python数据结构与算法第十五天【二叉树】
1.树的特点
(1)每个节点有零个或多个子节点;
(2)没有父节点的节点称为根节点;
(3)每一个非根节点有且只有一个父节点;
(4)除了根节点外,每个子节点可以分为多个不相交的子树;
2.树的种类
- 无序树:树中任意节点的子节点之间没有顺序关系,这种树称为无序树,也称为自由树;
- 有序树:树中任意节点的子节点之间有顺序关系,这种树称为有序树;
- 二叉树:每个节点最多含有两个子树的树称为二叉树;
- 完全二叉树:对于一颗二叉树,假设其深度为d(d>1)。除了第d层外,其它各层的节点数目均已达最大值,且第d层所有节点从左向右连续地紧密排列,这样的二叉树被称为完全二叉树,其中满二叉树的定义是所有叶节点都在最底层的完全二叉树;
- 平衡二叉树(AVL树):当且仅当任何节点的两棵子树的高度差不大于1的二叉树;
- 排序二叉树(二叉查找树(英语:Binary Search Tree),也称二叉搜索树、有序二叉树);
- 霍夫曼树(用于信息编码):带权路径最短的二叉树称为哈夫曼树或最优二叉树;
- B树:一种对读写操作进行优化的自平衡的二叉查找树,能够保持数据有序,拥有多余两个子树。
3. 树的使用场景
(1)xml,html等,那么编写这些东西的解析器的时候,不可避免用到树
(2)路由协议就是使用了树的算法
(3)mysql数据库索引
(4)文件系统的目录结构
(5)所以很多经典的AI算法其实都是树搜索,此外机器学习中的decision tree也是树结构
4.二叉树的性质
性质1: 在二叉树的第i层上至多有2^(i-1)个结点(i>0)
性质2: 深度为k的二叉树至多有2^k - 1个结点(k>0)
性质3: 对于任意一棵二叉树,如果其叶结点数为N0,而度数为2的结点总数为N2,则N0=N2+1;
性质4:具有n个结点的完全二叉树的深度必为 log2(n+1)
性质5:对完全二叉树,若从上至下、从左至右编号,则编号为i 的结点,其左孩子编号必为2i,其右孩子编号必为2i+1;其双亲的编号必为i/2(i=1 时为根,除外)
5.树的创建代码实现
class Node(object):
"""节点类"""
def __init__(self, elem=-1, lchild=None, rchild=None):
self.elem = elem
self.lchild = lchild
self.rchild = rchild
class Tree(object):
"""树类"""
def __init__(self, root=None):
self.root = root
def add(self, elem):
"""为树添加节点"""
node = Node(elem)
#如果树是空的,则对根节点赋值
if self.root == None:
self.root = node
else:
queue = []
queue.append(self.root)
#对已有的节点进行层次遍历
while queue:
#弹出队列的第一个元素
cur = queue.pop(0)
if cur.lchild == None:
cur.lchild = node
return
elif cur.rchild == None:
cur.rchild = node
return
else:
#如果左右子树都不为空,加入队列继续判断
queue.append(cur.lchild)
queue.append(cur.rchild)
5.树的广度优先遍历
def breadth_travel(self):
"""利用队列实现树的层次遍历"""
if root == None:
return
queue = []
queue.append(root)
while queue:
node = queue.pop(0)
print node.elem,
if node.lchild != None:
queue.append(node.lchild)
if node.rchild != None:
queue.append(node.rchild)
6.二叉树的深度优先遍历
(1)先序遍历,即 根-左-右
def preorder(self, root):
"""递归实现先序遍历"""
if root == None:
return
print root.elem
self.preorder(root.lchild)
self.preorder(root.rchild)
(2)中序遍历,即 左-根-右
def inorder(self, root):
"""递归实现中序遍历"""
if root == None:
return
self.inorder(root.lchild)
print root.elem
self.inorder(root.rchild)
(3)后序遍历,即 左-右-根
def postorder(self, root):
"""递归实现后续遍历"""
if root == None:
return
self.postorder(root.lchild)
self.postorder(root.rchild)
print root.elem
7.深度优先遍历举例:
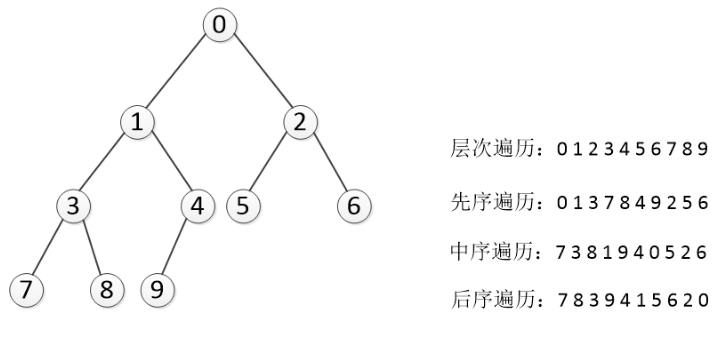
8.给出深度优先的先序和中序,请写出后序
自己实现
python数据结构与算法第十五天【二叉树】的更多相关文章
- Java数据结构和算法(十五)——无权无向图
前面我们介绍了树这种数据结构,树是由n(n>0)个有限节点通过连接它们的边组成一个具有层次关系的集合,把它叫做“树”是因为它看起来像一棵倒挂的树,包括二叉树.红黑树.2-3-4树.堆等各种不同的 ...
- python数据结构与算法第十六天【贪心算法与动态规划】
对于一个字符串,对字符串进行分割,分割后的每个子字符串都为回文串,求解所有可行的方案 这个问题可以使用贪心算法与动态规划来求解 步骤如下: (1)先得出所有的单个字符的回文串,单个字符必定是回文串, ...
- python数据结构与算法第十四天【二分查找】
1.二分查找的原理 对于已经排序的列表进行最快速度的查找 2. 代码实现 (1)递归实现 def binary_search(alist, item): if len(alist) == 0: ret ...
- python数据结构与算法第十天【插入排序】
1.插入排序的原理 2.代码实现 def insert_sort(alist): # 从第二个位置,即下标为1的元素开始向前插入 for i in range(1, len(alist)): # 从第 ...
- Java数据结构和算法(十):二叉树
一.简介 二叉树是树这种数据结构的一员,后面我们还会介绍红黑树,2-3-4树等数据结构.那么为什么要使用树?它有什么优点? 前面我们介绍数组的数据结构,我们知道对于有序数组,查找很快,并介绍可以通过二 ...
- python数据结构与算法
最近忙着准备各种笔试的东西,主要看什么数据结构啊,算法啦,balahbalah啊,以前一直就没看过这些,就挑了本简单的<啊哈算法>入门,不过里面的数据结构和算法都是用C语言写的,而自己对p ...
- Python之路【第十五篇】:Web框架
Python之路[第十五篇]:Web框架 Web框架本质 众所周知,对于所有的Web应用,本质上其实就是一个socket服务端,用户的浏览器其实就是一个socket客户端. 1 2 3 4 5 6 ...
- Python数据结构与算法--List和Dictionaries
Lists 当实现 list 的数据结构的时候Python 的设计者有很多的选择. 每一个选择都有可能影响着 list 操作执行的快慢. 当然他们也试图优化一些不常见的操作. 但是当权衡的时候,它们还 ...
- Python数据结构与算法--算法分析
在计算机科学中,算法分析(Analysis of algorithm)是分析执行一个给定算法需要消耗的计算资源数量(例如计算时间,存储器使用等)的过程.算法的效率或复杂度在理论上表示为一个函数.其定义 ...
随机推荐
- 【转】【fiddler】抓取https数据失败,全部显示“Tunnel to......443”
这个问题是昨天下午就一直存在的,知道今天上午才解决,很感谢“韬光养晦”. 问题描述: 按照网络上的教程,设置fiddler开启解密https的选项,同时fiddler的证书也是安装到系统中,但是抓取h ...
- UART\RS232与RS485的关系
https://blog.csdn.net/lhl161123/article/details/53510593 串口通讯是电子工程师面对的最基本的一个通讯方式,RS-232是其中最简单的一种.然而, ...
- IBus prior to 15.11 may cause input problems. See IDEA-78860 for details.
启动 PyCharm 2017.2, 遇到问题: IBus prior to 15.11 may cause input problems. See IDEA-78860 for details. 解 ...
- 初学Python——进程
什么是进程? 程序不能单独执行,只有将程序装载到内存中,系统为它分配资源才能运行,而这种执行的过程就叫做进程.进程是操作系统调度的最小单位. 程序和进程的区别在于:程序是储存在硬盘上指令的有序集合,是 ...
- Ubuntu14.04下如何安装TensorFlow
一.安装Anaconda Anaconda官网(www.continuum.io/downloads) 也可以在(https://repo.continuum.io/archive/)上根据自己的操作 ...
- Generative Adversarial Nets[content]
0. Introduction 基于纳什平衡,零和游戏,最大最小策略等角度来作为GAN的引言 1. GAN GAN开山之作 图1.1 GAN的判别器和生成器的结构图及loss 2. Condition ...
- Python全栈开发之路 【第八篇】:面向对象编程设计与开发(2)
一.继承与派生 什么是继承? 继承指的是类与类之间的关系,是一种什么是什么的关系,继承的功能之一就是用来解决代码重用问题. 继承是一种创建新的类的方式,在python中,新建的类可以继承一个或多个父类 ...
- 15-分析Ajax请求并抓取今日头条街拍美图
流程框架: 抓取索引页内容:利用requests请求目标站点,得到索引网页HTML代码,返回结果. 抓取详情页内容:解析返回结果,得到详情页的链接,并进一步抓取详情页的信息. 下载图片与保存数据库:将 ...
- scrapy框架爬取妹子图片
首先,建立一个项目#可在github账户下载完整代码:https://github.com/connordb/scrapy-jiandan2 scrapy startproject jiandan2 ...
- IOS-43-导航栏标题navigationItem.title不能改变颜色的两种解决方法
IOS-43-导航栏标题navigationItem.title不能改变颜色的两种解决方法 IOS-43-导航栏标题navigationItem.title不能改变颜色的两种解决方法 两种方法只是形式 ...