rancher使用fluentd-pilot收集日志分享
fluentd-pilot简介
fluentd-pilot是阿里开源的docker日志收集工具,Github项目地址:https://github.com/AliyunContainerService/fluentd-pilot 。你可以在每台机器上部署一个fluentd-pilot实例,就可以收集机器上所有Docker应用日志。
fluentd-pilot 具有如下特性:
- 一个单独的 fluentd 进程收集机器上所有容器的日志。不需要为每个容器启动一个 fluentd 进程。
- 支持文件日志和 stdout。docker log dirver 亦或 logspout 只能处理 stdout,fluentd-pilot 不仅支持收集 stdout 日志,还可以收集文件日志。
- 声明式配置。当您的容器有日志要收集,只要通过 label 声明要收集的日志文件的路径,无需改动其他任何配置,fluentd-pilot 就会自动收集新容器的日志。
- 支持多种日志存储方式。无论是强大的阿里云日志服务,还是比较流行的 elasticsearch 组合,甚至是 graylog,fluentd-pilot 都能把日志投递到正确的地点。
rancher使用fluentd-pilot收集日志
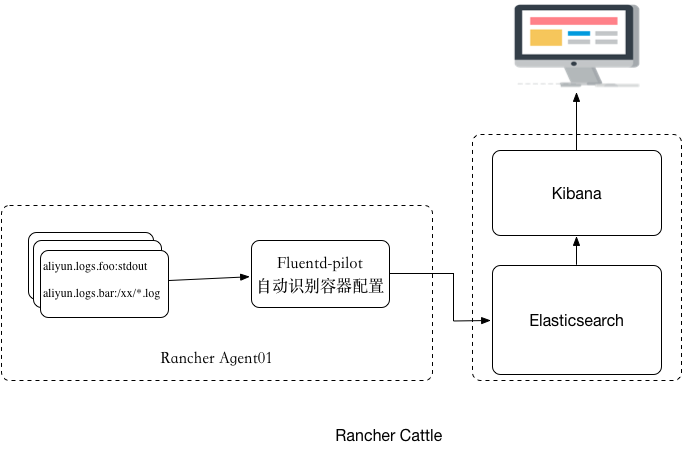
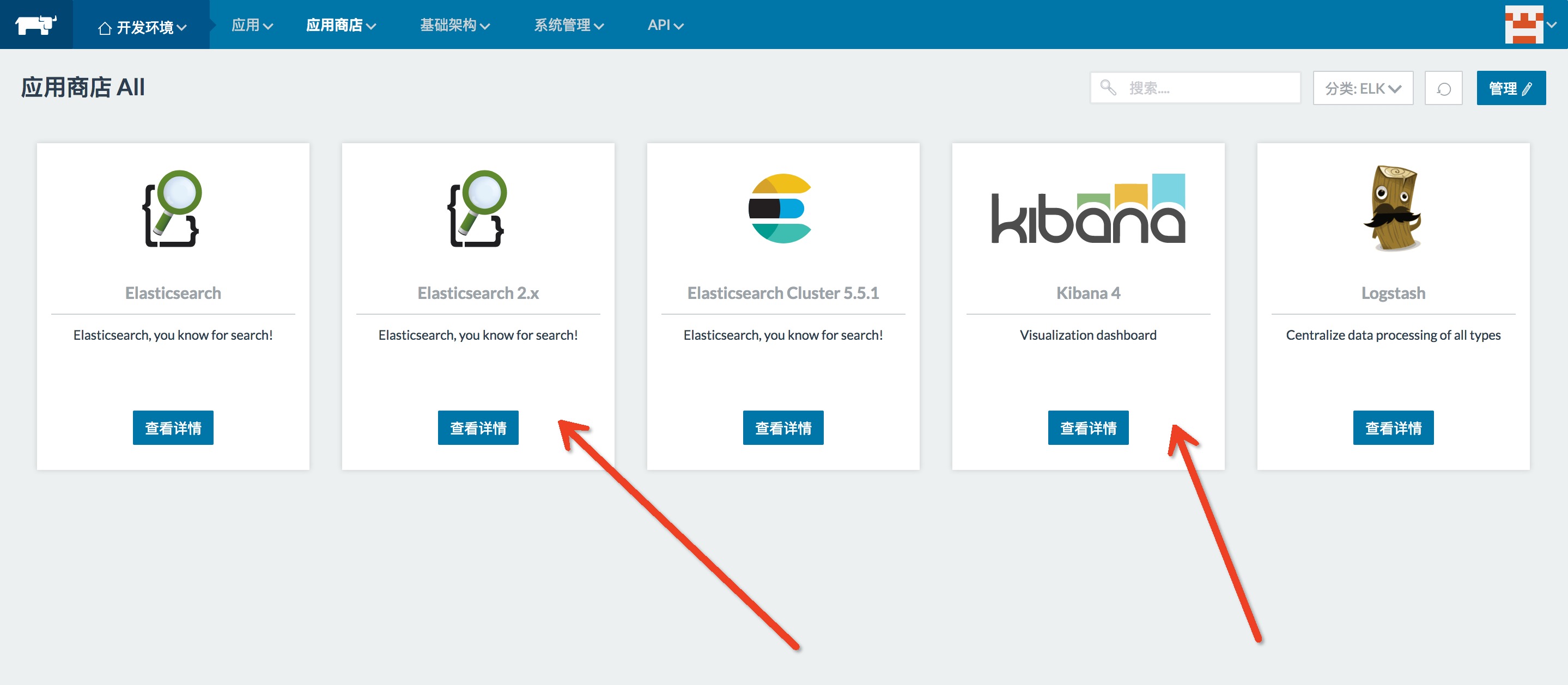
我们既然要用fluentd-pilot,就得先把它启动起来。还要有一个日志系统,日志要集中收集,必然要有一个中间服务去收集和存储,所以要先把这种东西准备好。Rancher中我们要如何做?如图,首先我们选择Rancher的应用商店中的Elasticsearch和Kibana。版本没有要求,下面使用Elasticsearch2.X和Kibana4。
其次在RancherAgent主机上面部署一个fluentd-pilot容器,然后在容器里面启动的时候,我们要声明容器的日志信息,fluentd-pilot会自动感知所有容器的配置。每次启动容器或者删除容器的时候,它能够看得到,当看到容器有新容器产生之后,它就会自动给新容器按照你的配置生成对应的配置文件,然后去采集,最后采集回来的日志同样也会根据配置发送到后端存储里面去,这里面后端主要指的elasticsearch或者是SLS这样的系统,接下来你可以在这个系统上面用一些工具来查询等等。
可根据实际情况,在每台Agent定义主机标签,通过主机标签在每台RancherAgent主机上跑一个pilot容器。用这个命令来部署,其实现在它是一个标准的Docker镜像,内部支持一些后端存储,可以通过环境变量来指定日志放到哪儿去,这样的配置方式会把所有的收集到的日志全部都发送到elasticsearch里面去,当然两个挂载是需要的,因为它连接Docker,要感知到Docker里面所有容器的变化,它要通过这种方式来访问宿主机的一些信息。在Rancher环境下使用以下docker-compose.yml 应用---->添加应用,在可选docker-compose.yml中添加一下内容。
version: ''
services:
pilot:
image: registry.cn-hangzhou.aliyuncs.com/acs-sample/fluentd-pilot:0.1
environment:
ELASTICSEARCH_HOST: elasticsearch
ELASTICSEARCH_PORT: ''
FLUENTD_OUTPUT: elasticsearch
external_links:
- es-cluster/es-master:elasticsearch
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- /:/host
labels:
aliyun.global: 'true'
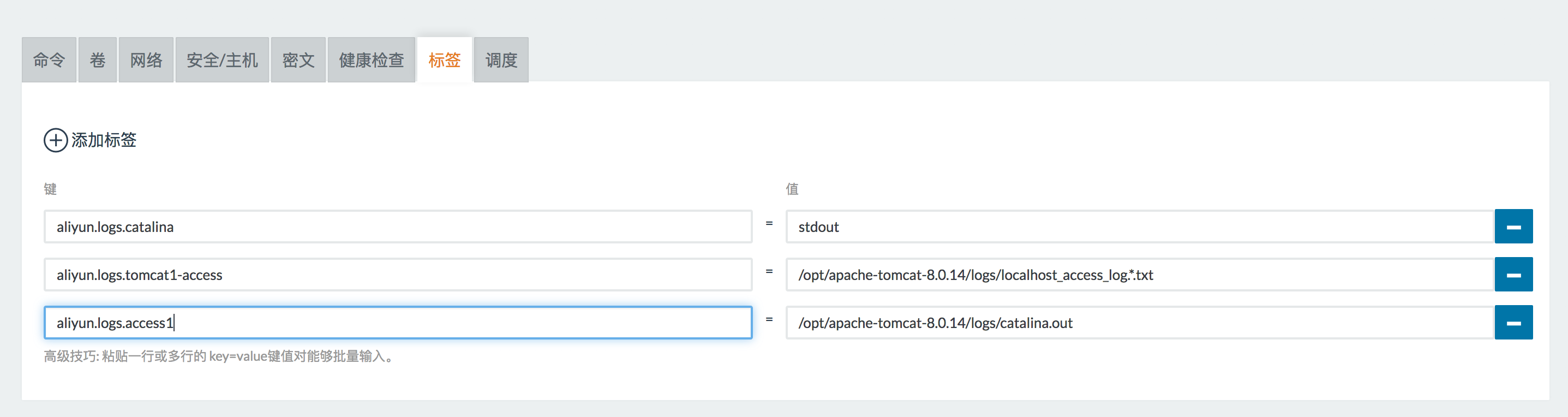
配置好之后启动自己的应用(例子:tomcat),我们看应用上面要收集的日志,我该在上面做什么样的声明?关键的配置有两个,一是label catalina,声明的是要收集容器的日志为什么格式(标准格式等,也可以是文件。),所有的名字都可以;二是声明access,这也是个名字,都可以用你喜欢的名字。这样一个路径的地址,当你通过这样的配置来去启动fluentd-pilot容器之后,它就能够感觉到这样一个容器的启动事件,它会去看容器的配置是什么,要收集这个目录下面的文件日志,然后告诉fluentd-pilot去中心配置并且去采集,这里还需要一个卷,实际上跟Logs目录是一致的,在容器外面实际上没有一种通用的方式能够获取到容器里面的文件,所有我们主动把目录从宿主机上挂载进来,这样就可以在宿主机上看到目录下面所有的东西。

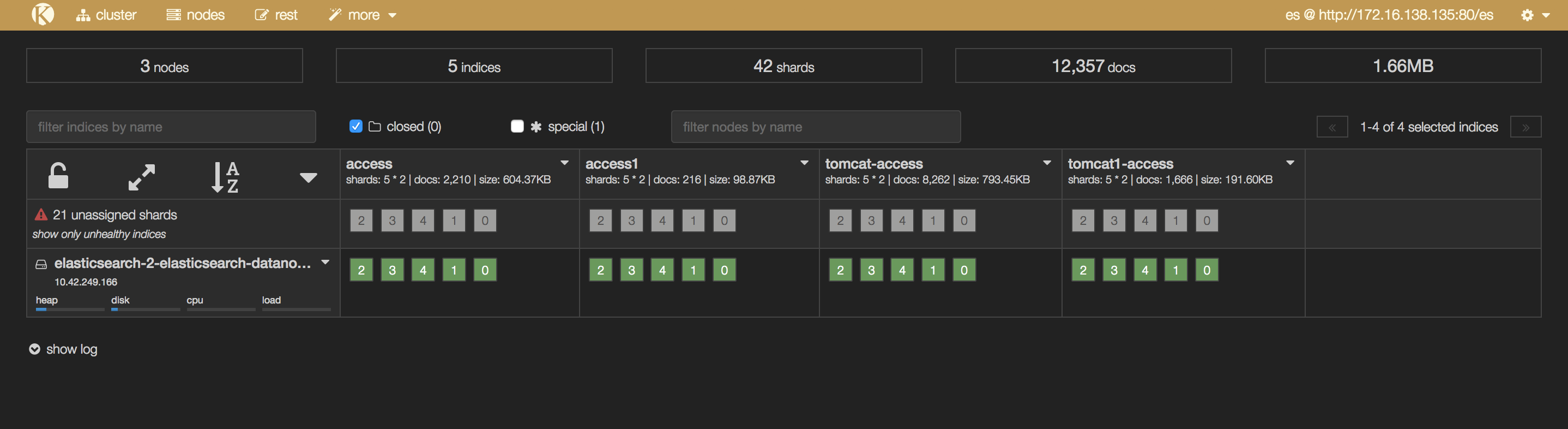
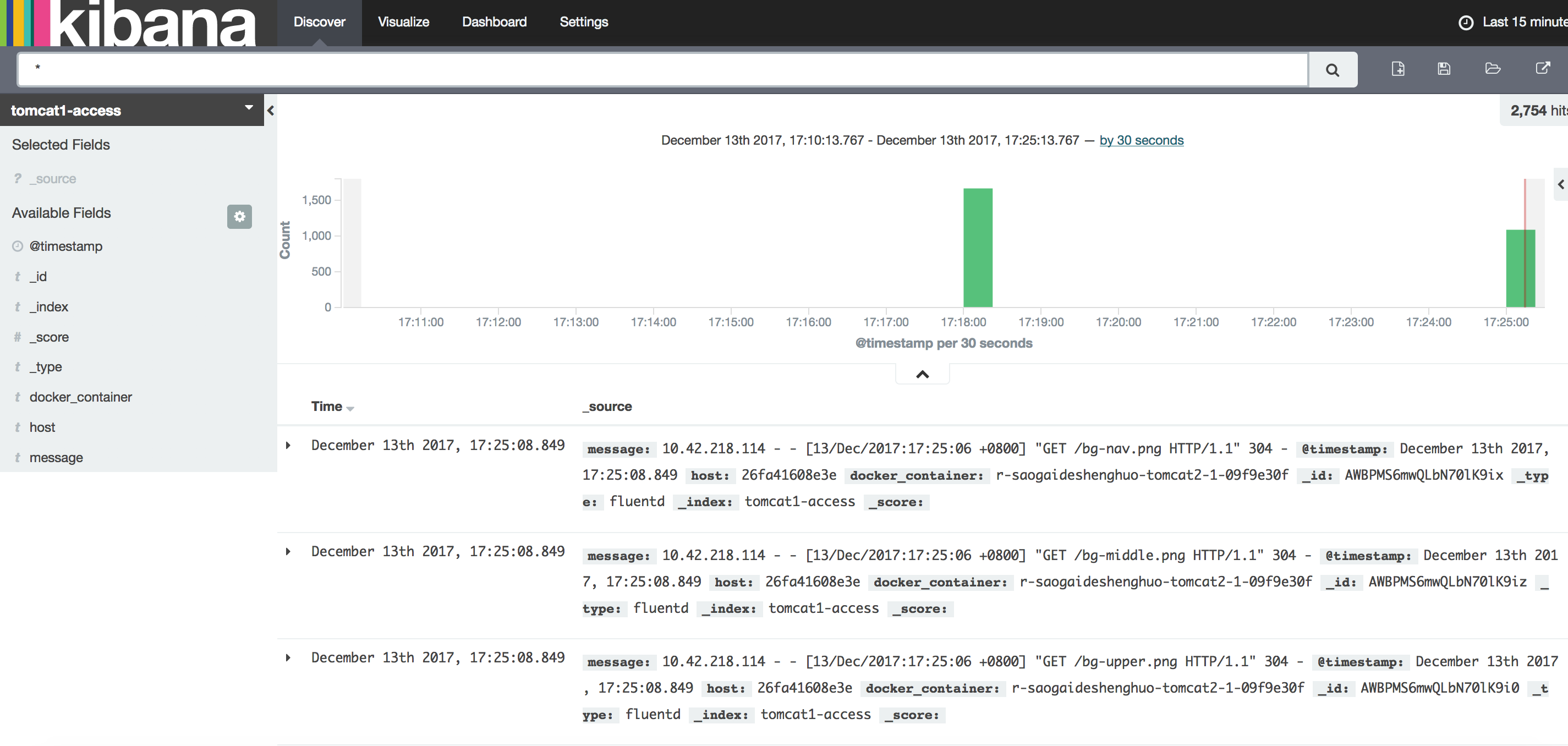
当你通过部署之后,他会自己在elasticsearch创建索引,就可以在elasticsearch的kopf上面看到会生成两个东西,都是自动创建好的,不用管一些配置,你唯一要做的事是什么呢?就可以在kibana上创建日志index pattern了。然后到日志搜索界面,可以看到从哪过来的,这条日志的内容是什么,这些信息都已经很快的出现了。
Lable说明
启动tomcat的时候,我们声明了这样下面两个,告诉fluentd-pilot这个容器的日志位置。
aliyun.logs.tomcat1-access /opt/apache-tomcat-8.0./logs/localhost_access_log.*.txt
aliyun.logs.catalina stdout
你还可以在应用容器上添加更多的标签
aliyun.logs.$name = $path
- 变量name是日志名称,具体指随便是什么,你高兴就好。只能包含
0-9a-zA-Z_和- - 变量path是要收集的日志路径,必须具体到文件,不能只写目录。文件名部分可以使用通配符。
/var/log/he.log和/var/log/*.log都是正确的值,但/var/log不行,不能只写到目录。stdout是一个特殊值,表示标准输出
aliyun.logs.$name.format,日志格式,目前支持
- none 无格式纯文本
- json: json格式,每行一个完整的json字符串
- csv: csv格式
aliyun.logs.$name.tags: 上报日志的时候,额外增加的字段,格式为k1=v1,k2=v2,每个key-value之间使用逗号分隔,例如
aliyun.logs.access.tags="name=hello,stage=test",上报到存储的日志里就会出现name字段和stage字段- 如果使用elasticsearch作为日志存储,target这个tag具有特殊含义,表示elasticsearch里对应的index
rancher使用fluentd-pilot收集日志分享的更多相关文章
- 4.安装fluentd用于收集集群内部应用日志
作者 微信:tangy8080 电子邮箱:914661180@qq.com 更新时间:2019-06-13 11:02:14 星期四 欢迎您订阅和分享我的订阅号,订阅号内会不定期分享一些我自己学习过程 ...
- ELK系列~Fluentd对大日志的处理过程~16K
Fluentd是一个日志收集工具,有输入端和输出端的概念,前者主要是日志的来源,你可以走多种来源方式,http,forward,tcp都可以,后者输出端主要指把日志进行持久化的过程,你可以直接把它持久 ...
- nginx日志切割并使用flume-ng收集日志
nginx的日志文件没有rotate功能.如果你不处理,日志文件将变得越来越大,还好我们可以写一个nginx日志切割脚本来自动切割日志文件.第一步就是重命名日志文件,不用担心重命名后nginx找不到日 ...
- 使用开源软件sentry来收集日志
原文地址:http://luxuryzh.iteye.com/blog/1980364 对于一个已经上线的系统,存在未知的bug或者运行时发生异常是很常见的事情,随之而来的几点需求产生了: 1.系统发 ...
- ELK收集日志到mysql
场景需求 在使用ELK对日志进行收集的时候,如果需要对数据进行存档,可以考虑使用数据库的方式.为了便于查询,可以同时写一份数据到Elasticsearch 中. 环境准备 CentOS7系统: 192 ...
- 通过 Systemd Journal 收集日志
随着 systemd 成了主流的 init 系统,systemd 的功能也在不断的增加,比如对系统日志的管理.Systemd 设计的日志系统好处多多,这里笔者就不再赘述了,本文笔者主要介绍 syste ...
- nswl 收集日志
nswl 收集日志 参考链接:https://docs.citrix.com/en-us/citrix-adc/12-1/system/web-server-logging.html PS C:\Us ...
- ELK之使用kafka作为消息队列收集日志
参考:https://www.cnblogs.com/fengjian2016/p/5841556.html https://www.cnblogs.com/hei12138/p/7805475 ...
- 配置好Nginx后,通过flume收集日志到hdfs(记得生成本地log时,不要生成一个文件,)
生成本地log最好生成多个文件放在一个文件夹里,特别多的时候一个小时一个文件 配置好Nginx后,通过flume收集日志到hdfs 可参考flume的文件 用flume的案例二 执行的注意点 avro ...
随机推荐
- 以@GetMapping为例,SpringMVC 组合注解
@GetMapping是一个组合注解,是@RequestMapping(method = RequestMethod.GET)的缩写.该注解将HTTP Get 映射到 特定的处理方法上.
- P1216 数字三角形
题目描述 观察下面的数字金字塔. 写一个程序来查找从最高点到底部任意处结束的路径,使路径经过数字的和最大.每一步可以走到左下方的点也可以到达右下方的点. 7 3 8 8 1 0 2 7 4 4 4 5 ...
- BZOJ5203 [NEERC2017 Northern] Grand Test 【dfs树】【构造】
题目分析: 首先观察可知这是一个无向图,那么我们构建出它的dfs树.由于无向图的性质我们可以知道它的dfs树只有返祖边.考虑下面这样一个结论. 结论:若一个点的子树中(包含自己)有两个点有到它祖先的返 ...
- Iroha and a Grid AtCoder - 1974(思维水题)
就是一个组合数水题 偷个图 去掉阴影部分 把整个图看成上下两个矩形 对于上面的矩形求出起点到每个绿点的方案 对于下面的矩形 求出每个绿点到终点的方案 上下两个绿点的方案相乘后相加 就是了 想想为什么 ...
- windows 虚拟环境下 安装 mysql 引擎一系列错误处理
报错现象 运行django 报错. 很明显是缺少引擎 下载引擎 django.core.exceptions.ImproperlyConfigured: Error loading MySQLdb m ...
- php+redis配置
系统环境: win10+phpstudy+lamp 安装扩展 php5.6.4 =>下载地址:http://windows.php.net/downloads/pecl/releases/red ...
- python学习日记(文件操作练习题)
登录注册(三次机会) name = input('请注册姓名:') password = input('请注册密码:') with open('log',mode='w',encoding='utf- ...
- 洛谷P3953 逛公园(NOIP2017)(最短/长路,拓扑排序,动态规划)
洛谷题目传送门 又是一年联赛季.NOIP2017至此收官了. 这个其实是比较套路的图论DP了,但是细节有点恶心. 先求出\(1\)到所有点的最短路\(d1\),和所有点到\(n\)的最短路\(dn\) ...
- Codeforces Round #543 Div1题解(并不全)
Codeforces Round #543 Div1题解 Codeforces A. Diana and Liana 给定一个长度为\(m\)的序列,你可以从中删去不超过\(m-n*k\)个元素,剩下 ...
- NOIP经典基础模板总结
date: 20180820 spj: 距离NOIP还有81天 目录 STL模板: priority_queue 的用法:重载<,struct cmpqueue 的用法 stack 的用法vec ...