的有些话有点唐突,你不理解可以想看看前一篇《C++之冒泡排序、希尔排序、快速排序、插入排序、堆排序、基数排序性能对比分析》。
这几天闲着没事就写了一篇《C++之冒泡排序、希尔排序、快速排序、插入排序、堆排序、基数排序性能对比分析》的随笔,由于当时有点脑残把希尔排序写错了,导致其性能很多情况下都查过了快速排序。当时我就怀疑我的算法的正确性了,由于当时的激动没来得及检查,我直呼不可思议,以至于让快速排序任希尔排序做了老爷O(∩_∩)O哈哈~,这晚辈太不敬了。感谢博友“堕落的恶魔”给我指了出来,同时和各位博友交流的过程也让我长见识了。正确的快速排序我已经更改过来了,大家不要受我之前的误导。现在重新测试一遍。
排序算法时间复杂度和空间复杂度对比:

注意:基数排序中的d是最大数的次数,r是桶数。
再和博友讨论之后,做了一些改进。
1、改进Swap()算法为:
inline void Swap(int &a,int &b)
{ a=a^b;
b=a^b;
a=a^b;
}
这里看上去似乎很完美,多简洁明了啊!!可是当我打印出结果一看我和我的小伙伴都惊呆了!!!!!如下图:
待排序数为:int a[20]={25,19,6,58,34,10,7,98,160,0,345,445,675,34,7,122,8,435,23,678};
可结果如下图:

分析发现:如果Swap(a,a)就会把a置零,而如果a=3,b=3,Swap(a,b)则不影响。尼玛,这么多陷阱!然后改代码如下:
inline void Swap(int &a,int &b)
{
if(a!=b)
{
a=a^b;
b=a^b;
a=a^b;
}
}
现在对比改进前和改进后的效率对比用快速排序测试1千万个数据。
改进前:

改进后:

总结:实践发现效率并没有升高,反而降低了。看来这种改进并没有什么直接的作用,当然这里有一个影响的因素是两组测试的数据只是个数相等。具体值都是用程序生成的随机数。
2、改进快速排序:
主要改进了基准值的选取是随机的。
改进代码:
//快速排序
///////////////////////////////////////
inline void Swap(int &a,int &b)
{
int temp;
temp=a;
a=b;
b=temp;
// if(a!=b)
// {
// a=a^b;
// b=a^b;
// a=a^b;
// }
} int Partition(int a[],int p,int r)
{
int i=p;
int j=r+;
int x=a[p];
while (true)
{
while(a[++i]<x&&i<r);
while(a[--j]>x);
if (i>=j)break;
Swap(a[j],a[i]); }
a[p]=a[j];
a[j]=x;
return j;
}
inline int Random(int p,int r)
{
return (p+(rand()%(r-p+)));//p=<x<=r
} int RandomPartition(int a[],int p,int r )
{
int i=Random(p,r);
Swap(a[i],a[p]);
return Partition(a,p,r);
} void QuickSort(int a[],int p,int r)
{
if (p<r)
{
int q=RandomPartition(a,p,r);
QuickSort(a,p,q-);
QuickSort(a,q+,r);
}
}
改进前:
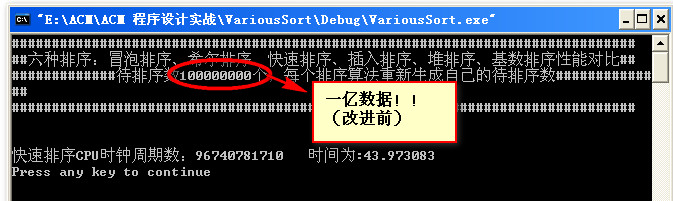
改进后:

小结:尼玛,这神马情况。这效率越改越低,哪位大侠有更好的改进方法可以交流一下。
3、接下来我重测一下排序英雄榜(昨天测的大家就当看笑话了O(∩_∩)O)
今天博友 Sam Xiao提供一种前所未见的排序算法(我称之为SomeoneSort算法),其效率之低让人叹为观止(感觉时间复杂度接近O(n!))!当然这里并没有嘲笑的意思,多一种方法,多一种思路学习一下都是不错的。拿出来和大家分享一下:
//从未见过效率如此低的排序算法
void SomeoneSort(int a[],int n)
{
//int count=0;
int i=;
while (i<n-)
{
if(a[i]>a[i+])
{
Swap(a[i],a[i+]);
i=;
//count++;
continue;
}
i++;
}
//cout<<count<<"次"<<endl;
}
下面拿SomeOneSort和BulbleSort对比一下:
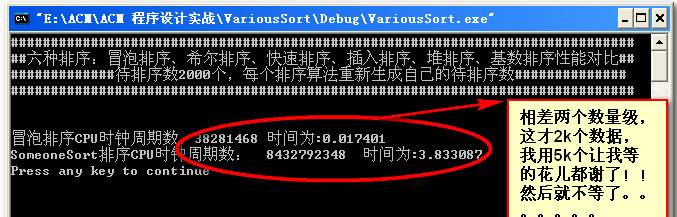
下面重新测一下昨天7个排序算法,具体改过的只有快速排序和希尔排序:
数据量1:

数据量10:
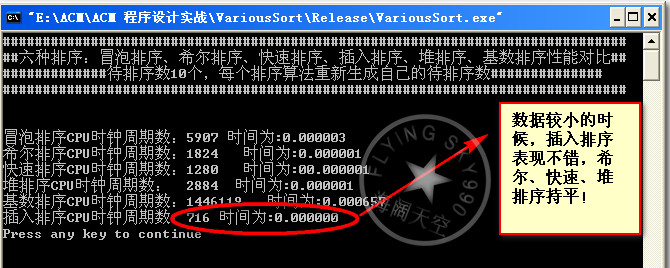
数据量100:
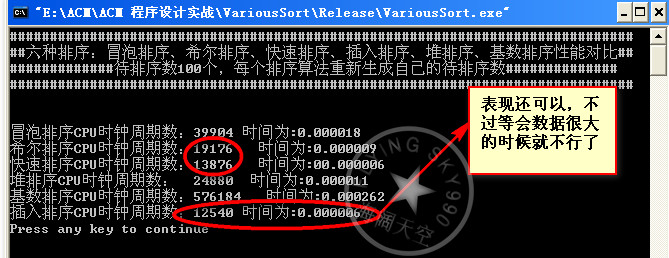
数据量1000:

数据量10000:
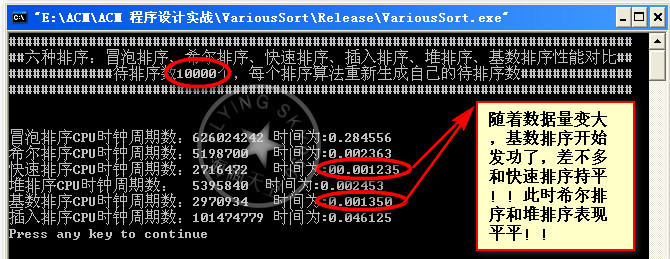
数据量50000:
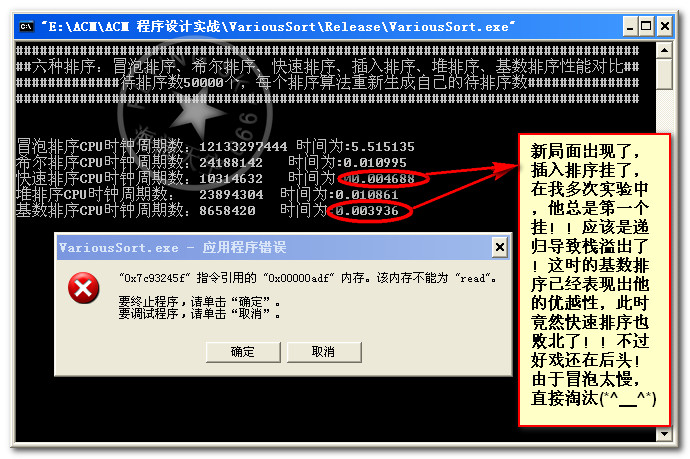
数据量100000:
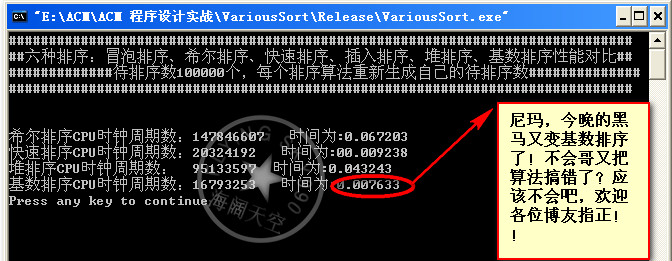
数据量200000:
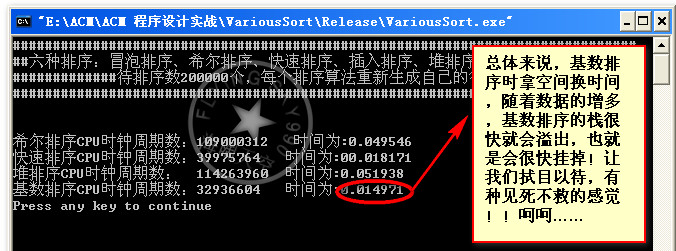
数据量300000:
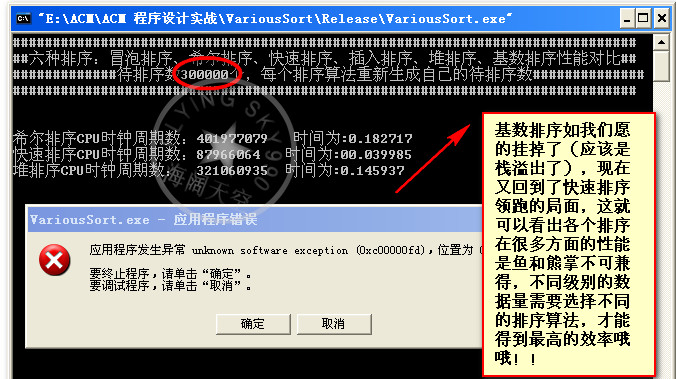
数据量1百万:

数据量1千万:
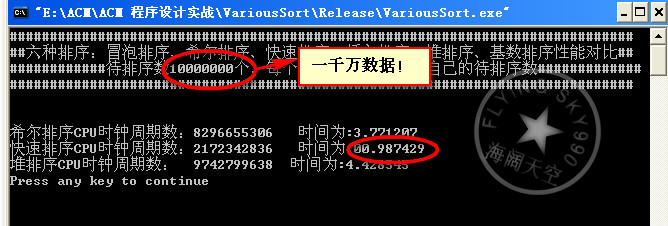
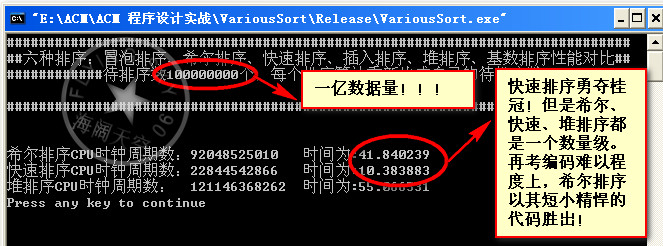
数据量1亿:
数据量5亿:

数据量5亿:


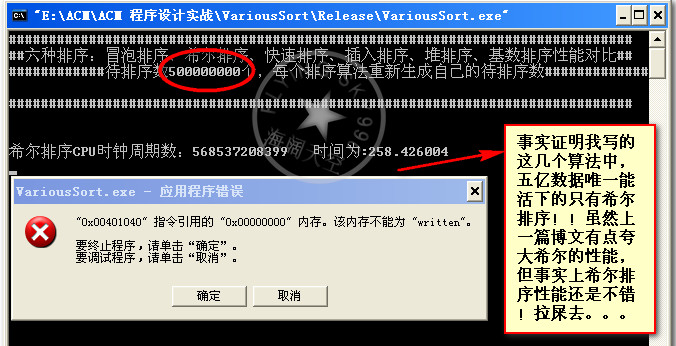
数据量5.2亿:
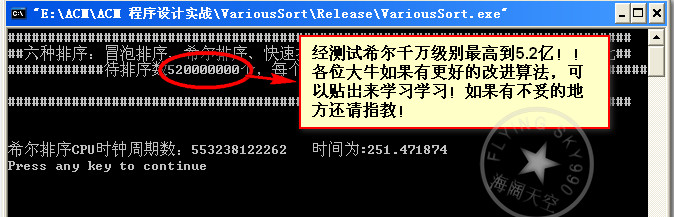
总结:昨天和今天两天啥事没干就是在测试这些算法,收获很多。首先算法的好坏不能一概而论,得看具体情况。具体情况就是指待排的数据量,和你能承受的内存空间。比如基数排序在数据量在1w~20w之间 高于快速排序,但是这是需要空间作为代价的。30w后基数排序就挂,当然这可能和我的编码有关。但是从总体性能来说,应该是满足这一规律的,快速排序一路测下来确实表现的很好,但是在代码的健壮性方面可能不及希尔排序,就效率将希尔排序和快速排序是一个数量级上的当然我得承认这些排序代码我并没有真正用于实际的项目中,往往只是对付笔试和面试。本人小本科一枚,最近忙着找工作,所以遇到了就在复习复习。真正用于项目中肯定还有许多需要优化和改进的地方。或者是组合多种排序算法,使之成为一个更复杂效率更高的算法。读书读到现在大家应该知道,生活中、学习中、工作中、以至于我们搞算法、计算机安全领域。最好的接解决方案无非是根据实际情况各种因素的权衡,把手中的的多套方案进行妥协和折中,找一个最佳的平衡点。
很快自己也要走进社会了,就像刚刚进入大学前的一段时间,心中满是憧憬和期待,即便别人说社会是怎样怎样的复杂和现实。有的时候甚至会在想工作的第一个月的工资要干什么?好期待第一月的工资,其实我已经计划好了,O(∩_∩)O哈哈~。回顾大学的这将近四年。让我改变最大的还是我的思想,我觉得这也是最宝贵的,有为人处世方面的,也有学习方法方面的,至少现在我的自学能力比以前提高了不知道多少!基本上遇到的技术问题在互联网和图书管总能找到或多或少都能找到答案,当然我们要珍惜老师上课的时光,我觉得那是学习知识最快的方式。这一个多月来我学习的积极性是如此的高,从未有过!我的舍友们也是,我们老是开玩笑说“要是大一就有现在的思想我早就怎么怎么了……”,如果你还不用面临毕业,那么以半个过来人的身份告诉你“好好地学习,好好学习一门你感兴趣的技术,如果你不确定你对什么感兴趣你可以找一个你不至于讨厌的先学一学,慢慢发现你是否喜欢这个”根据我的经验你有足够时间尝试这样三次左右,当然这后最好找一个你感兴趣的领域好好的学习。切记不可三天打鱼两晒网,因为如果你手中掌握一门技能对你以后找工作是有很大好处的。作为一名很菜的“程序猿”,我必须明白与时俱进的学习新知识才能不断提高我的生产力。也才有能力养活自己,养活自己的家庭以及以后年迈的父母。大家一起加油!!!(很明显跑题了!!O(∩_∩)O哈哈~)
有不妥的地方欢迎大家指正!!共同学习!!
最后声明一点:快速排序还是希尔排序他爹!!
推荐一段博友分享的排序视频很艺术、很形象、很生动哦(http://www.oschina.net/question/561584_65522)
浅谈C++之冒泡排序、希尔排序、快速排序、插入排序、堆排序、基数排序性能对比分析之后续补充说明(有图有真相)的更多相关文章
- 数组排序-冒泡排序-选择排序-插入排序-希尔排序-快速排序-Java实现
这五种排序算法难度依次增加. 冒泡排序: 第一次将数组相邻两个元素依次比较,然后将大的元素往后移,像冒泡一样,最终最大的元素被移到数组的最末尾. 第二次将数组的前n-1个元素取出,然后相邻两个元素依次 ...
- 虚拟化构建二分图(BZOJ2080 题解+浅谈几道双栈排序思想的题)
虚拟化构建二分图 ------BZOJ2080 题解+浅谈几道双栈排序思想的题 本题的题解在最下面↓↓↓ 不得不说,第一次接触类似于双栈排序的这种题,是在BZOJ的五月月赛上. [BZOJ4881][ ...
- <算法基础><排序>三种高级排序——快速排序,堆排序,归并排序
这三种排序算法的性能比较如下: 排序名称 时间复杂度(平均) 时间复杂度(最坏) 辅助空间 稳定性 快速排序 O(nlogn) O(n*n) O(nlogn) 不稳定 堆排序 O(nlogn) O(n ...
- 浅谈VC++中预编译的头文件放那里的问题分析
用C++写程序,肯定要用预编译头文件,就是那个stdafx.h.不过我一直以为只要在.cpp文件中包含stdafx.h 就使用了预编译头文件,其实不对.在VC++中,预编译头文件是指放到stdafx. ...
- 浅谈Linux下各种压缩 解压命令和压缩比率对比
Linux下压缩.解压命令五花八门,不像在windows下一个winrar打遍天下无敌手,清一色的.rar .zip格式. 比如,Linux下常用的tar tar.gz tar.bz2 .Z等等不一而 ...
- Python中排序函数sorted和排序方法sort的异同点对比分析
Python中对序列进行排序有两种方法,一种是使用python内置的全局sorted函数,另一种是使用序列内置的sort方法. 一. 两者相同点 在支持sort方法的序列中都可以对序列进行排序: 二者 ...
- Python实现八大排序(基数排序、归并排序、堆排序、简单选择排序、直接插入排序、希尔排序、快速排序、冒泡排序)
目录 八大排序 基数排序 归并排序 堆排序 简单选择排序 直接插入排序 希尔排序 快速排序 冒泡排序 时间测试 八大排序 大概了解了一下八大排序,发现排序方法的难易程度相差很多,相应的,他们计算同一列 ...
- 算法与数据结构(十三) 冒泡排序、插入排序、希尔排序、选择排序(Swift3.0版)
本篇博客中的代码实现依然采用Swift3.0来实现.在前几篇博客连续的介绍了关于查找的相关内容, 大约包括线性数据结构的顺序查找.折半查找.插值查找.Fibonacci查找,还包括数结构的二叉排序树以 ...
- C语言实现 冒泡排序 选择排序 希尔排序
// 冒泡排序 // 选择排序 // 希尔排序 // 快速排序 // 递归排序 // 堆排序 #define _CRT_SECURE_NO_WARNINGS #include <stdio.h& ...
随机推荐
- [转]OAuth 2.0 - Authorization Code授权方式详解
本文转自:http://www.cnblogs.com/highend/archive/2012/07/06/oautn2_authorization_code.html I:OAuth 2.0 开发 ...
- 最长不下降序列nlogn算法
显然n方算法在比赛中是没有什么用的(不会这么容易就过的),所以nlogn的算法尤为重要. 分析: 开2个数组,一个a记原数,f[k]表示长度为f的不下降子序列末尾元素的最小值,tot表示当前已知的最长 ...
- [原]CentOS7部署osm2pgsql
转载请注明原作者(think8848)和出处(http://think8848.cnblogs.com) 部署Postgresql和部署PostGis请参考前两篇文章 本文主要参考GitHub上osm ...
- [LeetCode] Optimal Account Balancing 最优账户平衡
A group of friends went on holiday and sometimes lent each other money. For example, Alice paid for ...
- [LeetCode] Divide Two Integers 两数相除
Divide two integers without using multiplication, division and mod operator. If it is overflow, retu ...
- redis学习笔记
Redis 命令 Redis 命令用于在 redis 服务上执行操作. 要在 redis 服务上执行命令需要一个 redis 客户端.Redis 客户端在我们之前下载的的 redis 的安装包中. 语 ...
- sql 代码笔记
1. if() 函数 推荐一个学习MySQL的网站 Study MySql
- Java实现多种方式的http数据抓取
前言: 时下互联网第一波的浪潮已消逝,随着而来的基于万千数据的物联网时代,因而数据成为企业的重要战略资源之一.基于数据抓取技术,本文介绍了java相关抓取工具,并附上demo源码供感兴趣的朋友测试! ...
- nginx代理TCP端口
1.升级nginx 版本至1.9.0以上 升级流程参考 nginx平滑升级 2.配置编译的时候需要加上 ./configure --prefix=/usr/local/nginx --user=www ...
- 阿里云免费申请免费SSL证书
随着互联网的不断进步与发展,对于网站与数据的安全性要求也越来越高,原本的HTTP明文传输已经不被信任,https逐渐被关注,从谷歌.火狐浏览器将对HTTP明文页面标记"不安全",到 ...