HttpGet协议与正则表达
使用HttpGet协议与正则表达实现桌面版的糗事百科
打开糗事百科笑话的主页,在这里我只取糗事笑话中文字这一板块,点击文字这一菜单栏。如下图。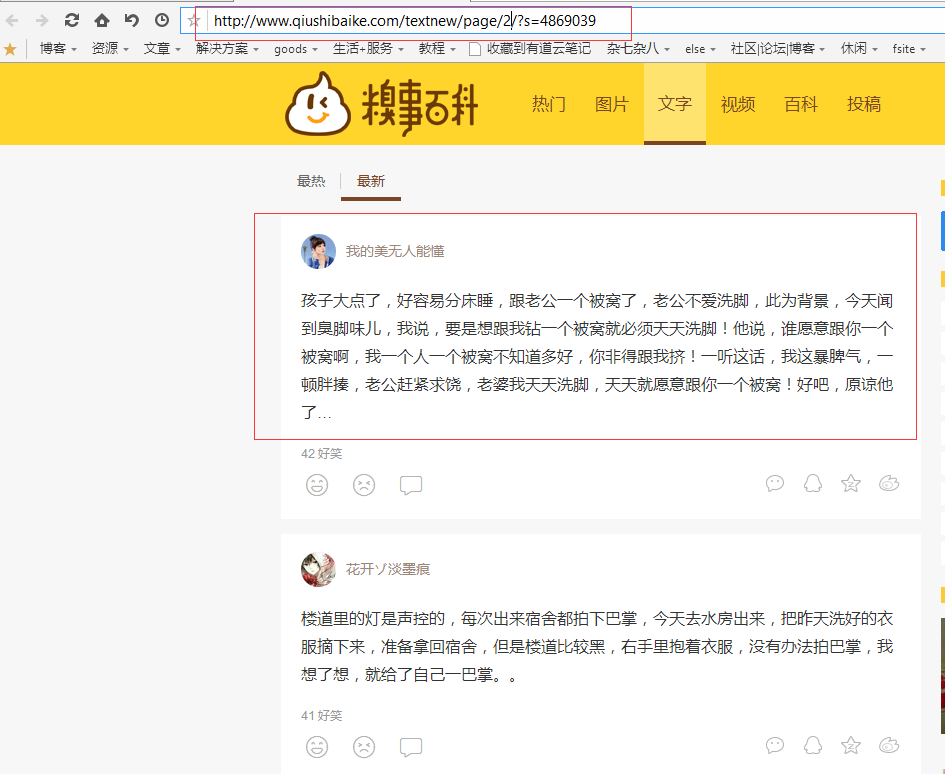
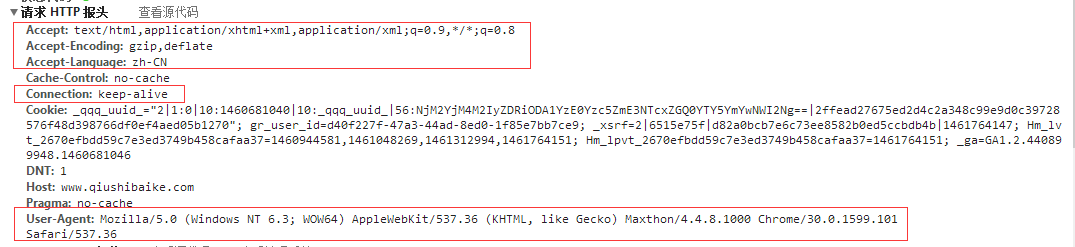

const string qsbkMainUrl = "http://www.qiushibaike.com";
//获取糗百文字笑话页的url
private static string GetWBJokeUrl(int pageIndex)
{
StringBuilder url = new StringBuilder();
url.Append(qsbkMainUrl);
url.Append ("/textnew/page/");
url.Append(pageIndex.ToString ());
url.Append("/?s=4869039");
return url.ToString();
}
//根据网页的url获取网页的html源码
private static string GetUrlContent(string url)
{
try
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.UserAgent = "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.4.8.1000 Chrome/30.0.1599.101 Safari/537.36";
request.Method = "GET";
request.ContentType = "text/html;charset=UTF-8";
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream myResponseStream = response.GetResponseStream();
StreamReader myStreamReader = new StreamReader(myResponseStream, Encoding.GetEncoding("utf-8"));//因为知道糗百网页的编码方式为utf-8
string retString = myStreamReader.ReadToEnd();
myStreamReader.Close();
myResponseStream.Close();
return retString;
}
catch { return null; }
}
在1中我们已经根据page页索引的不同而获取不同的页面内容,而这一步的任务就是如何从返回的html源代码中获取我们想要的笑话内容。
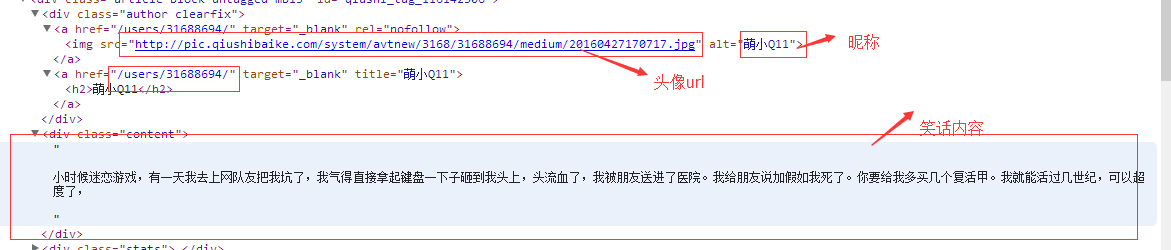
正则:<img src="([^"]*")\s*alt="([^"]*)"/>\s</a>\s<a href="([^"]*)"[^>]*>\s<h2>[^>]*>\s</a>\s</div>\s*<div class="content">\s*((.*|<br/>)*)
public class JokeItem
{
private string nickName;
/// <summary>
/// 昵称
/// </summary>
public string NickName
{
get { return nickName; }
set { nickName = value; }
}
private Image headImage;
/// <summary>
/// 头像
/// </summary>
public Image HeadImage
{
get { return headImage; }
set { headImage = value; }
}
private string jokeContent;
/// <summary>
/// 笑话内容
/// </summary>
public string JokeContent
{
get { return jokeContent; }
set { jokeContent = value; }
}
private string jokeUrl;
/// <summary>
/// 笑话地址
/// </summary>
public string JokeUrl
{
get { return jokeUrl; }
set { jokeUrl = value; }
}
}
b、利用正则获取笑话内容
/// <summary>
/// 获取笑话列表
/// </summary>
/// <param name="htmlContent"></param>
public static List<JokeItem> GetJokeList(int pageIndex)
{
string htmlContent=GetUrlContent(GetWBJokeUrl(pageIndex));
List<JokeItem> jokeList = new List<JokeItem>();
Regex rg = new Regex(@"<img src=""([^""]*"")\s*alt=""([^""]*)""/>\s</a>\s<a href=""([^""]*)""[^>]*>\s<h2>[^>]*>\s</a>\s</div>\s*<div class=""content"">\s*((.*|<br/>)*)", RegexOptions.IgnoreCase);
JokeItem joke;
MatchCollection matchResults = rg.Matches(htmlContent);
foreach (Match result in matchResults)
{
joke = new JokeItem();
joke.HeadImage = GetWebImage(result.Groups[1].Value);
joke.HeadImage = joke.HeadImage != null ? new Bitmap(GetWebImage(result.Groups[1].Value), 50, 50) : null;
joke.NickName = result.Groups[2].Value;
joke.JokeUrl = qsbkMainUrl + "/" + result.Groups[3].Value; ;
joke.JokeContent = result.Groups[4].Value.Replace("<br/>", "\r\n").Replace("<br>", "\r\n");
joke.JokeContent = Regex.Replace(joke.JokeContent, @"(\r\n)+", "\r\n");//去掉多余的空行
jokeList.Add(joke);
}
return jokeList;
}
c、根据头像url地址获取头像
private static Image GetWebImage(string webUrl)
{
try
{
Encoding encode = Encoding.GetEncoding("utf-8");//网页编码==Encoding.UTF8
HttpWebRequest req = (HttpWebRequest)WebRequest.Create(new Uri(webUrl));
HttpWebResponse ress = (HttpWebResponse)req.GetResponse();
Stream sstreamRes = ress.GetResponseStream();
return System.Drawing.Image.FromStream(sstreamRes);
}
catch { return null; }
}
3、数据绑定
HttpGet协议与正则表达的更多相关文章
- 使用HttpGet协议与正则表达实现桌面版的糗事百科
写在前面 最近在重温asp.net,找了一本相关的书籍.本书在第一章就讲了,在不使用浏览器的情况下生成一个web请求,获取服务器返回的内容.于是在网上搜索关于Http请求相关的资料,发现了很多资料都是 ...
- Javascript正则构造函数与正则表达字面量&&常用正则表达式
本文不讨论正则表达式入门,即如何使用正则匹配.讨论的是两种创建正则表达式的优劣和一些细节,最后给出一些常用正则匹配表达式. Javascript中的正则表达式也是对象,我们可以使用两种方法创建正则表达 ...
- js正则表达test、exec和match的区别
test的用法和exec一致,只不过返回值是 true false. 以前用js很少用到js的正则表达式,即使用到了,也是诸如邮件名称之类的判断,网上代码很多,很少有研究,拿来即用. 最近开发遇到一些 ...
- 正则表达示 for Python3
前情提要 从大量的文字内容中找到自己想要的东西,正则似乎是最好的方法.也是写爬虫不可缺少的技能.所以,别墨迹了赶紧好好学吧! 教程来自http://www.runoob.com/python3/pyt ...
- Python之面向对象和正则表达(代数运算和自动更正)
面向对象 一.概念解释 面对对象编程(OOP:object oriented programming):是一种程序设计范型,同时也是一种程序开发的方法,实现OOP的程序希望能够在程序中包含各种独立而又 ...
- JS写法 数值与字符串的相互转换 取字符中的一部分显示 正则表达规则
http://www.imooc.com/article/15885 正则表达规则 <script type="text/javascript"> </scrip ...
- shell正则表达
shell正则表达 .*和.?的比较: 比如说匹配输入串A: 101000000000100 使用 1.*1 将会匹配到1010000000001,匹配方法:先匹配至输入串A的最后, 然后向前匹配,直 ...
- python 正则表达提取方法 (提取不来的信息print不出来 加个输出type 再print信息即可)
1,正则表达提取 (findall函数提取) import re a= "<div class='content'>你大爷</div>"x=re.finda ...
- grep 正则表达
常见的 grep 正则表达参数 -c # 显示匹配到得行的数目,不显示内容 -h # 不显示文件名 -i # 忽略大小写 -l # 只列出匹配行所在文件的文件名 -n # 在每一行中加上相对行号 -s ...
随机推荐
- DOM querySelector选择器
原生的强大DOM选择器querySelector 在传统的 JavaScript 开发中,查找 DOM 往往是开发人员遇到的第一个头疼的问题,原生的 JavaScript 所提供的 DOM 选择方法并 ...
- PHP高级编程SPL
这几天,我在学习PHP语言中的SPL. 这个东西应该属于PHP中的高级内容,看上去非常复杂,可是非常实用,所以我做了长篇笔记.不然记不住,以后要用的时候,还是要从头学起. 因为这是供自己參考的笔记,不 ...
- sharepoint具体错误提示
sharepoint页面发生错误时,默认不会显示具体错误信息,只显示“未知错误”提示.需要修改配置站点的webconfig文件,才能显示出具体错误提示.具体方法如下: 将safeMode中的CallS ...
- linux命令:find
先上例子: find ./*_src -type f | xargs grep -ils "date" 在指定的那些文件夹下面,递归寻找包含“date” 字符串的普通文件. fin ...
- 俄罗斯方块SDK版
前言 本来可以从俄罗斯方块控制台版改一版, 将UI接口换掉, 变成SDK版. 正好放假了, 有时间. 就用了一个星期来重头做一个新版, 享受一下静下心来, 有条不紊干活的感觉^_^ 这个工程用来验证S ...
- C#日志工具汇总
log4net log4net是一个可以帮助程序员把日志信息输出到各种不同目标的.net类库.它可以容易的加载到开发项目中,实现程序调试和运行的时候的日志信息输出,提供了比.net自 ...
- cocos2d-x游戏开发 跑酷(两) 物理世界
原创.转载请注明出处:http://blog.csdn.net/dawn_moon/article/details/21240343 泰然的跑酷用的chipmunk物理引擎.我没有细致学过这个东西. ...
- Android滑动菜单框架完全解析,教你如何一分钟实现滑动菜单特效
转载请注明出处:http://blog.csdn.net/guolin_blog/article/details/8744400 之前我向大家介绍了史上最简单的滑动菜单的实现方式,相信大家都还记得.如 ...
- dataStage 7.5.1A
------------------------------ DataStage Server License ------------------------------ Serial Num ...
- Monkey 命令使用说明
1. 命令使用 Monkey是一个命令列工具 ,可以运行在仿真器里或实际设备中.它向系统发送伪随机的使用者事件流,实现对正在开发的应用程序进行压力测试.Monkey包括许多选项,它们大致分为四大类: ...