和textrank4ZH代码一模一样的算法详细解读
前不久做了有关自动文摘的学习,采用方法是TextRank算法,整理和大家分享。
一. 关于自动文摘
利用计算机将大量的文本进行处理,产生简洁、精炼内容的过程就是文本摘要,人们可通过阅读摘要来把握文本主要内容,这不仅大大节省时间,更提高阅读效率。但人工摘要耗时又耗力,已不能满足日益增长的信息需求,因此借助计算机进行文本处理的自动文摘应运而生。近年来,自动文摘、信息检索、信息过滤、机器识别、等研究已成为了人们关注的热点。
自动文摘(Automatic Summarization)的方法主要有两种:Extraction和Abstraction。其中Extraction是抽取式自动文摘方法,通过提取文档中已存在的关键词,句子形成摘要;Abstraction是生成式自动文摘方法,通过建立抽象的语意表示,使用自然语言生成技术,形成摘要。由于生成式自动摘要方法需要复杂的自然语言理解和生成技术支持,应用领域受限。所以本人学习的也是抽取式的自动文摘方法。
目前主要方法有:
- 基于统计:统计词频,位置等信息,计算句子权值,再简选取权值高的句子作为文摘,特点:简单易用,但对词句的使用大多仅停留在表面信息。
- 基于图模型:构建拓扑结构图,对词句进行排序。例如,TextRank/LexRank
- 基于潜在语义:使用主题模型,挖掘词句隐藏信息。例如,采用LDA,HMM
- 基于整数规划:将文摘问题转为整数线性规划,求全局最优解。(~.~我也不懂)
二. TextRank算法
TextRank算法是一种用于文本的基于图的排序算法。其基本思想来源于谷歌的 PageRank算法, 通过把文本分割成若干组成单元(单词、句子)并建立图模型, 利用投票机制对文本中的重要成分进行排序, 仅利用单篇文档本身的信息即可实现关键词提取、文摘。和 LDA、HMM 等模型不同, TextRank不需要事先对多篇文档进行学习训练, 因其简洁有效而得到广泛应用。
TextRank 一般模型可以表示为一个有向有权图 G =(V, E), 由点集合 V和边集合 E 组成, E 是V ×V的子集。图中任两点 Vi , Vj 之间边的权重为 wji , 对于一个给定的点 Vi, In(Vi) 为 指 向 该 点 的 点 集 合 , Out(Vi) 为点 Vi 指向的点集合。点 Vi 的得分定义如下:
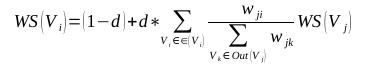 其中, d 为阻尼系数, 取值范围为 0 到 1, 代表从图中某一特定点指向其他任意点的概率, 一般取值为 0.85。使用TextRank 算法计算图中各点的得分时, 需要给图中的点指定任意的初值, 并递归计算直到收敛, 即图中任意一点的误差率小于给定的极限值时就可以达到收敛, 一般该极限值取 0.0001。
其中, d 为阻尼系数, 取值范围为 0 到 1, 代表从图中某一特定点指向其他任意点的概率, 一般取值为 0.85。使用TextRank 算法计算图中各点的得分时, 需要给图中的点指定任意的初值, 并递归计算直到收敛, 即图中任意一点的误差率小于给定的极限值时就可以达到收敛, 一般该极限值取 0.0001。
1. 基于TextRank的关键词提取
关键词抽取的任务就是从一段给定的文本中自动抽取出若干有意义的词语或词组。TextRank算法是利用局部词汇之间关系(共现窗口)对后续关键词进行排序,直接从文本本身抽取。其主要步骤如下:
(1)把给定的文本T按照完整句子进行分割,即
(2)对于每个句子
(3)构建候选关键词图G = (V,E),其中V为节点集,由(2)生成的候选关键词组成,然后采用共现关系(co-occurrence)构造任两点之间的边,两个节点之间存在边仅当它们对应的词汇在长度为K的窗口中共现,K表示窗口大小,即最多共现K个单词。
(4)根据上面公式,迭代传播各节点的权重,直至收敛。
(5)对节点权重进行倒序排序,从而得到最重要的T个单词,作为候选关键词。
(6)由(5)得到最重要的T个单词,在原始文本中进行标记,若形成相邻词组,则组合成多词关键词。例如,文本中有句子“Matlab code for plotting ambiguity function”,如果“Matlab”和“code”均属于候选关键词,则组合成“Matlab code”加入关键词序列。
2. 基于TextRank的自动文摘
基于TextRank的自动文摘属于自动摘录,通过选取文本中重要度较高的句子形成文摘,其主要步骤如下:
(1)预处理:将输入的文本或文本集的内容分割成句子得
(2)句子相似度计算:构建图G中的边集E,基于句子间的内容覆盖率,给定两个句子

若两个句子之间的相似度大于给定的阈值,就认为这两个句子语义相关并将它们连接起来,即边的权值
(3)句子权重计算:根据公式,迭代传播权重计算各句子的得分;
(4)抽取文摘句:将(3)得到的句子得分进行倒序排序,抽取重要度最高的T个句子作为候选文摘句。
(5)形成文摘:根据字数或句子数要求,从候选文摘句中抽取句子组成文摘。
三. 其它
分析研究可知,相似度的计算方法好坏,决定了关键词和句子的重要度排序,如果在相似度计算问题上有更好的解决方案,那么结果也会更加有效。其它计算相似度的方法有:基于编辑距离,基于语义词典,余弦相似度等。这里不一一描述。
本人实现了一个简单的文摘系统,代码可参考ASExtractor,代码风格比较坑爹,注释也没写好,将就看看,请见谅。
来源于:https://www.cnblogs.com/chenbjin/p/4600538.html
和textrank4ZH代码一模一样的算法详细解读的更多相关文章
- Madgwick算法详细解读
Madgwick算法详细解读 极品巧克力 前言 接上一篇文章<Google Cardboard的九轴融合算法>. Madgwick算法是另外一种九轴融合的方法,广泛应用在旋翼飞行器上,效果 ...
- A*寻路算法详细解读
文章目录 A*算法描述 简化搜索区域 概述算法步骤 进一步解释 具体寻路过程 模拟需要更新F值的情况 Lua代码实现 在学习A*算法之前,很好奇的是A*为什么叫做A*.在知乎上找到一个回答,大致意思是 ...
- 相机IMU融合四部曲(一):D-LG-EKF详细解读
相机IMU融合四部曲(一):D-LG-EKF详细解读 极品巧克力 前言 前两篇文章<Google Cardbord的九轴融合算法>,<Madgwick算法详细解读>,讨论的都是 ...
- 时空上下文视觉跟踪(STC)算法的解读与代码复现(转)
时空上下文视觉跟踪(STC)算法的解读与代码复现 zouxy09@qq.com http://blog.csdn.net/zouxy09 本博文主要是关注一篇视觉跟踪的论文.这篇论文是Kaihua Z ...
- SVO详细解读
SVO详细解读 极品巧克力 前言 接上一篇文章<深度滤波器详细解读>. SVO(Semi-Direct Monocular Visual Odometry)是苏黎世大学Scaramuzza ...
- AQS源码详细解读
AQS源码详细解读 目录 AQS源码详细解读 基础 CAS相关知识 通过标识位进行线程挂起的并发编程范式 MPSC队列的实现技巧 代码讲解 独占模式 独占模式下请求资源 独占模式下的释放资源 共享模式 ...
- 【UGUI源码分析】Unity遮罩之RectMask2D详细解读
遮罩,顾名思义是一种可以掩盖其它元素的控件.常用于修改其它元素的外观,或限制元素的形状.比如ScrollView或者圆头像效果都有用到遮罩功能.本系列文章希望通过阅读UGUI源码的方式,来探究遮罩的实 ...
- MemCache超详细解读
MemCache是什么 MemCache是一个自由.源码开放.高性能.分布式的分布式内存对象缓存系统,用于动态Web应用以减轻数据库的负载.它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高 ...
- MemCache超详细解读 图
http://www.cnblogs.com/xrq730/p/4948707.html MemCache是什么 MemCache是一个自由.源码开放.高性能.分布式的分布式内存对象缓存系统,用于 ...
随机推荐
- Caused by: java.net.ConnectException: Connection refused/Caused by: java.lang.RuntimeException: com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure
1.使用sqoop技术将mysql的数据导入到Hive出现的错误如下所示: 第一次使用命令如下所示: [hadoop@slaver1 sqoop--cdh5.3.6]$ bin/sqoop impor ...
- rabbitmq3.7.5 centos7 集群部署笔记
1. 准备3台 centos服务器 192.168.233.128 192.168.233.130 192.168.233.131 防火墙放开 集群端口, 这里一并把所有rabbitmq ...
- 第二种掌握的排序Q-Q
#include<stdio.h> int main() { int s[10000]={0}; int i=0,j=0,n=0,x=0; scanf(" ...
- nginx-fastcgi 反向代理
Nginx处理php页面 用fpm-server 基于fastcgi模块实现 Ngx_http_proxy_module 只能反代后端http server的主机 Ngx_fastcgi_prox ...
- Python学习(六) —— 函数
一.函数的定义和调用 为什么要用函数:例如,计算一个数据的长度,可以用一段代码实现,每次需要计算数据的长度都可以用这段代码,如果是一段代码,可读性差,重复代码多: 但是如果把这段代码封装成一个函数,用 ...
- 2n的 位数
len=())+,(2n−1同样适用)
- day31 网络编程,多进程多线程
今天的内容需要好好整理,概念性的东西比较多,都是需要理解的,这些是基层的理解,后期的很多知识都是要建立在今天的概念基础上的,以下两点是核心内容,必须要理解,自己把自己理解的注释加在里面: 进程就是程序 ...
- KMP算法2
给定一个主串s,一个子串sub,将主串中的所有子串替换成replaceStr,并将最终结果输出来. #include<stdio.h> #include<string.h> # ...
- 剑指offer 1,输入一个字符串,将字符串的空格替换成%20
剑指offer 1,输入一个字符串,将字符串的空格替换成%20 function replaceSpace(str){ return str.replace(/\s/g,"% ...
- ZOJ 3795 Grouping (强连通缩点+DP最长路)
<题目链接> 题目大意: n个人,m条关系,每条关系a >= b,说明a,b之间是可比较的,如果还有b >= c,则说明b,c之间,a,c之间都是可以比较的.问至少需要多少个集 ...