python 中文字数统计/分词
因为想把一段文字分词,所以,需要明确一定的词语关系。
在网上随便下载了一篇中文小说。随便的txt小说,就1mb多。要数数这1mb多的中文到底有多少字,多少分词,这些分词的词性是什么样的。
这里是思路
1)先把小说读到内存里面去。
2)再把小说根据正则表达法开始分词,获得小说中汉字总数
3)将内存中的小说每段POST到提供分词服务的API里面去,获取分词结果
4)按照API说明,取词
素材:
、linux/GNU => debian/ubuntu 12.04/Linuxmint Preferred
、python
、中文分词API, 这里我们使用的是 http://www.vapsec.com/fenci/
、分词属性的说明文件下载 http://vdisk.weibo.com/s/qR7KSFDa9ON 或者 http://ishare.iask.sina.com.cn/f/68191875.html
这里已经写好了一个测试脚本。只是单个进程访问。还没有加入并发的测试。
在以后的测试中,我会加入并发的概念的。
下面是测试脚本 test.py
#!/usr/bin/env python
#coding: utf-8
import sys
import urllib
import urllib2
import os
import re
from datetime import datetime, timedelta def url_post(word='My name is Jake Anderson', geshi="json"):
url = "http://open.vapsec.com/segment/get_word"
postDict = {
"word":word,
"format":geshi
} postData = urllib.urlencode(postDict)
request = urllib2.Request(url, postData)
request.get_method = lambda : 'POST'
#request.add_header('Authorization', basic)
response = urllib2.urlopen(request)
r = response.readlines()
print r if __name__ == "__main__":
f = open('novel2.txt', 'r')
# get Chinese characters quantity
regex=re.compile(r"(?x) (?: [\w-]+ | [\x80-\xff]{3} )")
count = 0
for line in f:
line = line.decode('gbk')
line = line.encode('utf8')
word = [w for w in regex.split(line)]
count += len(word)
#print count
f = open('novel2.txt', 'r')
start_time = datetime.now()
for line in f:
line = line.decode('gbk')
line = line.encode('utf8')
word2 = [w for w in regex.split(line)]
print line
url_post(line)
end_time = datetime.now()
tdelta = start_time - end_time
print "It takes " + str(tdelta.total_seconds()) + " seconds to segment " + str(count) + " Chinese words!"
print "This means it can segment " + str(count/tdelta.total_seconds()) + " Chinese characters per second!"
novel2.txt 是下载的小说。这个小说1.2MB大小。大约有580000字吧。
小说是GBK的格式,所以下载后,要转码成 utf-8的格式。
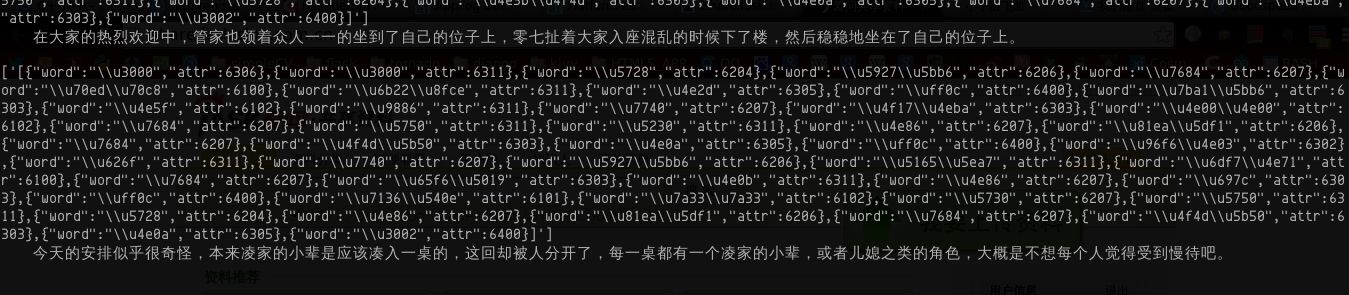
可以看到的终端效果大致是这样的。
把小说中所有的词,进行远程分词服务。
python 中文字数统计/分词的更多相关文章
- Python中文词频统计
以下是关于小说的中文词频统计 这里有三个文件,分别为novel.txt.punctuation.txt.meaningless.txt. 这三个是小说文本.特殊符号和无意义词 Python代码统计词频 ...
- Python 中文文件统计词频 + 中文词云
1. 词频统计: import jieba txt = open("threekingdoms3.txt", "r", encoding='utf-8').re ...
- PHP 中如何正确统计中文字数
PHP 中如何正确统计中文字数?这个是困扰我很久的问题,PHP 中有很多函数可以计算字符串的长度,比如下面的例子,分别使用了 strlen,mb_strlen,mb_strwidth 这个三个函数去测 ...
- Python中文分词组件 jieba
jieba "结巴"中文分词:做最好的Python中文分词组件 "Jieba" Feature 支持三种分词模式: 精确模式,试图将句子最精确地切开,适合文本分 ...
- jieba分词-强大的Python 中文分词库
1. jieba的江湖地位 NLP(自然语言)领域现在可谓是群雄纷争,各种开源组件层出不穷,其中一支不可忽视的力量便是jieba分词,号称要做最好的 Python 中文分词组件. 很多人学习pytho ...
- jieba (中文词频统计) 、collections (字频统计)、WordCloud (词云)
py库: jieba (中文词频统计) .collections (字频统计).WordCloud (词云) 先来个最简单的: # 查找列表中出现次数最多的值 ls = [1, 2, 3, 4, 5, ...
- 【原】python中文文本挖掘资料集合
这些网址是我在学习python中文文本挖掘时觉得比较好的网站,记录一下,后期也会不定期添加: 1.http://www.52nlp.cn/python-%E7%BD%91%E9%A1%B5%E7% ...
- Python中文字符的理解:str()、repr()、print
Python中文字符的理解:str().repr().print 字数1384 阅读4 评论0 喜欢0 都说Python人不把文字编码这块从头到尾.从古至今全研究通透的话是完全玩不转的.我终于深刻的理 ...
- Python实现代码统计工具——终极加速篇
Python实现代码统计工具--终极加速篇 声明 本文对于先前系列文章中实现的C/Python代码统计工具(CPLineCounter),通过C扩展接口重写核心算法加以优化,并与网上常见的统计工具做对 ...
随机推荐
- Quartz使用-入门使用(java定时任务实现)
注:这里使用的是Quartz1.6.5版本号(包:quartz-1.6.5.jar) //測试main函数 //QuartzTest.java package quartzPackage; impor ...
- UVA The Sultan's Successors
题目例如以下: The Sultan's Successors The Sultan of Nubia has no children, so she has decided that thecou ...
- MFC 界面编程 可参考资料
http://www.codeproject.com/Articles/26887/A-user-draw-button-that-supports-PNG-files-with-tr http:// ...
- Python什么是值或引用函数参数
这篇文章是Python前往遇到有疑问的功能. 下面一段是原有的基础教程Python函数. 按值传递參数和按引用传递參数 全部參数(自变量)在Python里都是按引用传递.假设你在函数里改动了參数,那么 ...
- Android性能优化:谈话Bitmap内存管理和优化
最近除了那些忙着项目开发的事情,目前正在准备我的论文.短的时间没有写博客,今晚难得想总结.只要有一点时间.因此,为了凑合用,行.唠叨罗嗦,直接进入正题. 从事Android自移动终端的发展,想必是常常 ...
- 在标记的HREF属性中javascript:alert(this.innerHTML)会怎么样?
原文:在标记的HREF属性中javascript:alert(this.innerHTML)会怎么样? <a href="javascript:alert(this.innerHTML ...
- Visual Studio 2013进行单元测试
使用Visual Studio 2013进行单元测试--初级篇 1.打开VS2013 --> 新建一个项目.这里我们默认创建一个控制台项目.取名为UnitTestDemo 2.在解决方案里面 ...
- [探索]点点轻博客搬家到WordPress(一)
摘要:点点博客备份XML通过DiandianToWordpress-beta.sh(文末给出)搬家到Wordpress博客 本人曾使用过点点轻博客,也深知像点点博客,Lofter博客导出的XML文件不 ...
- [翻译]初识SQL Server 2005 Reporting Services Part 3
原文:[翻译]初识SQL Server 2005 Reporting Services Part 3 这是关于SSRS文章中四部分的第三部分.Part 1提供了一个创建基本报表的递阶教程.Part 2 ...
- beanutils中WrapDynaBean
public class Emp { private String firstName="李"; private String lastName; public ...