Spark数据本地化-->如何达到性能调优的目的
Spark数据本地化-->如何达到性能调优的目的
1.Spark数据的本地化:移动计算,而不是移动数据
2.Spark中的数据本地化级别:
| TaskSetManager 的 Locality Levels 分为以下五个级别: |
| PROCESS_LOCAL |
| NODE_LOCAL |
| NO_PREF |
| RACK_LOCAL |
| ANY |

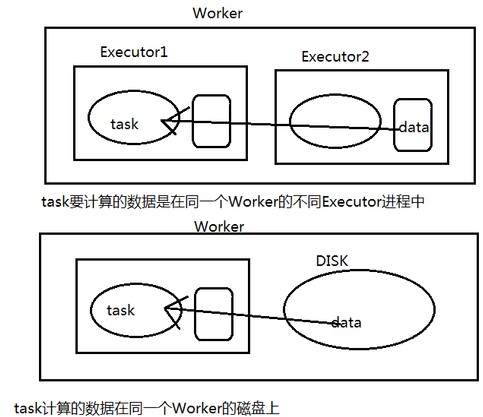
3.Spark中的数据本地化由谁负责?
4.Spark中的数据本地化流程图
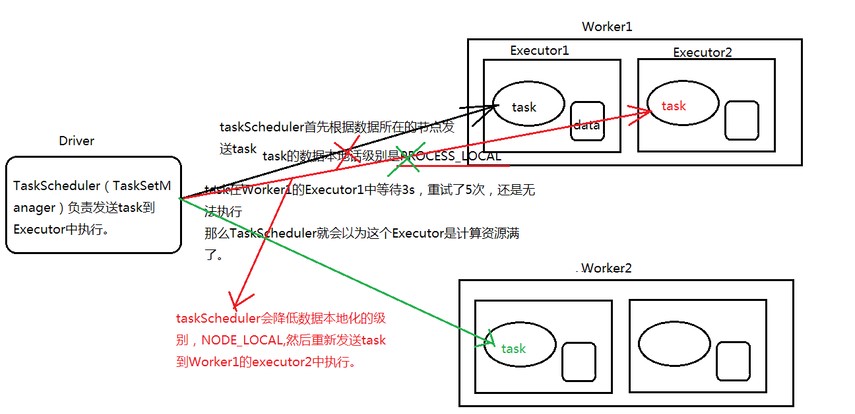
spark.locality.wait 3s//相当于是全局的,下面默认以3s为准,手动设置了,以手动的为准spark.locality.wait.processspark.locality.wait.nodespark.locality.wait.racknewSparkConf.set("spark.locality.wait","100")
Spark数据本地化-->如何达到性能调优的目的的更多相关文章
- Spark SQL概念学习系列之性能调优
不多说,直接上干货! 性能调优 Caching Data In Memory Spark SQL可以通过调用sqlContext.cacheTable("tableName") 或 ...
- Spark(十二)--性能调优篇
一段程序只能完成功能是没有用的,只能能够稳定.高效率地运行才是生成环境所需要的. 本篇记录了Spark各个角度的调优技巧,以备不时之需. 一.配置参数的方式和观察性能的方式 额...从最基本的开始讲, ...
- [Spark性能调优] 第一章:性能调优的本质、Spark资源使用原理和调优要点分析
本課主題 大数据性能调优的本质 Spark 性能调优要点分析 Spark 资源使用原理流程 Spark 资源调优最佳实战 Spark 更高性能的算子 引言 我们谈大数据性能调优,到底在谈什么,它的本质 ...
- [Spark性能调优] 第二章:彻底解密Spark的HashShuffle
本課主題 Shuffle 是分布式系统的天敌 Spark HashShuffle介绍 Spark Consolidated HashShuffle介绍 Shuffle 是如何成为 Spark 性能杀手 ...
- [Spark性能调优] 第三章 : Spark 2.1.0 中 Sort-Based Shuffle 产生的内幕
本課主題 Sorted-Based Shuffle 的诞生和介绍 Shuffle 中六大令人费解的问题 Sorted-Based Shuffle 的排序和源码鉴赏 Shuffle 在运行时的内存管理 ...
- [Spark性能调优] 第四章 : Spark Shuffle 中 JVM 内存使用及配置内幕详情
本课主题 JVM 內存使用架构剖析 Spark 1.6.x 和 Spark 2.x 的 JVM 剖析 Spark 1.6.x 以前 on Yarn 计算内存使用案例 Spark Unified Mem ...
- [Spark性能调优] 源码补充 : Spark 2.1.X 中 Unified 和 Static MemoryManager
本课主题 Static MemoryManager 的源码鉴赏 Unified MemoryManager 的源码鉴赏 引言 从源码的角度了解 Spark 内存管理是怎么设计的,从而知道应该配置那个参 ...
- Spark性能调优之资源分配
Spark性能调优之资源分配 性能优化王道就是给更多资源!机器更多了,CPU更多了,内存更多了,性能和速度上的提升,是显而易见的.基本上,在一定范围之内,增加资源与性能的提升,是成正比的:写完了 ...
- 【原创】SQL Server 性能调优读书笔记
CPU 100%: 有时可能是硬盘性能不足,或者内存容量不够,让CPU一直忙于I/O. 导致性能问题的一些因素: 用户习惯:在运行尖峰时刻做一些不必做但消耗资源的事情,如之行数据库完整备份,如在服务器 ...
随机推荐
- js架构设计模式——你对MVC、MVP、MVVM 三种组合模式分别有什么样的理解?
你对MVC.MVP.MVVM 三种组合模式分别有什么样的理解? MVC(Model-View-Controller)MVP(Model-View-Presenter)MVVM(Model-View-V ...
- Intent的属性及Intent-filter配置——指定Action、Category调用系统Activity
Intent代表了启动某个程序组件的“意图”,实际上Intent对象不仅可以启动本应用内程序组件,也可启动Android系统的其他应用的程序组件,包括系统自带的程序组件——只要权限允许. 实际上And ...
- JavaScript成员属性读取
var obj = {}; 检索一个不存在的成员属性的值,将返回undefined; 可以使用||运算符来填充默认值: var status = obj.status||'inistatus' 从un ...
- VisualGDB Makefiles
以下内容是VisualGDB官网对VisualGDB编译时获取相关编译信息的说明: When you create a new project using VisualGDB, it will gen ...
- 【G】开源的分布式部署解决方案(一) - 开篇
做这个开源项目的意义是什么?(口水自问自答,不喜可略过) 从功能上来说,请参考 预告篇,因自知当时预告片没有任何含金量,所以并没有主动推送到首页,而是私下的给一些人发的. 从个人角度上来说,我希望.n ...
- 使用python制作ArcGIS插件(2)代码编写
使用python制作ArcGIS插件(2)代码编写 by 李远祥 上一章节已经介绍了如何去搭建AddIn的界面,接下来要实现具体的功能,则到了具体的编程环节.由于使用的是python语言进行编程,则开 ...
- IO的构造方法
package com.file; /* File的构造方法: File(String pathname); File(File parent,String child); File(String p ...
- Python自然语言处理学习笔记之信息提取步骤&分块(chunking)
一.信息提取模型 信息提取的步骤共分为五步,原始数据为未经处理的字符串, 第一步:分句,用nltk.sent_tokenize(text)实现,得到一个list of strings 第二步:分词,[ ...
- UI进阶 即时通讯之XMPP好友列表、添加好友、获取会话内容、简单聊天
这篇博客的代码是直接在上篇博客的基础上增加的,先给出部分代码,最后会给出能实现简单功能的完整代码. UI进阶 即时通讯之XMPP登录.注册 1.好友列表 初始化好友花名册 #pragma mark - ...
- css遇到的那些坑——浏览器默认样式设置
今天自己写css样式,其中用到了<ul>标签,设置了一系列效果后运行,发现位置与设置有出入.chrome上打开检查项,发现<ul>标签的styles底部多了以下一段: ul, ...