Nginx的核心功能及应用实战
反向代理功能及配置:
反向代理(Reverse Proxy)方式是指以代理服务器来接受 internet 上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一个反向代理服务器。
nginx反向代理的指令不需要新增额外的模块,默认自带 proxy_pass 指令,只需要修改配置文件就可以实现反向代理。proxy_pass 既可以是ip地址,也可以是域名,同时还可以指定端口,配置如下:
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://192.168.254.139:8080; // 代理服务器的地址
proxy_set_header X-Real-IP $remote_addr; // 设置客户端的真实IP
proxy_set_header Host $hoxt; //当后端web服务器也配置了多个虚拟主机时,需要用该header来区分反向代理哪个主机名
proxy_set_header X-Forwarded-For $remote_addr //如果后端web服务器上的程序需要获取用户ip,可以从该header头获取
proxy_next_upstream http_502 http_504 http_503 error timeout invalid_header; //请求出错后,转向下一个节点
proxy_set_header http_user_agent $http_user_agent; //判断访问端是苹果,安卓,win还是mac
#proxy_body_buffer_size 64k;//用于指定客户端请求主体缓冲区大小,可以理解为先保存到本地在传给用户
#proxy_connect_timeout 60s;//表示与后端服务器连接的超时时间,即发起握手等候响应的超时时间
#proxy_send_timeout 60s;//表示后端服务器的数据回传时间,即在规定的时间内后端服务器必须传完所有的数据,否则,nginx将断开这个连接
#proxy_read_timeout 60s;//设置nginx从代理的后端服务器获取信息的时间,表示连接建立成功之后,nginx等待后端服务器的响应时间,其实nginx已经进入后端的排队之中等候处理
#proxy_buffer_size 60k;//设置缓冲区大小,默认,该个、缓冲区大小等于指令proxy_buffers设置的大小
#proxy_buffers 60k;//设置缓冲区的数量和大小。nginx从代理的后端服务器获取的响应信息,会保存到缓冲区
#proxy_busy_buffers_size //用于设置系统忙碌时可以使用的proxy_buffers大小,官方推荐为proxy_buffers*2
#proxy_tmep_file_write_size //指定proxy缓存临时文件的大小
#add_header 'Access-Control-Allow-Origin' '*'; // 添加允许跨域头 允许来自所有的访问地址
#add_header 'Access-Control-Allow-Methods' 'GET,POST,DELETE'; // 支持的请求方式
#add_header 'Aceess-Control-Allow-Header' 'Content-Type,*'; // 支持的媒体类型
# ......
}
}
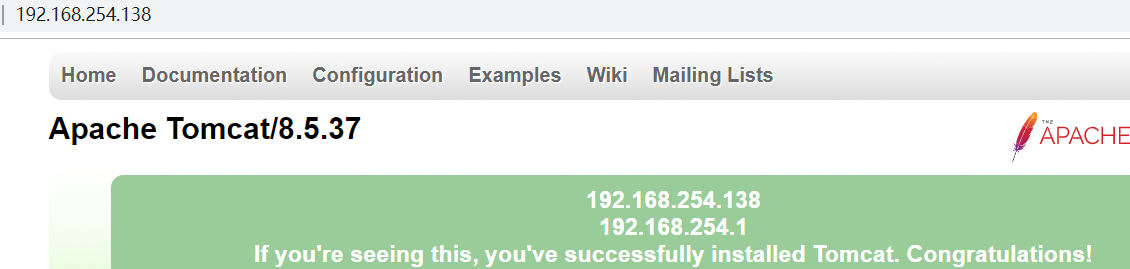
启动 139 服务器上面的 tomcat,通过192.168.254.138:80/ 来访问,便可以访问,为了更加直观,在 tomcat 的 jsp 主页上添加输出客户端的 IP以及header的一些信息:

访问后输出信息如下:说明这个反向代理成功了。
负载均衡功能及配置:
网络负载均衡的大致原理是利用一定的分配策略将网络负载平衡地分摊到网络集群的各个操作单元上,使得单个重负载任务能够分担到多个单元上并行处理,使得大量并发访问或数据流量分担到多个单元上分别处理,从而减少用户的等待响应时间。
upstream
是Nginx的HTTP Upstream模块,这个模块通过一个简单的调度算法来实现客户端IP到后端服务器的负载均衡。
1. Upstream
语法: server address [paramters]
2. 负载均衡策略或者算法
轮询(默认方式),weight权重方式,ip_hash:依据ip分配方式,least_conn最少连接方式,fair(第三方)响应时间方式,url_hash(第三方)依据URL分配方式。
1、轮询
最基本的配置方法,上面的例子就是轮询的方式,它是upstream模块默认的负载均衡默认策略。每个请求会按时间顺序逐一分配到不同的后端服务器。
有如下参数:
| fail_timeout | 与max_fails结合使用。 |
| max_fails |
设置在fail_timeout参数设置的时间内最大失败次数,如果在这个时间内,所有针对该服务器的请求都失败了,那么认为该服务器会被认为是停机了,
|
| fail_time | 服务器会被认为停机的时间长度,默认为10s。 |
| backup | 标记该服务器为备用服务器。当主服务器停止时,请求会被发送到它这里。 |
| down | 标记服务器永久停机了。 |
注意:
- 在轮询中,如果服务器down掉了,会自动剔除该服务器。
- 缺省配置就是轮询策略。
- 此策略适合服务器配置相当,无状态且短平快的服务使用。
2、weight
权重方式,在轮询策略的基础上指定轮询的几率。例子如下:
#动态服务器组
upstream dynamic_wuzz {
server 192.168.254.139:8080 weight=2;
server 192.168.254.139:8081;
server 192.168.254.139:8082 backup;
server 192.168.254.139:8083 max_fails=3 fail_timeout=20s;
}
接着在server大括号内找到location / {} 在里面加上如下代码。http:// 的域名和upstream 后面的域名保持一致。例如这里是:http://dynamic_wuzz
在该例子中,weight参数用于指定轮询几率,weight的默认值为1,;weight的数值与访问比率成正比,比如8080端口被访问的几率为其他服务器的两倍。
注意:
- 权重越高分配到需要处理的请求越多。
- 此策略可以与least_conn和ip_hash结合使用。
- 此策略比较适合服务器的硬件配置差别比较大的情况。
3、ip_hash
指定负载均衡器按照基于客户端IP的分配方式,这个方法确保了相同的客户端的请求一直发送到相同的服务器,以保证session会话。这样每个访客都固定访问一个后端服务器,可以解决session不能跨服务器的问题。
#动态服务器组
upstream dynamic_wuzz{
ip_hash; #保证每个访客固定访问一个后端服务器
server 192.168.254.139:8080 weight=2;
server 192.168.254.139:8081;
server 192.168.254.139:8082;
server 192.168.254.139:8083 max_fails=3 fail_timeout=20s;
}
注意:
- 在nginx版本1.3.1之前,不能在ip_hash中使用权重(weight)。
- ip_hash不能与backup同时使用。
- 此策略适合有状态服务,比如session。
- 当有服务器需要剔除,必须手动down掉。
4、least_conn
把请求转发给连接数较少的后端服务器。轮询算法是把请求平均的转发给各个后端,使它们的负载大致相同;但是,有些请求占用的时间很长,会导致其所在的后端负载较高。这种情况下,least_conn这种方式就可以达到更好的负载均衡效果。
#动态服务器组
upstream dynamic_wuzz{
least_conn; #把请求转发给连接数较少的后端服务器
server 192.168.254.139:8080 weight=2;
server 192.168.254.139:8081;
server 192.168.254.139:8082 backup;
server 192.168.254.139:8083 max_fails=3 fail_timeout=20s;
}
注意:
- 此负载均衡策略适合请求处理时间长短不一造成服务器过载的情况。
5、第三方策略
第三方的负载均衡策略的实现需要安装第三方插件。
按照服务器端的响应时间来分配请求,响应时间短的优先分配。
fair :
#动态服务器组
upstream dynamic_wuzz{
server 192.168.254.139:8080;
server 192.168.254.139:8081;
server 192.168.254.139:8082;
server 192.168.254.139:8083;
fair; #实现响应时间短的优先分配
}
url_hash:
按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,要配合缓存命中来使用。同一个资源多次请求,可能会到达不同的服务器上,导致不必要的多次下载,缓存命中率不高,以及一些资源时间的浪费。而使用url_hash,可以使得同一个url(也就是同一个资源请求)会到达同一台服务器,一旦缓存住了资源,再此收到请求,就可以从缓存中读取。
#动态服务器组
upstream dynamic_wuzz{
hash $request_uri; #实现每个url定向到同一个后端服务器
server 192.168.254.139:8080;
server 192.168.254.139:8081;
server 192.168.254.139:8082;
server 192.168.254.139:8083;
}
以上便是6种负载均衡策略的实现方式,其中除了轮询和轮询权重外,都是Nginx根据不同的算法实现的。在实际运用中,需要根据不同的场景选择性运用,大都是多种策略结合使用以达到实际需求。
动静分离:
必须依赖服务器生存的我们称为动。不需要依赖容器的比如css/js或者图片等,这类就叫静态资源。
在Nginx的conf目录下,有一个mime.types文件用户访问一个网站,然后从服务器端获取相应的资源通过浏览器进行解析渲染最后展示给用户,而服务端可以返回各种类型的内容,比如xml、jpg、png、gif、flash、MP4、html、css等等,那么浏览器就是根据mime-type来决定用什么形式来展示的服务器返回的资源给到浏览器时,会把媒体类型告知浏览器,这个告知的标识就是Content-Type,比如ContentType:text/html。
location ~ .*\.(js|css|png|svg|jpg|...)$ { // 将需要的静态文件类型配置好
root static-resource; // 静态文件访问目录
}
这里注意需要打开该文件夹的权限,不然访问不到 chmod -R 777 static-resource/。
动静分离的好处:
第一个,Nginx本身就是一个高性能的静态web服务器;
第二个,其实静态文件有一个特点就是基本上变化不大,所以动静分离以后我们可以对静态文件进行缓存、或者压缩提高网站性能。
Nginx缓存配置:
当一个客户端请求web服务器, 请求的内容可以从以下几个地方获取:服务器、浏览器缓存中或缓存服务器中。这取决于服务器端输出的页面信息,浏览器缓存将文件保存在客户端,好的缓存策略可以减少对网络带宽的占用,可以提高访问速度,提高用户的体验,还可以减轻服务器的负担。
nginx缓存配置:
Nginx可以通过expires设置缓存,比如我们可以针对图片做缓存,因为图片这类信息基本上不会改变。在location中设置expires。格式: expires 30s|m|h|d 。
location ~ .*\.(js|css|png|svg|jpg|...)$ { // 将需要的静态文件类型配置好
root static-resource; // 静态文件访问目录
expires 1d;
}
压缩:
我们一个网站一定会包含很多的静态文件,比如图片、脚本、样式等等,而这些css/js可能本身会比较大,那么在网络传输的时候就会比较慢,从而导致网站的渲染速度。因此Nginx中提供了一种Gzip的压缩优化手段,可以对后端的文件进行压缩传输,压缩以后的好处在于能够降低文件的大小来提高传输效率。
配置信息:
Gzip on|off 是否开启gzip压缩
Gzip_buffers 4 16k; #设置gzip申请内存的大小,作用是按指定大小的倍数申请内存空间。4 16k代表按照原始数据大小以16k为单位的4倍申请内存。
Gzip_comp_level[1-9] 压缩级别, 级别越高,压缩越小,但是会占用CPU资源
Gzip_disable #正则匹配UA 表示什么样的浏览器不进行gzip
Gzip_min_length #开始压缩的最小长度(小于多少就不做压缩),可以指定单位,比如 1k
Gzip_http_version 1.0|1.1 表示开始压缩的http协议版本
Gzip_proxied (nginx 做前端代理时启用该选项,表示无论后端服务器的headers头返回什么信息,都无条件启用压缩)
Gzip_types text/pliain application/xml; 对那些类型的文件做压缩 (conf/mime.conf)
Gzip_vary on|off 是否传输gzip压缩标识; 启用应答头"Vary: Accept-Encoding";给代理服务器用的,有的浏览器支持压缩,有的不支持,所以避免浪费不支持的也压缩,所以根据客户端的HTTP头来判断,是否需要压缩
实际配置:
http {
gzip on;
gzip_min_length 5k;
gzip_comp_level 3;
gzip_types application/javascript image/jpeg image/svg+xml;
gzip_buffers 4 32k;
gzip_vary on;
}
防盗链配置:
一个网站上会有很多的图片,如果你不希望其他网站直接用你的图片地址访问自己的图片,或者希望对图片有版权保护。再或者不希望被第三方调用造成服务器的负载以及消耗比较多的流量问题,那么防盗链就是你必须要做的。
在Nginx中配置防盗链其实很简单,
语法: valid_referers none | blocked | server_names | string ...; 默认值: 1
上下文: server, location
“Referer”请求头为指定值时,内嵌变量$invalid_referer被设置为空字符串,否则这个变量会被置成“1”。查找匹配时不区分大小写,其中none表示缺少referer请求头、blocked表示请求头存在,但是它的值被防火墙或者代理服务器删除、server_names表示referer请求头包含指定的虚拟主机名.
1. 配置如下:
location ~ .*\.(js|css|png|svg|jpg)$ {
valid_referers none blocked 192.168.254.138;
if ($invalid_referer) {
return 404;
}
root static-resource;
index tomcat.png;
expires 1d;
}
需要注意的是伪造一个有效的“Referer”请求头是相当容易的,因此这个模块的预期目的不在于彻底地阻止这些非法请求,而是为了阻止由正常浏览器发出的大规模此类请求。还有一点需要注意,即使正常浏览器发送的合法请求,也可能没有“Referer”请求头。
限流 Limit_req 模块:
限制时间窗口内的平均速率,nginx中该模块的使用配置示例:
imit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;
server {
location /{
limit_req zone=one burst= nodelay;
}
第一段配置参数:
- $binary_remote_addr :表示通过remote_addr这个标识来做限制,“binary_”的目的是缩写内存占用量,是限制同一客户端ip地址
- zone=one:10m:表示生成一个大小为10M,名字为one的内存区域,用来存储访问的频次信息
- rate=1r/s:表示允许相同标识的客户端的访问频次,这里限制的是每秒1次,即每秒只处理一个请求,还可以有比如30r/m的,即限制每2秒访问一次,即每2秒才处理一个请求。
- zone=one :设置使用哪个配置区域来做限制,与上面limit_req_zone 里的name对应
- burst=5:重点说明一下这个配置,burst爆发的意思,这个配置的意思是设置一个大小为5的缓冲区当有大量请求(爆发)过来时,超过了访问频次限制的请求可以先放到这个缓冲区内等待,但是这个等待区里的位置只有5个,超过的请求会直接报503的错误然后返回。
- nodelay:如果设置,会在瞬时提供处理(burst + rate)个请求的能力,请求超过(burst + rate)的时候就会直接返回503,永远不存在请求需要等待的情况。(这里的rate的单位是:r/s)如果没有设置,则所有请求会依次等待排队
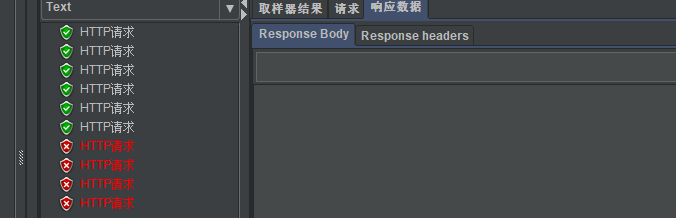
以上设置用10并发数压测出来:
设置每个IP的最大连接数:
http {
limit_conn_zone $binary_remote_addr zone=addr:5m;
server {
listen ;
server_name localhost;
location / {
limit_conn addr ;
limit_rate_after 3m;
limit_rate 512k;
}
}
}
limit_conn_zone $binary_remote_addr zone=addr:5m:
设置用于保存各种 key(比如当前连接数)的共享内存的参数。 5m 就是 5兆字节,这个值应该被设置的足够大以存储(32K*5) 32byte 状态或者(16K*5) 64byte 状态。
Nginx的核心功能及应用实战的更多相关文章
- Nginx(二)--nginx的核心功能
反向代理 nginx反向代理的指令不需要新增额外的模块,默认自带proxy_pass指令,只需要修改配置文件就可以实现反向代理. proxy_pass 既可以是ip地址,也可以是域名,同时还可以指定端 ...
- Shiro 核心功能案例讲解 基于SpringBoot 有源码
Shiro 核心功能案例讲解 基于SpringBoot 有源码 从实战中学习Shiro的用法.本章使用SpringBoot快速搭建项目.整合SiteMesh框架布局页面.整合Shiro框架实现用身份认 ...
- nginx高性能WEB服务器系列之五--实战项目线上nginx多站点配置
nginx系列友情链接:nginx高性能WEB服务器系列之一简介及安装https://www.cnblogs.com/maxtgood/p/9597596.htmlnginx高性能WEB服务器系列之二 ...
- 启动Nginx目录浏览功能及 让用户通过用户名密码认证访问web站点
一.启动Nginx目录浏览功能 [root@abcdocker extra]# cat w.conf server { listen 80; server_name IP地址; location / ...
- 带连接池的netty客户端核心功能实现剖解
带连接池的netty客户端核心功能实现剖析 带连接池的netty的客户端核心功能实现剖析 本文为原创,转载请注明出处 源码地址: https://github.com/zhangxianwu/ligh ...
- Chrome扩展开发之四——核心功能的实现思路
目录: 0.Chrome扩展开发(Gmail附件管理助手)系列之〇——概述 1.Chrome扩展开发之一——Chrome扩展的文件结构 2.Chrome扩展开发之二——Chrome扩展中脚本的运行机制 ...
- ES6,ES2105核心功能一览,js新特性详解
ES6,ES2105核心功能一览,js新特性详解 过去几年 JavaScript 发生了很大的变化.ES6(ECMAScript 6.ES2105)是 JavaScript 语言的新标准,2015 年 ...
- discuz论坛apache日志hadoop大数据分析项目:清洗数据核心功能解说及代码实现
discuz论坛apache日志hadoop大数据分析项目:清洗数据核心功能解说及代码实现http://www.aboutyun.com/thread-8637-1-1.html(出处: about云 ...
- k8s 核心功能 - 每天5分钟玩转 Docker 容器技术(116)
本节带领大家快速体验 k8s 的核心功能:应用部署.访问.Scale Up/Down 以及滚动更新. 部署应用 执行命令: kubectl run kubernetes-bootcamp \ --im ...
随机推荐
- 缓存设计(cache-design)
分布式缓存设计 目前常见的缓存方案都是分层缓存,通常可以分为以下几层: 1.1NG本地缓存,命中的话直接返回 1.2 NG没有命中时则需要查询分布式缓存,如redis 1.3 如果分布式缓存没有命中则 ...
- 【译】第八篇 SQL Server安全数据加密
本篇文章是SQL Server安全系列的第八篇,详细内容请参考原文. Relational databases are used in an amazing variety of applicatio ...
- android矩阵详解
android矩阵:http://www.360doc.com/content/11/1215/11/7635_172396706.shtml
- Setup Mission End
编写FPSGameMode 新建函数OnMissionComplete,并设置为蓝图可实现事件 UFUNCTION(BlueprintImplementableEvent,Category=" ...
- SpringBoot+BootStrap多文件上传到本地
1.application.yml文件配置 # 文件大小 MB必须大写 # maxFileSize 是单个文件大小 # maxRequestSize是设置总上传的数据大小 spring: servle ...
- pytorch1.0 用torch script导出模型
python的易上手和pytorch的动态图特性,使得pytorch在学术研究中越来越受欢迎,但在生产环境,碍于python的GIL等特性,可能达不到高并发.低延迟的要求,存在需要用c++接口的情况. ...
- [转] 如何轻松愉快地理解条件随机场(CRF)?
原文链接:https://www.jianshu.com/p/55755fc649b1 如何轻松愉快地理解条件随机场(CRF)? 理解条件随机场最好的办法就是用一个现实的例子来说明它.但是目前中文 ...
- bug笔记(pc)
1.如果a标签中的href没有设置,那么点击的这个按钮的时候,这个页面会自动刷新!!! Bug: <a href=”” class=”btn”></a>类似这种情况,点击a ...
- shell 不使用循环批量创建用户
..}|tr " " "\n"|awk '{print "useradd",$0,";date +%N|md5sum|cut -c ...
- Matlab调用C程序
Matlab调用C程序 复制来自https://blog.csdn.net/u010839382/article/details/42463237 Matlab是矩阵语言,如果运算可以用矩阵实现, ...