Kafka安装部署
1.从官网下载安装包,并通过Xftp5上传到机器集群上
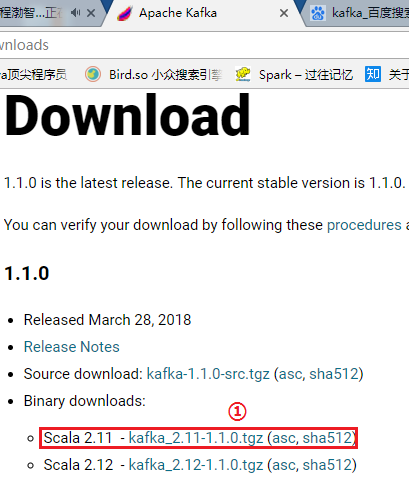
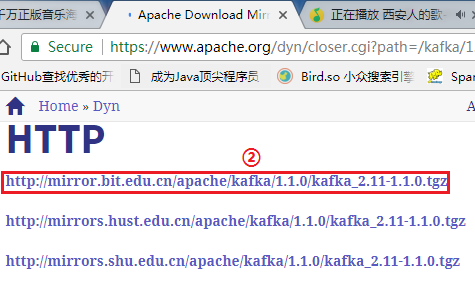
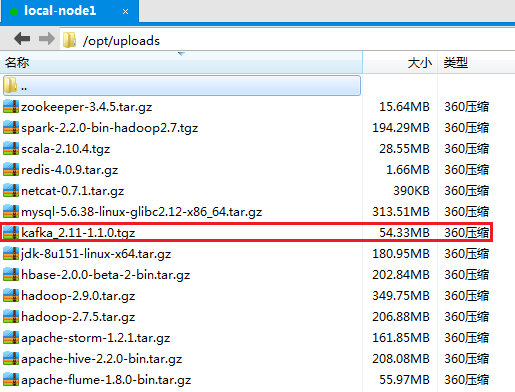
下载kafka_2.11-1.1.0.tgz版本,并通过Xftp5上传到hadoop机器集群的第一个节点node1上的/opt/uploads/目录:
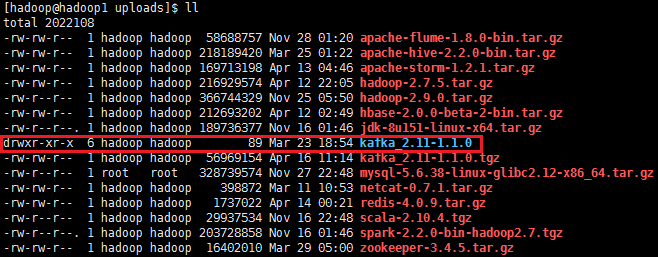
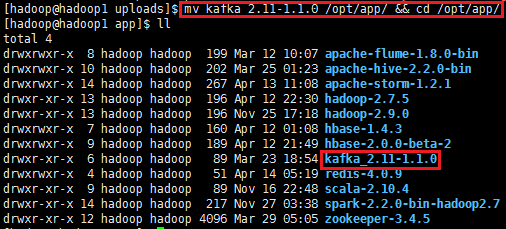
2、解压kafka_2.11-1.1.0.tgz,并把解压的安装包移动到/opt/app/目录上
tar zxvf kafka_2.11-1.1.0.tgz

mv kafka_2.11-1.1.0 /opt/app/ && cd /opt/app/
3、修改环境变量(每台机器都要执行),编辑/etc/profile,并生效环境变量,输入如下命令:
sudo vi /etc/profile
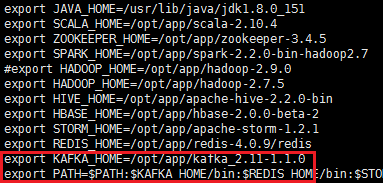
添加如下内容:
export KAFKA_HOME=/opt/app/kafka_2.11-1.1.0
export PATH=:$PATH:$KAFKA_HOME/bin
使环境变量生效:source /etc/profile
4、zookeeper集群安装搭建
zookeeper可以使用kafka_2.11-1.1.0内置的,也可以从zookeeper官网下载一个安装部署集群,差别不大。
安装部署及配置详情请看https://www.cnblogs.com/swordfall/p/8667409.html 第六节点。
这里独立安装zookeeper,不使用kafka内置的。
5、修改配置文件server.properties
进入kafka配置文件的目录,cd /opt/app/kafka_2.11-1.1.0/config/
修改server.properties文件 vi server.properties,将以下内容写入到server.properties文件中
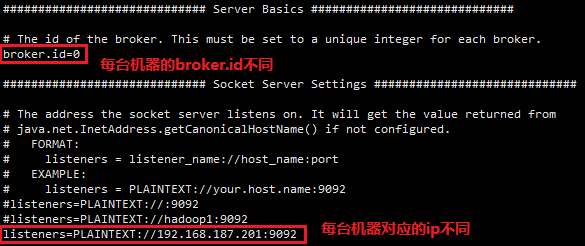
# broker id就是指各台服务器对应的id,所以各台服务器值不同
broker.id=0
# kafka端口号,无需改变
listeners=PLAINTEXT://192.168.187.201:9092
# 日志目录
log.dirs=/opt/app/kafka_2.11-1.1.0/logs
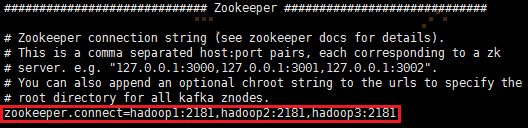
# Zookeeper集群的ip和端口号
zookeeper.connect=hadoop1:2181,hadoop2:2181,hadoop3:2181

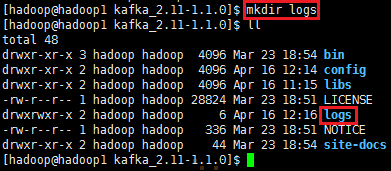
在/opt/app/kafka_2.11-1.1.0/logs目录下创建logs目录,mkdir logs目录
6. 把kafka的安装包发送到其他节点机器hadoop2和hadoop3
scp -r /opt/app/kafka_2.11-1.1.0/ hadoop@hadoop2:/opt/app/
scp -r /opt/app/kafka_2.11-1.1.0/ hadoop@hadoop3:/opt/app/
然后hadoop2、hadoop3分别重复第3步骤,修改环境变量
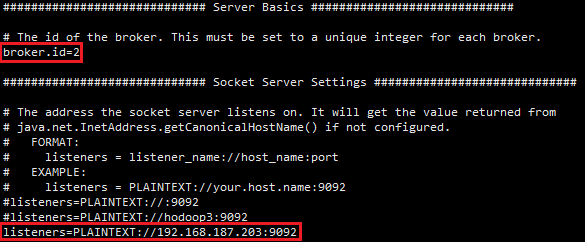
7. 分别在hadoop2、hadoop3机器节点上修改broker.id和listeners
hadoop2机器节点上修改kafka的server.properties配置文件

hadoop3机器节点上修改kafka的server.properties配置文件
8. 启动zookeeper和kafka
在每台机器上先分别通过命令zkServer.sh start启动zookeeper,再分别启动kafka为后台进程:
kafka-server-start.sh /opt/app/kafka_2.11-1.1.0/config/server.properties &

或者通过kafka-server-start.sh /opt/app/kafka_2.11-1.1.0/config/server.properties > /dev/null 2>&1 & 启动kafka
注:"> /dev/null" 表示把日志写入/dev/null,"2>&1"表示错误日志和标准输出日志合并写入一个文件,"&"表示后台运行
通过jps命令可以查看到每台机器上是否都启动了zookeeper和kafka
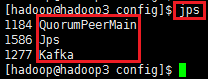
至此kafka集群部署成功。
9. 注意点
kafka安装包根目录下config/server.properties文件如果listeners配置的是hostname主机名,而不是ip,那么需要格外配置一项:
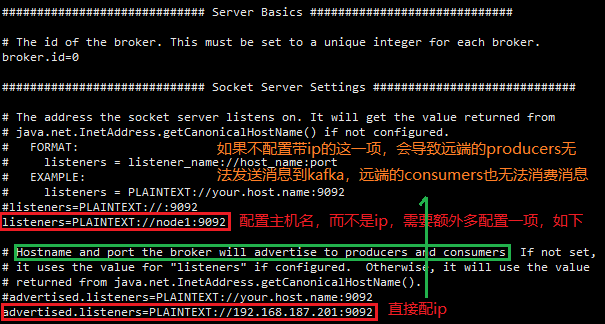
listeners的两种配置方法,可以二选一,一般选第一种。
Kafka安装部署的更多相关文章
- zookeeper与kafka安装部署及java环境搭建(发布订阅模式)
1. ZooKeeper安装部署 本文在一台机器上模拟3个zk server的集群安装. 1.1. 创建目录.解压 cd /usr/ #创建项目目录 mkdir zookeeper cd zookee ...
- ELK+KAFKA安装部署指南
一.ELK 背景 通常,日志被分散的储存不同的设备上.如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志.这样是不是感觉很繁琐和效率低下.当务之急我们使用集中化的日志管理,例如: ...
- 【Apache KafKa系列之一】KafKa安装部署
kafka是一种高吞吐量的分布式发布订阅消息系统,她有如下特性: 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能. 高吞吐量:即使是非常普通的 ...
- kafka 安装部署
环境:ubuntu 12.04 64位桌面版 解压kafka -0.10.0.0.tgz -C /root/software/ 进入目录 cd kafka_2.-0.10.0.0/ 创建data 目录 ...
- Kafka集群安装部署、Kafka生产者、Kafka消费者
Storm上游数据源之Kakfa 目标: 理解Storm消费的数据来源.理解JMS规范.理解Kafka核心组件.掌握Kakfa生产者API.掌握Kafka消费者API.对流式计算的生态环境有深入的了解 ...
- ELK文档-安装部署
一.ELK简介 请参考:http://www.cnblogs.com/aresxin/p/8035137.html 二.ElasticSearch安装部署 请参考:http://blog.51cto. ...
- Kafka安装及部署
安装及部署 一.环境配置 操作系统:Cent OS 7 Kafka版本:0.9.0.0 Kafka官网下载:请点击 JDK版本:1.7.0_51 SSH Secure Shell版本:XShell 5 ...
- centos7下kafka集群安装部署
应用摘要: Apache kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写.Kafka是一种高吞吐量的 分布式发布订阅消息系统,是消息中间件的一种,用于构建实时 ...
- kafka 的安装部署
Kafka 的简介: Kafka 是一款分布式消息发布和订阅系统,具有高性能.高吞吐量的特点而被广泛应用与大数据传输场景.它是由 LinkedIn 公司开发,使用 Scala 语言编写,之后成为 Ap ...
随机推荐
- 自学华为IoT物联网_05 能源工业物联网常见问题及解决方案
点击返回自学华为IoT物流网 自学华为IoT物联网_05 能源工业物联网常见问题及解决方案 1. 1 能源工业--油田业务面临的三大挑战 故障处理不及时: 部分油田开采难道大.机械故障较多.现场发生的 ...
- AXURE 8弄一个轮播图的步骤
这个图是网上找到,7.0可以使用. 如果是8.0.没有找到"动态面板"这个地方,如下图所示
- TJOI2011书架(dp)
当农夫约翰闲的没事干的时候,他喜欢坐下来看书.多年过去,他已经收集了 N 本书 (1 <= N <= 100,000), 他想造一个新的书架来装所有书. 每本书 i 都有宽度 W(i) 和 ...
- print
说一说这个print函数,我们经常使用,但有一些细节却往往错过了 print print()输出会换行是因为默认end="\n" 想要不换行,且覆盖 print("\r第 ...
- 整车CAN网络介绍
CAN(Controller Area Network)控制器局域网络,CAN网络在早期的整车应用中以BCM(车身控制器)为控制中心,主要是车身零部件(雨刮/大灯/车窗…),智能硬件较少,所以早期的正 ...
- 课后选做题:MyCP
目录 CP命令了解 MyCP实现 CP命令了解 作用:cp指令用于复制文件或目录,如同时指定两个以上的文件或目录,且最后的目的地是一个已经存在的目录,则它会把前面指定的所有文件或目录复制到此目录中.若 ...
- 源码分析-AutoCloseable
AutoCloseable 该接口用于try-with-resources语法糖提供支持,用于自动关闭资源作用 类型:接口 方法:close(); 详解: close():用于自动关闭资源的时候需要进 ...
- 发现环 (拓扑或dfs)
题目链接:http://lx.lanqiao.cn/problem.page?gpid=T453 问题描述 小明的实验室有N台电脑,编号1~N.原本这N台电脑之间有N-1条数据链接相连,恰好构成一个树 ...
- Codeforces1076D. Edge Deletion(最短路树+bfs)
题目链接:http://codeforces.com/contest/1076/problem/D 题目大意: 一个图N个点M条双向边.设各点到点1的距离为di,保证满足条件删除M-K条边之后使得到点 ...
- mui侧滑菜单"点击含有mui-action-menu类的控件"无法实现侧滑
.mui-action-menu 标题栏 菜单按钮 指定href="#id"显示与隐藏侧滑菜单 html: <div class="mui-off-canvas-w ...