大数据学习笔记1-大数据处理架构Hadoop
Hadoop:一个开源的、可运行于大规模集群上的分布式计算平台。实现了MapReduce计算模型和分布式文件系统HDFS等功能,方便用户轻松编写分布式并行程序。
Hadoop生态系统:
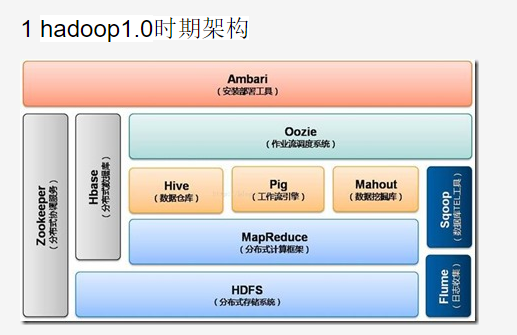
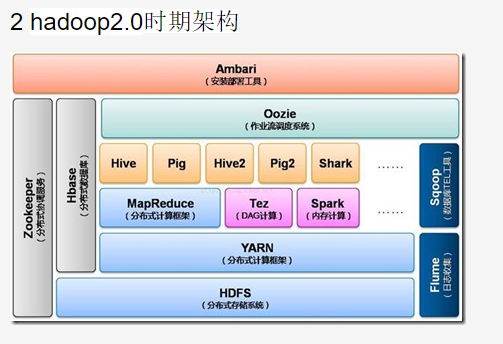
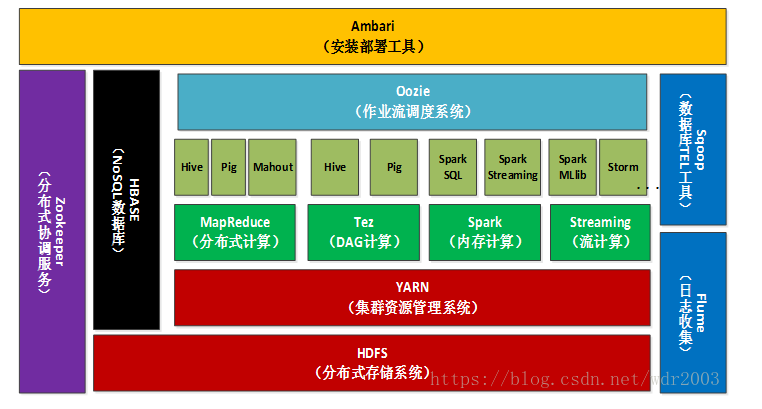
- HDFS:Hadoop 分布式文件系统,是Hadoop项目的两大核心之一。
- HBase:提供高可靠性、高性能、可伸缩、实时读写、分布式的列数据库,一般采用HDFS作为其底层数据存储,用于存储非结构化数据。
- MapReduce:一种并行编程模型,将复杂的、运行于大规模集群上的并行计算过程高度抽象到Map和Reduce上,方便用户进行分布式编程。MapReduce的核心思想是“分而治之”,把输入的数据集切分成若干独立的数据块,分发给集群中各个节点来共同完成。
- Hive:一个基于Hadoop的数据仓库工具,可以对Hadoop文件中的数据集进行数据整理、特殊查询和分析存储,提供类似关系数据库的查询语言。
- Pig:一种数据流语言和运行环境,适用于使用Hadoop和MapReduce平台来查询大型半结构化数据集。为了Hadoop应用程序提供了一种更加接近结构化查询语言(SQL)的接口,适用于从大型数据集中搜索满足某个给定搜索条件的记录。
- Mahout:提供一些可扩展的机器学习领域经典算法的实现,如聚类、分类、推荐过滤等。
- Zookeeper:高效且可靠的系统工作系统,提供分布式锁之类的基本服务(如统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等)。用于构建分布式应用,负责任务协调。
- Flume:一个高可用、高可靠、分布式的海量日志采集、聚合和传输的系统。
- Sqoop:(SQL-to-Hadoop)用于在Hadoop和关系数据之间交换数据,便于传统关系数据库与Hadoop之间的数据迁移。Sqoop可以方便地将数据从MySQL等关系数据库中导入Hadoop(可以导入HDFS、HBase或Hive),或者将数据从Hadoop导出到关系数据。
- Ambari:一种基于Web的工具,支持Hadoop集群的安装、部署、配置和管理。
大数据时代的主要任务就是发现海量数据中的价值,为达到这一目的,首先要做的就是对这些数据进行存储,记录数据本身,接下来就是对手里的海量数据进行处理,发现其中价值。因此,大规模数据集的处理包括分布式存储和分布式计算两个核心环节,用于解决大数据领域中两方面问题,一个是大规模数据的高效存储与管理问题,针对这一问题Hadoop主要采用HDFS、NoSQL等对数据进行存储;另一个是大规模数据的高效处理问题,针对这一问题的主要技术包括MapReduce,
分布式并行编程可以大幅度提高程序性能,实现高效的批量数据处理。MapReduce是一种并行编程模型,、用于大规模数据集的并行运算,它将大规模集群上的并行计算过程高度抽象到Map和Reduce两个函数中,极大地方便了分布式并行编程工作。
大数据学习笔记1-大数据处理架构Hadoop的更多相关文章
- 大数据学习笔记——Java篇之集合框架(ArrayList)
Java集合框架学习笔记 1. Java集合框架中各接口或子类的继承以及实现关系图: 2. 数组和集合类的区别整理: 数组: 1. 长度是固定的 2. 既可以存放基本数据类型又可以存放引用数据类型 3 ...
- 大数据学习笔记之Hadoop(一):Hadoop入门
文章目录 大数据概论 一.大数据概念 二.大数据的特点 三.大数据能干啥? 四.大数据发展前景 五.企业数据部的业务流程分析 六.企业数据部的一般组织结构 Hadoop(入门) 一 从Hadoop框架 ...
- 大数据学习笔记——Hadoop编程实战之HDFS
HDFS基本API的应用(包含IDEA的基本设置) 在上一篇博客中,本人详细地整理了如何从0搭建一个HA模式下的分布式Hadoop平台,那么,在上一篇的基础上,我们终于可以进行编程实操了,同样,在编程 ...
- 大数据学习笔记——Linux完整部署篇(实操部分)
Linux环境搭建完整操作流程(包含mysql的安装步骤) 从现在开始,就正式进入到大数据学习的前置工作了,即Linux的学习以及安装,作为运行大数据框架的基础环境,Linux操作系统的重要性自然不言 ...
- 大数据学习笔记——Linux基本知识及指令(理论部分)
Linux学习笔记整理 上一篇博客中,我们详细地整理了如何从0部署一套Linux操作系统,那么这一篇就承接上篇文章,我们仔细地把Linux的一些基础知识以及常用指令(包括一小部分高级命令)做一个梳理, ...
- 大数据学习笔记——Java篇之IO
IO学习笔记整理 1. File类 1.1 File对象的三种创建方式: File对象是一个抽象的概念,只有被创建出来之后,文件或文件夹才会真正存在 注意:File对象想要创建成功,它的目录必须存在! ...
- 大数据学习笔记——Java篇之基础知识
Java / 计算机基础知识整理 在进行知识梳理同时也是个人的第一篇技术博客之前,首先祝贺一下,经历了一年左右的学习,从完完全全的计算机小白,现在终于可以做一些产出了!可以说也是颇为感慨,个人认为,学 ...
- 大数据学习笔记之初识Hadoop
1.Hadoop概述 1.1 Hadoop名字的由来 Hadoop项目作者的孩子给一个棕黄色的大象样子的填充玩具的命名 Hadoop的官网:http://hadoop.apache.org . 1.2 ...
- 大数据学习笔记之Hadoop(三):MapReduce&YARN
文章目录 一 MapReduce概念 1.1 为什么要MapReduce 1.2 MapReduce核心思想 1.3 MapReduce进程 1.4 MapReduce编程规范(八股文) 1.5 Ma ...
随机推荐
- MySQL8.0 关闭二进制日志
Binary logging is enabled by default (the log_bin system variable is set to ON). The exception is if ...
- robot framework程序运行过程中,遇到点击事件之后,未出现点击之后的效果(求解)
1.click Element操作,在实际过程中偶然会出现,日志显示已点击成功,但是实际自动化页面,没有点击成功之后的操作 现象: 现象描述:程序执行到点击侧边栏的[人员信息]之后,日志显示已经点击成 ...
- Xshell添加ssh隧道SOCKS代理
Xshell是一个功能强大的终端模拟器,支持SSH,SFTP.TELNET.RLOGIN和SERIAL 下载地址:http://www.netsarang.com/products/xsh_overv ...
- 随机数的组合问题(JavaScript描述)
随机数的组合问题在面试时是经常考的,比如之前我就被问到:“有一个可以生成1-5的随机数函数,怎样把它扩大到1-7?” 在解决这个问题之前,先来看看另外一个比较简单的问题:“有一个可以生成1-7的函数, ...
- 汉语言处理工具pyhanlp的拼音转换与字符正则化
汉字转拼音 HanLP中的汉字转拼音功能也十分的强大. 说明: l HanLP不仅支持基础的汉字转拼音,还支持声母.韵母.音调.音标和输入法首字母首声母功能. l HanLP能够识别多音字,也能给繁体 ...
- repository test has failed 错误
这里给自己一个警告,当我在idea中准备clone gitlab上的项目时,这个链接竟然一直在报:repository test has failed 错误 这个是gitlab上复制下来的原链接:ht ...
- BCC校验小知识
BCC校验其实是奇偶校验的一种,但也是经常使用并且效率较高的一种.所谓BCC校验法,就是在发送前和发送后分别把BCC以前包括ETX字符的所有字符按位异或后,按要求变换(增加或去除一个固定的值)后所得到 ...
- 一键精简Windows不常用的字体.cmd
一键精简Windows不常用的字体.cmd @Echo offset path=%path%;%~dp0setlocal EnableDelayedExpansionset /P dv=请输入要精简W ...
- C#编程经验-function advanced params
function advanced params:outrefparamsnot useful,to use them is a burden,so i dont use themdefects:ou ...
- 阿里云ECS配置iptables
在阿里云ECS安装flannel.docker.kubernetes后,在多个node运行docker run -it bash,然后ping互相的ip,发现docker容器间网络没通,发现宿主机的i ...