Spark数据本地化-->如何达到性能调优的目的
Spark数据本地化-->如何达到性能调优的目的
1.Spark数据的本地化:移动计算,而不是移动数据
2.Spark中的数据本地化级别:
| TaskSetManager 的 Locality Levels 分为以下五个级别: |
| PROCESS_LOCAL |
| NODE_LOCAL |
| NO_PREF |
| RACK_LOCAL |
| ANY |

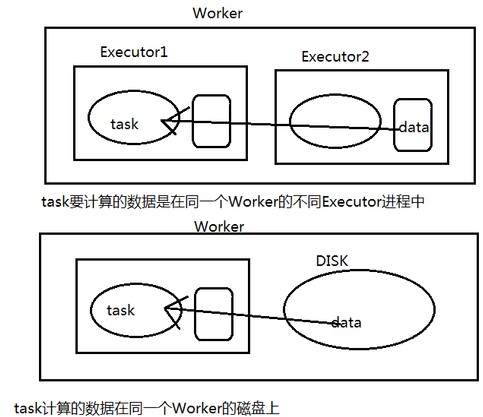
3.Spark中的数据本地化由谁负责?
4.Spark中的数据本地化流程图
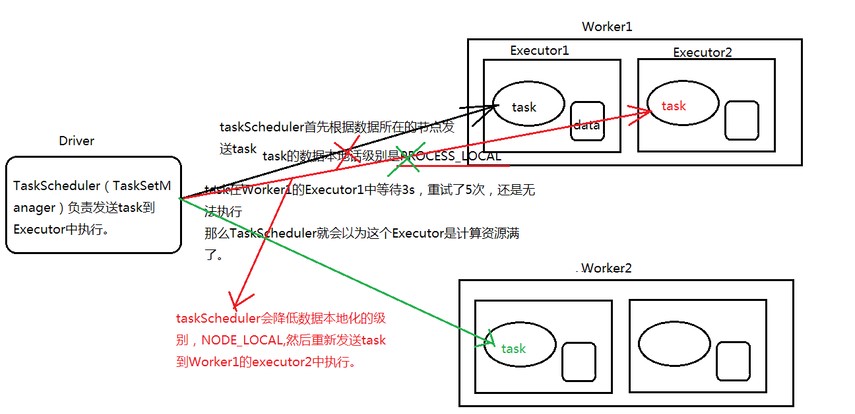
spark.locality.wait 3s//相当于是全局的,下面默认以3s为准,手动设置了,以手动的为准spark.locality.wait.processspark.locality.wait.nodespark.locality.wait.racknewSparkConf.set("spark.locality.wait","100")
Spark数据本地化-->如何达到性能调优的目的的更多相关文章
- Spark SQL概念学习系列之性能调优
不多说,直接上干货! 性能调优 Caching Data In Memory Spark SQL可以通过调用sqlContext.cacheTable("tableName") 或 ...
- Spark(十二)--性能调优篇
一段程序只能完成功能是没有用的,只能能够稳定.高效率地运行才是生成环境所需要的. 本篇记录了Spark各个角度的调优技巧,以备不时之需. 一.配置参数的方式和观察性能的方式 额...从最基本的开始讲, ...
- [Spark性能调优] 第一章:性能调优的本质、Spark资源使用原理和调优要点分析
本課主題 大数据性能调优的本质 Spark 性能调优要点分析 Spark 资源使用原理流程 Spark 资源调优最佳实战 Spark 更高性能的算子 引言 我们谈大数据性能调优,到底在谈什么,它的本质 ...
- [Spark性能调优] 第二章:彻底解密Spark的HashShuffle
本課主題 Shuffle 是分布式系统的天敌 Spark HashShuffle介绍 Spark Consolidated HashShuffle介绍 Shuffle 是如何成为 Spark 性能杀手 ...
- [Spark性能调优] 第三章 : Spark 2.1.0 中 Sort-Based Shuffle 产生的内幕
本課主題 Sorted-Based Shuffle 的诞生和介绍 Shuffle 中六大令人费解的问题 Sorted-Based Shuffle 的排序和源码鉴赏 Shuffle 在运行时的内存管理 ...
- [Spark性能调优] 第四章 : Spark Shuffle 中 JVM 内存使用及配置内幕详情
本课主题 JVM 內存使用架构剖析 Spark 1.6.x 和 Spark 2.x 的 JVM 剖析 Spark 1.6.x 以前 on Yarn 计算内存使用案例 Spark Unified Mem ...
- [Spark性能调优] 源码补充 : Spark 2.1.X 中 Unified 和 Static MemoryManager
本课主题 Static MemoryManager 的源码鉴赏 Unified MemoryManager 的源码鉴赏 引言 从源码的角度了解 Spark 内存管理是怎么设计的,从而知道应该配置那个参 ...
- Spark性能调优之资源分配
Spark性能调优之资源分配 性能优化王道就是给更多资源!机器更多了,CPU更多了,内存更多了,性能和速度上的提升,是显而易见的.基本上,在一定范围之内,增加资源与性能的提升,是成正比的:写完了 ...
- 【原创】SQL Server 性能调优读书笔记
CPU 100%: 有时可能是硬盘性能不足,或者内存容量不够,让CPU一直忙于I/O. 导致性能问题的一些因素: 用户习惯:在运行尖峰时刻做一些不必做但消耗资源的事情,如之行数据库完整备份,如在服务器 ...
随机推荐
- Delphi中ShellExecute的妙用
ShellExecute的功能是运行一个外部程序(或者是打开一个已注册的文件.打开一个目录.打印一个文件等等),并对外部程序有一定的控制.有几个API函数都可以实现这些功能,但是在大多数情况下Shel ...
- iOS 登陆之界面设置
1.界面构成 1.1. 效果图 1.2. 元素 背景图 用户名的输入框 密码的输入框 登陆按钮 忘记密码 用户注册 第三方登陆 两个分割线
- 使用ActionBar实现下拉式导航
ActionBar除可提供Tab导航支持之外,还提供了下拉式(DropDown)导航方式.下拉式导航的ActionBar在顶端生成下拉列表框,当用户单击某个列表项时,系统根据用户单击事件导航指定Fra ...
- axure8.0注册码
激活码:(亲测可用) 用户名:aaa 注册码:2GQrt5XHYY7SBK/4b22Gm4Dh8alaR0/0k3gEN5h7FkVPIn8oG3uphlOeytIajxGU 用户名:axureuse ...
- U盘为什么还有剩余空间,但却提示说空间不够
你的U盘是FAT32格式,它只支持单一小于4G的文件复制,将U盘改为NTFS格式,可以解决题.方法:开始——运行,输入“cmd”,回车,在命令符后输入:convert h: /fs:ntfs,回车(假 ...
- JQuery hover toggle事件使用
JQuery hover toggle事件使用: <%@ page language="java" import="java.util.*" pageEn ...
- 程序启动缓慢-原来是hbm.xml doctype的原因
<!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN" "h ...
- POJ1200(hash)
Crazy Search Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 27536 Accepted: 7692 Des ...
- 【js 编程艺术】小制作三
1.html文件 <!DOCTYPE html> <html> <head> <meta charset="utf-8"> < ...
- Dev的WPF控件与VS2012不兼容问题
在只有vs2010环境下Dev的wpf可以在视图模式下显示,但是安装vs2012后无法打开界面的视图模式,报错:无法创建控件实例! 发现是Dev的wpf控件与.net framework 4.5不兼容 ...