Pandas数据去重和对重复数据分类、求和,得到未重复和重复(求和后)的数据
人的理想志向往往和他的能力成正比。 —— 约翰逊
其实整个需求呢,就是题目。2018-08-16
需求的结构图:
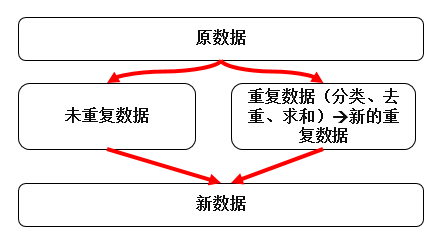
涉及的包有:pandas、numpy
1、导入包:
import pandas as pd
import numpy as np
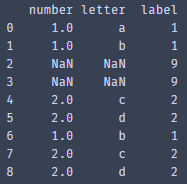
2、构造DataFrame,里面包含三种数据类型:int、null、str
data = {"number":[1,1,np.nan,np.nan,2,2,1,2,2],
"letter":['a','b',np.nan,np.nan,'c','d','b','c','d'],
"label":[1,1,9,9,2,2,1,2,2]}
dataset1 = pd.DataFrame(data) #初始化DataFrame 得到数据集dataset1
print(dataset1)
3、空值填充
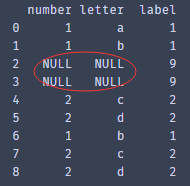
由于数据集里含有空值,为了能够对后面重复数据进行求和,则需要对空值进行填充
dataset = dataset1.fillna("NULL")
print(dataset)
4、利用duplicated()函数和drop_duplicates()函数对数据去重
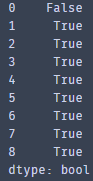
首先,利用duplicated()函数按列名'letter'和' number '取重复行,其返回的是bool类型,若为重复行则true,反之为false
duplicate_row = dataset.duplicated(subset=['letter',' number '],keep=False)
print(duplicate_row)
然后通过bool值取出重复行的数据
duplicate_data = dataset.loc[duplicate_row,:]
print(duplicate_data)
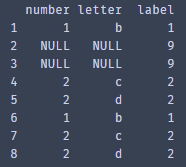
再然后根据'letter',' number '对重复数据进行分类,在该前提下并对重复数据的’label’进行求和,且重置索引(对后文中的赋值操作有帮助)
duplicate_data_sum = duplicate_data.groupby(by=['letter',' number ']).agg({' label ':sum}).reset_index(drop=True)
Print(duplicate_data_sum)

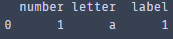
取出重复数据中的一个,例如:1,1,2,2——>1,2
对drop_duplicates指定列:subset=['letter',' number '],保留第一条重复的数据:keep="first"
duplicate_data _one= duplicate_data.drop_duplicates(subset=['letter',' number '] ,keep="first").reset_index(drop=True)
Print(duplicate_data)
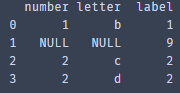
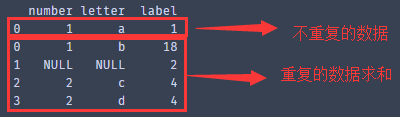
获取不重复的数据,指定列subset=['letter',' number ',' label '],不保留重复数据:keep=False
no_duplicate = dataset.drop_duplicates(subset=['letter',' number ',' label '] ,keep=False)
Print(no_duplicate)
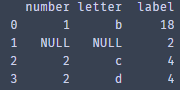
将对重复值的’label’求和,并赋值给“重复值中的一个”,得到新的”新重复值中的一个
duplicate_data _one ["label"] = duplicate_data_sum ['label'] #前面需要重置索引
print(duplicate_data_one)
最后,拼接”新重复值中的一个”和不重复的数据
Result = pd.concat([no_duplicate,duplicate_data _one])
Print(result)
5、全体代码:
import pandas as pd
import numpy as np #构造DataFrame
data = {"number":[1,1,np.nan,np.nan,2,2,1,2,2],
"letter":['a','b',np.nan,np.nan,'c','d','b','c','d'],
"label":[1,1,9,9,2,2,1,2,2]}
dataset1 = pd.DataFrame(data) #空值填充
dataset = dataset1.fillna("NULL")
#得到重复行的索引
duplicate_row = dataset.duplicated(subset=['letter','number'],keep=False)
#得到重复行的数据
duplicate_data = dataset.loc[duplicate_row,:]
#重复行按''label''求和
duplicate_data_sum = duplicate_data.groupby(by=['letter','number']).agg({'label':sum}).reset_index(drop=True) #得到唯一的重复数据
duplicate_data_one= duplicate_data.drop_duplicates(subset=[
'letter','number'],keep="first").reset_index(drop=True)
#获得不重复的数据
no_duplicate = dataset.drop_duplicates(subset=['letter','number','label']
,keep=False)
#把重复行按"label"列求和的"label"列赋值给唯一的重复数据的"label"列
duplicate_data_one ["label"] = duplicate_data_sum ['label']
Result = pd.concat([no_duplicate,duplicate_data_one]
主要用到几个关键的函数:
Pandas.concat()
DataFrame.duplicated()
DataFrame.drop_duplicates().reset_index(drop=True)
DataFrame.groupby().agg({})
本人处于学习中,如有写的不够专业或者错误的地方,诚心希望各位读者多多指出!!
Pandas数据去重和对重复数据分类、求和,得到未重复和重复(求和后)的数据的更多相关文章
- [Hadoop]-从数据去重认识MapReduce
这学期刚好开了一门大数据的课,就是完完全全简简单单的介绍的那种,然后就接触到这里面最被人熟知的Hadoop了.看了官网的教程[吐槽一下,果然英语还是很重要!],嗯啊,一知半解地搭建了本地和伪分布式的, ...
- 利用MapReduce实现数据去重
数据去重主要是为了利用并行化的思想对数据进行有意义的筛选. 统计大数据集上的数据种类个数.从网站日志中计算访问地等这些看似庞杂的任务都会涉及数据去重. 示例文件内容: 此处应有示例文件 设计思路 数据 ...
- mySql数据重复数据去重
1.问题来源:数据中由于并发问题,数据存在多次调用接口,插入了重复数据,需要根据多条件删除重复数据: 2.参考博客文章地址:https://www.cnblogs.com/jiangxiaobo/p/ ...
- pandas-22 数据去重处理
pandas-22 数据去重处理 数据去重可以使用duplicated()和drop_duplicates()两个方法. DataFrame.duplicated(subset = None,keep ...
- map/reduce实现数据去重
import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.co ...
- MYSQL数据去重与外表填充
经常要对数据库中的数据进行去重,有时还需要使用外部表填冲数据,本文档记录数据去重与外表填充数据. date:2016/8/17 author:wangxl 1 需求 对user_info1表去重,并添 ...
- EXCEL技能之数据去重
本篇不属于技术类博文,只是想找个地方记录而已,既然是我的博客嘛,那就自己想写什么就写什么了. CRM中有个EXCEL数据导入功能,几千条数据导入CRM后去重,那是死的心都有的.往回想想EXCEL是否有 ...
- Oracle 分页查询与数据去重
1.rownum字段 Oracle下select语句每个结果集中都有一个伪字段(伪列)rownum存在.rownum用来标识每条记录的行号,行号从1开始,每次递增1.rownum是虚拟的顺序值,前提是 ...
- mssql sqlserver 三种数据表数据去重方法分享
摘要: 下文将分享三种不同的数据去重方法数据去重:需根据某一字段来界定,当此字段出现大于一行记录时,我们就界定为此行数据存在重复. 数据去重方法1: 当表中最在最大流水号时候,我们可以通过关联的方式为 ...
随机推荐
- git撤销commit 并保存之前的修改
撤销并保留修改 参数 –soft # 先进行commit ,之后后悔啦 $ git commit -am "对首篇报告研究员字段改为author_name" 执行git log ...
- JDBC数据库
JDBC是Java程序连接和存取数据库的应用程序接口(API),包括两个包:java.sql和javax.sql. 用JDBC访问数据库的一般步骤: 1.建立数据源 2.装入JDBC驱动程序:使用Cl ...
- Eclipse的application.properties文件输出中文成unicode编码
今天添application.properties时,无法输入中文,输入的中文直接变成了unicode的编码形式.原因是Eclipse的Spring Properties文件的默认编码为iso-885 ...
- 学习笔记----html的lang属性
lang属性的取值应该遵循 BCP 47 - Tags for Identifying Languages. 单一的 zh 和 zh-CN 均属于废弃用法. 问题主要在于,zh 现在不是语言code了 ...
- Readme.txt
进入大学,越来越发现自学确实很重要,在学习计算机上,老师上课讲的远远不够,光凭理论是不够的.第一个接触的是VC++6.0这个老版的软件,一节理论课可以过三章内容着实惊吓,现在发现Vscode 可以将代 ...
- CentOS5.5 - lnmp环境安装与使用
CentOS5.5 - lnmp环境安装与使用 到公司搭建环境可以直接使用YUM. 安装一.rpm包安装(安装方便) yum:下载软件包并且安装.前提:连网. yum 使用流程: 1. yum lis ...
- Android学习笔记(1):常用按钮点击事件处理方式
1.从布局文件获取对应的控件然后对其添加点击监听器. Button loginBtn; @Override protected void onCreate(Bundle savedInstanceSt ...
- Azure Active Directory document ---reading notes
微软利用本地活动目录 Windows Server Active Directory 进行身份认证管理方面具有丰富的经验,现在这一优势已延伸基于云平台的Azure Active Directory.可 ...
- CS61A Lecture3 Note
本次lec主讲控制流 本文档只列一些py控制流与C不同的地方 print的功能不同 可以print出来None这种东西 重点讲了函数运行机制,我的理解是这样的,在调用函数之前,def会产生一个glo ...
- CLion之C++框架篇-优化开源框架,引入curl,实现get方式获取资源(四)
背景 结合上一篇CLion之C++框架篇-优化框架,引入boost(三),继续进行框架优化!在项目中,我们经常会通过get方式拉取第三方资源,这一版优化引入类库curl,用来拉取第三方资源库. ...