二叉查找树,AVL树,伸展树【CH4601普通平衡树】
最近数据结构刚好看到了伸展树,在想这个东西有什么应用,于是顺便学习一下。
二叉查找树(BST),对于树上的任意一个节点,节点的左子树上的关键字都小于这个节点的关键字,节点的右子树上的关键字都大于这个节点的关键字。
对二叉查找树进行中序遍历,可以得到一个有序的序列。
下面这些操作的期望复杂度是$O(log N)$,但是如果BST中的数据是有序的序列BST就会变成一条链,复杂度会退化成$O(N)$
为了避免越界减少边界情况的特殊判断,一般在BST中额外插入一个关键码为正无穷和一个关键码为负无穷的节点。
struct BST {
int l, r;
int val;
}a[SIZE];
int tot, root, INF = << ;
int NEW(int val)
{
a[++tot].val = val;
return tot;
}
void build()
{
NEW(-INF), NEW(INF);
root = ;
a[].r = ;
}
检索时,如果当前节点p的关键字等于val,则已经找到。
如果p的关键字大于val,如果p的左子节点为空说明val不存在,否则在p的左子树中递归进行检索。
如果p的关键字小于val,如果p的右子节点为空说明val不存在,否则在p的右子树中递归进行检索。
int Get(int p, int val)
{
if(p == )return ;
if(val == a[p].val)return p;
return val < a[p].val ? Get(a[p].l, val) : Get(a[p].r, val);
}
插入时,先执行检索操作,知道发现走向的p的子节点为空说明val不存在时,直接建立新节点。
void Insert(int &p, int val)
{
if(p == ){
p = New(val);
return;
}
if(val == a[p].val) return;
if(val < a[p].val) Insert(a[p].l, val);
else Insert(a[p].r, val);
}
val的后继指的是在BST中关键码大于val的前提下,关键码最小的节点。
求后继的过程:初始化ans为具有正无穷关键码的那个节点的编号,然后在BST中检索val。检索过程中,每经过一个点,看看能不能更新ans
当检索完成后,可能没有找到val,此时ans就是答案。
也有可能找到了关键字是val的节点p,但是p没有右子树,那么ans也就是答案。
也有可能是p有右子树,那么说明val的后继不是在刚刚已经经过的那些节点中,所以还要从p的右子节点出发,一直往左走。
nt GetNext(int val)
{
int ans = ;
int p = root;
while(p){
if(val == a[p].val){
if(a[p].r > ){
p = a[p].r;
while(a[p].l > ) p = a[p].l;
ans = p;
}
break;
}
if(a[p].val > val && a[p].val < a[ans].val)ans = p;
p = val < a[p].val ? a[p].l : a[p].r;
}
return ans;
}
删除节点时,也需要先检索val得到节点p。
如果p的孩子只有一个,那么可以直接删除,让p的子节点代替p。
如果p的孩子有两个,就需要在BST中找到val的后继节点nxt。
因为nxt没有左子树,所以可以直接让nxt的右子树代替nxt,然后让nxt代替p。
void remove(int val)
{
int &p = root;
while(p){
if(val == a[p].val) break;
p = val < a[p].val ? a[p].l : a[p].r;
}
if(p == )return ;
if(a[p].l == ){
p = a[p].r;
}
else if(a[p].r == ){
p = a[p].l;
}
else{
int nxt = a[p].r;
while(a[nxt].l > )nxt = a[nxt].l;
remove(a[nxt].val);
a[nxt].l = a[p].l, a[nxt].r = a[p].r;
p = nxt;
}
}
AVL树,是带有平衡条件的二叉查找树。
每个节点的左子树和右子树的高度最多差1。这样就可以使整棵树的深度维持在$O(log N)$
要维持平衡的条件,主要改变的是插入时的操作。
当我们插入了一个节之后,某一条路径上的节点有可能平衡条件被破坏,这时候我们就需要进行旋转操作使他们重新达到平衡条件。
插入时,沿着节点到根更新平衡信息,找到第一个平衡被破坏了的节点(最深的一个)a。
a的两棵子树的高度差2,如果是对a的左儿子的左子树或a的右儿子的右子树进行插入,那么只用进行一次单旋转。
比如这样: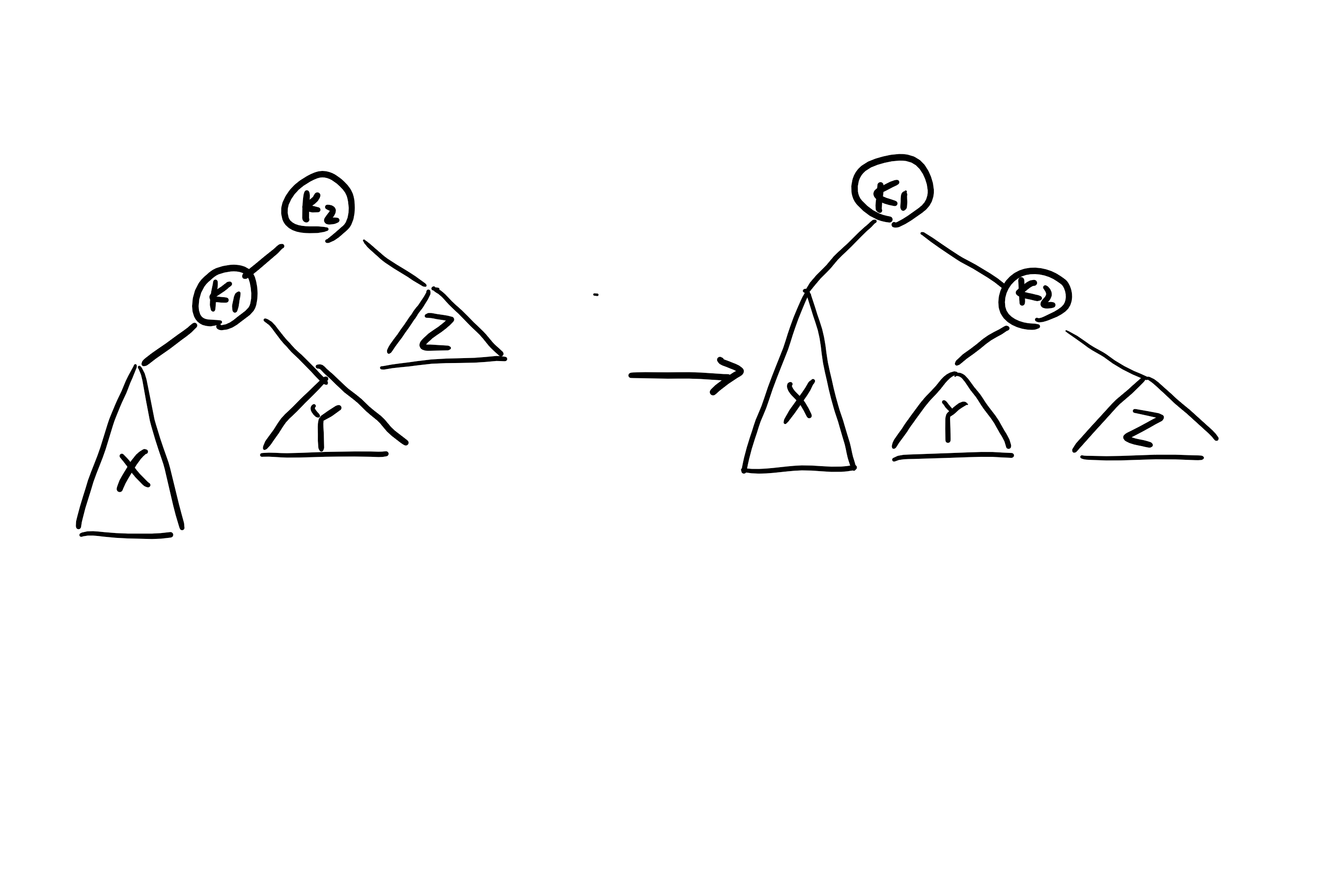

如果是对a的左儿子的右子树或是a的右儿子的左子树进行插入,需要进行一次双旋转。而实际上就是先将k1与k2进行一次旋转,再与k3旋转。
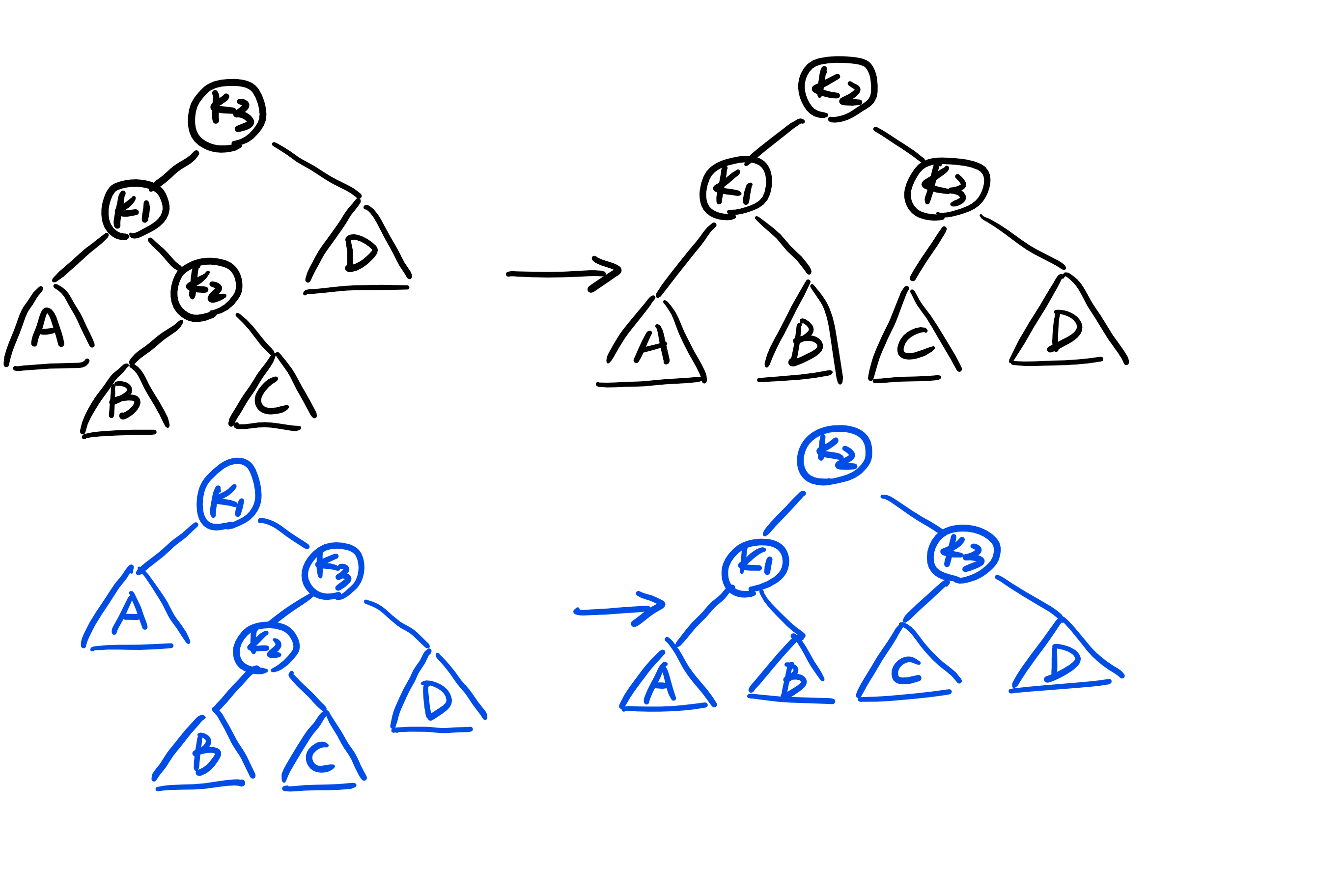
右旋就是把k1变成k2的父节点,k2作为k1的右子节点。zig(p)可以理解成把p的左子节点绕着p向右旋转。
void zig(int &p)
{
int q = a[p].l;
a[p].l = a[q].r, a[q].r = p;
p = q;
}
左旋zag(p)可以理解成把p的右子节点绕着p向左旋转。
void zag(int &p)
{
int q = a[p].r;
a[p].r = a[q].l, a[q].l = p;
p = q;
}
删除操作时,由于支持旋转,我们可以直接找到需要删除的节点,把他旋转成叶节点后直接删除。
伸展树(spaly tree),保证从空树开始任意连续M次对树的操作最多花费$O(M log N)$时间,但是并不排除任意一次操作花费$O(N)$时间的可能。
当一个节点被访问,就将他移动到根上。称为Splay操作。
Spaly操作:令X是在访问路径上的一个(非根)节点,如果X的父节点是树根,就只需要旋转X和树根。
否则分两种情况。

举个书上的习题作为例子。

在实际应用中,我们可以用伸展树维护一些区间的操作。
比如我们要提取区间[a,b],那么我们将a前面一个数对应的结点转到树根,将b 后面一个结点对应的结点转到树根的右边,那么根右边的左子树就对应了区间[a,b]。
与线段树相比,伸展树功能更强大,它能解决以下两个线段树不能解决的问题:
(1) 在a后面插入一些数。方法是:首先利用要插入的数构造一棵伸展树,接着,将a 转到根,并将a 后面一个数对应的结点转到根结点的右边,最后将这棵新的子树挂到根右子结点的左子结点上。
(2) 删除区间[a,b]内的数。首先提取[a,b]区间,直接删除即可。
关于伸展树的实现代码可以参考kuangbin博客中的转载
CH上有一道模板例题
http://contest-hunter.org:83/contest/0x40「数据结构进阶」例题/4601%20普通平衡树
要求实现一下六种操作:
1. 插入x数
2. 删除x数(若有多个相同的数,因只删除一个)
3. 查询x数的排名(若有多个相同的数,因输出最小的排名)
4. 查询排名为x的数
5. 求x的前驱(前驱定义为小于x,且最大的数)
6. 求x的后继(后继定义为大于x,且最小的数)
因为给的数可能会重复,而删除时只能删除一个,所以用cnt来记录这个值出现了的次数。
还要求查询排名,所以给节点增加一个size属性,记录以该节点为根的子树中所有节点的cnt之和。
在插入、删除和旋转时从下往上更新size信息。
//#include<bits/stdc++>
#include<stdio.h>
#include<iostream>
#include<algorithm>
#include<cstring>
#include<stdlib.h>
#include<queue>
#include<map>
#include<stack>
#include<set> #define LL long long
#define ull unsigned long long
#define inf 0x3f3f3f3f using namespace std; const int SIZE = 1e5 + ;
struct Treap{
int l, r;
int val, dat;
int cnt, size;
}a[SIZE];
int tot, root, n, INF = 0x7fffffff; int New(int val)
{
a[++tot].val = val;
a[tot].dat = rand();
a[tot].cnt = a[tot].size = ;
return tot;
} void Update(int p)
{
a[p].size = a[a[p].l].size + a[a[p].r].size + a[p].cnt;
} void build()
{
New(-INF), New(INF);
root = , a[].r = ;
Update(root);
} int GetRankByVal(int p, int val)
{
if(p == )return ;
if(val == a[p].val) return a[a[p].l].size + ;
if(val < a[p].val)return GetRankByVal(a[p].l, val);
return GetRankByVal(a[p].r, val) + a[a[p].l].size + a[p].cnt;
} int GetValByRank(int p, int rank)
{
if(p == )return INF;
if(a[a[p].l].size >= rank)return GetValByRank(a[p].l, rank);
if(a[a[p].l].size + a[p].cnt >= rank)return a[p].val;
return GetValByRank(a[p].r, rank - a[a[p].l].size - a[p].cnt);
} void zig(int &p)
{
int q = a[p].l;
a[p].l = a[q].r;
a[q].r = p;
p = q;
Update(a[p].r);
Update(p);
} void zag(int &p)
{
int q = a[p].r;
a[p].r = a[q].l;
a[q].l = p;
p = q;
Update(a[p].l);
Update(p);
} void Insert(int &p, int val)
{
if(p == ){
p = New(val);
return;
}
if(val == a[p].val){
a[p].cnt++;
Update(p);
return;
}
if(val < a[p].val){
Insert(a[p].l, val);
if(a[p].dat < a[a[p].l].dat)zig(p);//不满足堆性质,右旋
}
else{
Insert(a[p].r, val);
if(a[p].dat < a[a[p].r].dat)zag(p);//不满足堆性质,左旋
}
Update(p);
} int GetPre(int val)
{
int ans = ;
int p = root;
while(p){
if(val == a[p].val){
if(a[p].l > ){
p = a[p].l;
while(a[p].r > )p = a[p].r;
ans = p;
}
break;
}
if(a[p].val < val && a[p].val > a[ans].val) ans = p;
p = val < a[p].val?a[p].l : a[p].r;
}
return a[ans].val;
} int GetNext(int val)
{
int ans = ;
int p = root;
while(p){
if(val == a[p].val){
if(a[p].r > ){
p = a[p].r;
while(a[p].l > )p = a[p].l;
ans = p;
}
break;
}
if(a[p].val > val && a[p].val < a[ans].val )ans = p;
p = val < a[p].val ? a[p].l : a[p].r;
}
return a[ans].val;
} void Remove(int &p, int val)
{
if(p == )return;
if(val == a[p].val){
if(a[p].cnt > ){
a[p].cnt--;
Update(p);
return;
}
if(a[p].l || a[p].r){
if(a[p].r == || a[a[p].l].dat > a[a[p].r].dat){
zig(p);
Remove(a[p].r, val);
}
else {
zag(p);
Remove(a[p].l, val);
}
Update(p);
}
else p = ;
return;
}
val < a[p].val ? Remove(a[p].l, val) : Remove(a[p].r, val);
Update(p);
} int main()
{
build();
cin>>n;
while(n--){
int opt, x;
scanf("%d%d", &opt, &x);
switch(opt){
case :
Insert(root, x);
break;
case :
Remove(root, x);
break;
case :
printf("%d\n", GetRankByVal(root, x) - );
break;
case :
printf("%d\n", GetValByRank(root, x + ));
break;
case :
printf("%d\n", GetPre(x));
break;
case :
printf("%d\n", GetNext(x));
break;
}
}
return ;
}
二叉查找树,AVL树,伸展树【CH4601普通平衡树】的更多相关文章
- AVL树、splay树(伸展树)和红黑树比较
AVL树.splay树(伸展树)和红黑树比较 一.AVL树: 优点:查找.插入和删除,最坏复杂度均为O(logN).实现操作简单 如过是随机插入或者删除,其理论上可以得到O(logN)的复杂度,但是实 ...
- 树-伸展树(Splay Tree)
伸展树概念 伸展树(Splay Tree)是一种二叉排序树,它能在O(log n)内完成插入.查找和删除操作.它由Daniel Sleator和Robert Tarjan创造. (01) 伸展树属于二 ...
- 二叉树、红黑树、伸展树、B树、B+树
好多树啊,程序猿砍树记,吼吼. 许多程序要解决的关键问题是:快速定位特定排序项的能力. 第一类:散列 第二类:字符串查找 第三类:树算法 树算法可以在辅助存储器中存储大量的数据. 二叉树.红黑树和伸展 ...
- 伸展树(Splay tree)的基本操作与应用
伸展树的基本操作与应用 [伸展树的基本操作] 伸展树是二叉查找树的一种改进,与二叉查找树一样,伸展树也具有有序性.即伸展树中的每一个节点 x 都满足:该节点左子树中的每一个元素都小于 x,而其右子树中 ...
- [转] Splay Tree(伸展树)
好久没写过了,比赛的时候就调了一个小时,差点悲剧,重新复习一下,觉得这个写的很不错.转自:here Splay Tree(伸展树) 二叉查找树(Binary Search Tree)能够支持多种动态集 ...
- [SinGuLaRiTy] SplayTree 伸展树
[SinGuLaRiTy-1010]Copyrights (c) SinGuLaRiTy 2017. All Rights Reserved. Some Method Are Reprinted Fr ...
- 二叉树总结(五)伸展树、B-树和B+树
一.伸展树 伸展树(Splay Tree)是一种二叉排序树,它能在O(log n)内完成插入.查找和删除操作. 因为,它是一颗二叉排序树,所以,它拥有二叉查找树的性质:除此之外,伸展树还具有的一个特点 ...
- Splay(区间翻转)&树套树(Splay+线段树,90分)
study from: https://tiger0132.blog.luogu.org/slay-notes P3369 [模板]普通平衡树 #include <cstdio> #inc ...
- 数据结构图解(递归,二分,AVL,红黑树,伸展树,哈希表,字典树,B树,B+树)
递归反转 二分查找 AVL树 AVL简单的理解,如图所示,底部节点为1,不断往上到根节点,数字不断累加. 观察每个节点数字,随意选个节点A,会发现A节点的左子树节点或右子树节点末尾,数到A节点距离之差 ...
随机推荐
- c# System.Threading.Thread
using System; using System.Threading; // Simple threading scenario: Start a static method running // ...
- python - Linux C调用Python 函数
1.Python脚本,名称为py_add.py def add(a=,b=): print('Function of python called!') print('a = ',a) print('b ...
- Flutter Android 真机调试指南
操作预览: 准备一条数据线,并连接电脑和手机: 使用 flutter devices 查看设备能否找到: 在 Android studio 中选择你的真机,然后点击 [debug]: 真机自动安装Ap ...
- 【转载】MapReduce编程 Intellij Idea配置MapReduce编程环境
目录(?)[-] 一软件环境 二创建maven工程 三添加maven依赖 四配置log4j 五启动Hadoop 六运行WordCount从本地读取文件 七运行WordCount从HDFS读取文件 八代 ...
- 【转载】vi/vim使用进阶: 指随意动,移动如飞 (一)
vi/vim使用进阶: 指随意动,移动如飞 (一) << 返回vim使用进阶: 目录 本节所用命令的帮助入口: :help usr_03.txt :help motion.txt :hel ...
- 程序猿必备的8款web前端开发插件三
1.HTML5 Canvas 3D波浪翻滚动画 之前我们分享过好几款基于HTML5 Canvas的波浪和水波纹动画,比如这款HTML5 3D波浪起伏动画特效和这款超酷无比的HTML5 WebGL水面水 ...
- Delphi目录监控、目录监听
资料地址: 1.https://www.cnblogs.com/studypanp/p/4890970.html 单元代码: (************************************ ...
- Hibernate获取数据java.lang.StackOverflowError
原因:因为在重写toString()方法时,把关联的属性也放入到toString方法中了,去掉就可以了. 如:重写的toString方法中不能有关联关系IDCard属性idCard public cl ...
- mongodb应用
一.概述 NoSQL,指的是非关系型的数据库.NoSQL有时也称作Not Only SQL的缩写,是对不同于传统的关系型数据库的数据库管理系统的统称.NoSQL用于超大规模数据的存储.(例如谷歌或Fa ...
- nginx学习与使用
安装与运行 (从源码安装,这里OS为Ubuntu,参考资料:https://nginx.org/en/docs/configure.html) 1.下载并解压:https://nginx.org/en ...