python数据结构与算法第十五天【二叉树】
1.树的特点
(1)每个节点有零个或多个子节点;
(2)没有父节点的节点称为根节点;
(3)每一个非根节点有且只有一个父节点;
(4)除了根节点外,每个子节点可以分为多个不相交的子树;
2.树的种类
- 无序树:树中任意节点的子节点之间没有顺序关系,这种树称为无序树,也称为自由树;
- 有序树:树中任意节点的子节点之间有顺序关系,这种树称为有序树;
- 二叉树:每个节点最多含有两个子树的树称为二叉树;
- 完全二叉树:对于一颗二叉树,假设其深度为d(d>1)。除了第d层外,其它各层的节点数目均已达最大值,且第d层所有节点从左向右连续地紧密排列,这样的二叉树被称为完全二叉树,其中满二叉树的定义是所有叶节点都在最底层的完全二叉树;
- 平衡二叉树(AVL树):当且仅当任何节点的两棵子树的高度差不大于1的二叉树;
- 排序二叉树(二叉查找树(英语:Binary Search Tree),也称二叉搜索树、有序二叉树);
- 霍夫曼树(用于信息编码):带权路径最短的二叉树称为哈夫曼树或最优二叉树;
- B树:一种对读写操作进行优化的自平衡的二叉查找树,能够保持数据有序,拥有多余两个子树。
3. 树的使用场景
(1)xml,html等,那么编写这些东西的解析器的时候,不可避免用到树
(2)路由协议就是使用了树的算法
(3)mysql数据库索引
(4)文件系统的目录结构
(5)所以很多经典的AI算法其实都是树搜索,此外机器学习中的decision tree也是树结构
4.二叉树的性质
性质1: 在二叉树的第i层上至多有2^(i-1)个结点(i>0)
性质2: 深度为k的二叉树至多有2^k - 1个结点(k>0)
性质3: 对于任意一棵二叉树,如果其叶结点数为N0,而度数为2的结点总数为N2,则N0=N2+1;
性质4:具有n个结点的完全二叉树的深度必为 log2(n+1)
性质5:对完全二叉树,若从上至下、从左至右编号,则编号为i 的结点,其左孩子编号必为2i,其右孩子编号必为2i+1;其双亲的编号必为i/2(i=1 时为根,除外)
5.树的创建代码实现
class Node(object):
"""节点类"""
def __init__(self, elem=-1, lchild=None, rchild=None):
self.elem = elem
self.lchild = lchild
self.rchild = rchild
class Tree(object):
"""树类"""
def __init__(self, root=None):
self.root = root
def add(self, elem):
"""为树添加节点"""
node = Node(elem)
#如果树是空的,则对根节点赋值
if self.root == None:
self.root = node
else:
queue = []
queue.append(self.root)
#对已有的节点进行层次遍历
while queue:
#弹出队列的第一个元素
cur = queue.pop(0)
if cur.lchild == None:
cur.lchild = node
return
elif cur.rchild == None:
cur.rchild = node
return
else:
#如果左右子树都不为空,加入队列继续判断
queue.append(cur.lchild)
queue.append(cur.rchild)
5.树的广度优先遍历
def breadth_travel(self):
"""利用队列实现树的层次遍历"""
if root == None:
return
queue = []
queue.append(root)
while queue:
node = queue.pop(0)
print node.elem,
if node.lchild != None:
queue.append(node.lchild)
if node.rchild != None:
queue.append(node.rchild)
6.二叉树的深度优先遍历
(1)先序遍历,即 根-左-右
def preorder(self, root):
"""递归实现先序遍历"""
if root == None:
return
print root.elem
self.preorder(root.lchild)
self.preorder(root.rchild)
(2)中序遍历,即 左-根-右
def inorder(self, root):
"""递归实现中序遍历"""
if root == None:
return
self.inorder(root.lchild)
print root.elem
self.inorder(root.rchild)
(3)后序遍历,即 左-右-根
def postorder(self, root):
"""递归实现后续遍历"""
if root == None:
return
self.postorder(root.lchild)
self.postorder(root.rchild)
print root.elem
7.深度优先遍历举例:
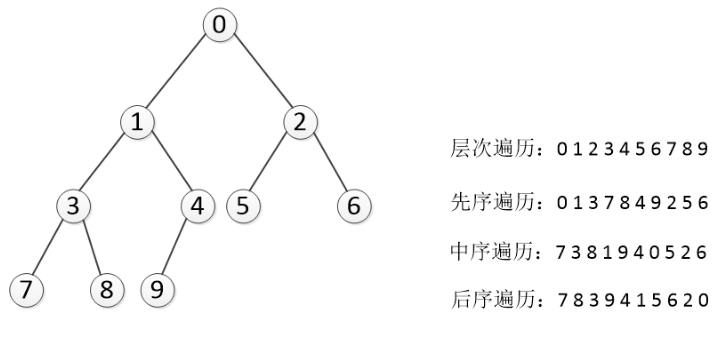
8.给出深度优先的先序和中序,请写出后序
自己实现
python数据结构与算法第十五天【二叉树】的更多相关文章
- Java数据结构和算法(十五)——无权无向图
前面我们介绍了树这种数据结构,树是由n(n>0)个有限节点通过连接它们的边组成一个具有层次关系的集合,把它叫做“树”是因为它看起来像一棵倒挂的树,包括二叉树.红黑树.2-3-4树.堆等各种不同的 ...
- python数据结构与算法第十六天【贪心算法与动态规划】
对于一个字符串,对字符串进行分割,分割后的每个子字符串都为回文串,求解所有可行的方案 这个问题可以使用贪心算法与动态规划来求解 步骤如下: (1)先得出所有的单个字符的回文串,单个字符必定是回文串, ...
- python数据结构与算法第十四天【二分查找】
1.二分查找的原理 对于已经排序的列表进行最快速度的查找 2. 代码实现 (1)递归实现 def binary_search(alist, item): if len(alist) == 0: ret ...
- python数据结构与算法第十天【插入排序】
1.插入排序的原理 2.代码实现 def insert_sort(alist): # 从第二个位置,即下标为1的元素开始向前插入 for i in range(1, len(alist)): # 从第 ...
- Java数据结构和算法(十):二叉树
一.简介 二叉树是树这种数据结构的一员,后面我们还会介绍红黑树,2-3-4树等数据结构.那么为什么要使用树?它有什么优点? 前面我们介绍数组的数据结构,我们知道对于有序数组,查找很快,并介绍可以通过二 ...
- python数据结构与算法
最近忙着准备各种笔试的东西,主要看什么数据结构啊,算法啦,balahbalah啊,以前一直就没看过这些,就挑了本简单的<啊哈算法>入门,不过里面的数据结构和算法都是用C语言写的,而自己对p ...
- Python之路【第十五篇】:Web框架
Python之路[第十五篇]:Web框架 Web框架本质 众所周知,对于所有的Web应用,本质上其实就是一个socket服务端,用户的浏览器其实就是一个socket客户端. 1 2 3 4 5 6 ...
- Python数据结构与算法--List和Dictionaries
Lists 当实现 list 的数据结构的时候Python 的设计者有很多的选择. 每一个选择都有可能影响着 list 操作执行的快慢. 当然他们也试图优化一些不常见的操作. 但是当权衡的时候,它们还 ...
- Python数据结构与算法--算法分析
在计算机科学中,算法分析(Analysis of algorithm)是分析执行一个给定算法需要消耗的计算资源数量(例如计算时间,存储器使用等)的过程.算法的效率或复杂度在理论上表示为一个函数.其定义 ...
随机推荐
- Sql优化器究竟帮你做了哪些工作
https://my.oschina.net/u/1859679?tab=newest&catalogId=597012 上一篇,我们介绍了<DB——数据的读取和存储方式>,这篇聊 ...
- docker 10 docker的镜像原理
镜像是什么? 镜像是一个轻量级,可执行的软件包,用来打包运行环境和基于运行环境开发的软件包,它包含某个软件运行环境的所有内容.包括代码,运行时的库,配置文件和环境变量 UnionFs(联合文件系统) ...
- HashMap是如何工作的
目录 1 HashMap在JAVA中的怎么工作的? 2 什么是哈希? 3 HashMap 中的 Node 类 4 键值对在 HashMap 中是如何存储的 5 哈希碰撞及其处理 6 HashMap 的 ...
- 3.sparkSQL整合Hive
spark SQL经常需要访问Hive metastore,Spark SQL可以通过Hive metastore获取Hive表的元数据.从Spark 1.4.0开始,Spark SQL只需简单的配置 ...
- WCF系列教程之WCF服务配置工具
本文参考自http://www.cnblogs.com/wangweimutou/p/4367905.html Visual studio 针对服务配置提供了一个可视化的配置界面(Microsoft ...
- js canvas图片压缩
function preview_picture(pic){ var r=new FileReader(); r.readAsDataURL(pic); r.onload=function(e){ d ...
- github/gitlab同时管理多个ssh key
之前一直用github,但是github有一个不好的地方,要是创建私有的项目的话需要付费,而gitlab上则可以免费创建管理私有的项目.由于最近想把自己论文的一些东西整理一下,很多东西还是不方便公开, ...
- TCP粘包问题解析与解决
一.粘包分析 作者本人在写一个FTP项目时,在文件的上传下载模块遇到了粘包问题.在网上找了一些解决办法,感觉对我情况都不好用,因此自己想了个比较好的解决办法,提供参考 1.1 粘包现象 在客户端与服务 ...
- [2017BUAA软工助教]第0次作业小结
BUAA软工第0次作业小结 零.题目 作业链接: This is a hyperlink 一.评分规则 本次作业满分10分: 按时提交有分 一周内补交得0分 超过一周不交或抄袭倒扣全部分数 评分规则如 ...
- shell脚本使用记录一:操作文件
一,连接远程数据库(保证在服务器上能使用mysql命令行,至少要安装mysql客户端) #!/bin/bash HOSTNAME="ip" PORT=" USERNAME ...