spark streaming 整合kafka(二)
转载:https://www.iteblog.com/archives/1326.html
和基于Receiver接收数据不一样,这种方式定期地从Kafka的topic+partition中查询最新的偏移量,再根据定义的偏移量范围在每个batch里面处理数据。当作业需要处理的数据来临时,spark通过调用Kafka的简单消费者API读取一定范围的数据。这个特性目前还处于试验阶段,而且仅仅在Scala和Java语言中提供相应的API。
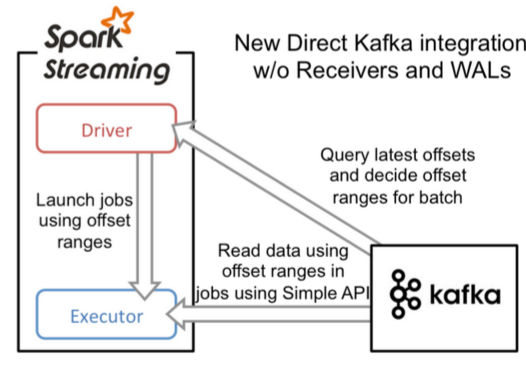
和基于Receiver方式相比,这种方式主要有一些几个优点:
(1)、简化并行。我们不需要创建多个Kafka 输入流,然后union他们。而使用directStream,Spark Streaming将会创建和Kafka分区一样的RDD分区个数,而且会从Kafka并行地读取数据,也就是说Spark分区将会和Kafka分区有一一对应的关系,这对我们来说很容易理解和使用;
(2)、高效。第一种实现零数据丢失是通过将数据预先保存在WAL中,这将会复制一遍数据,这种方式实际上很不高效,因为这导致了数据被拷贝两次:一次是被Kafka复制;另一次是写到WAL中。但是本文介绍的方法因为没有Receiver,从而消除了这个问题,所以不需要WAL日志;
(3)、恰好一次语义(Exactly-once semantics)。文章中通过使用Kafka高层次的API把偏移量写入Zookeeper中,这是读取Kafka中数据的传统方法。虽然这种方法可以保证零数据丢失,但是还是存在一些情况导致数据会丢失,因为在失败情况下通过Spark Streaming读取偏移量和Zookeeper中存储的偏移量可能不一致。而本文提到的方法是通过Kafka低层次的API,并没有使用到Zookeeper,偏移量仅仅被Spark Streaming保存在Checkpoint中。这就消除了Spark Streaming和Zookeeper中偏移量的不一致,而且可以保证每个记录仅仅被Spark Streaming读取一次,即使是出现故障。
但是本方法唯一的坏处就是没有更新Zookeeper中的偏移量,所以基于Zookeeper的Kafka监控工具将会无法显示消费的状况。然而你可以通过Spark提供的API手动地将偏移量写入到Zookeeper中。如何使用呢?其实和方法一差不多
1、引入依赖。
对于Scala和Java项目,你可以在你的pom.xml文件引入以下依赖:
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka_2.10</artifactId> <version>1.3.0</version></dependency> |
如果你是使用SBT,可以这么引入:
libraryDependencies += "org.apache.spark" % "spark-streaming-kafka_2.10" % "1.3.0" |
2、编程
在Streaming应用程序代码中,引入KafkaUtils ,并创建DStream输入流:
import org.apache.spark.streaming.kafka._val directKafkaStream = KafkaUtils.createDirectStream[ [key class], [value class], [key decoder class], [value decoder class] ]( streamingContext, [map of Kafka parameters], [set of topics to consume]) |
在 Kafka parameters参数中,你必须指定 metadata.broker.list或者bootstrap.servers参数。在默认情况下,Spark Streaming将会使用最大的偏移量来读取Kafka每个分区的数据。如果你配置了auto.offset.reset为smallest,那么它将会从最小的偏移量开始消费。
当然,你也可以使用KafkaUtils.createDirectStream的另一个版本从任意的位置消费数据。如果你想回去每个batch中Kafka的偏移量,你可以如下操作:
directKafkaStream.foreachRDD { rdd => val offsetRanges = rdd.asInstanceOf[HasOffsetRanges] // offsetRanges.length = # of Kafka partitions being consumed ...} |
你可以通过这种方式来手动地更新Zookeeper里面的偏移量,使得基于Zookeeper偏移量的Kafka监控工具可以使用。
注意到 HasOffsetRanges的类型转换仅仅在第一个被directKafkaStream调用的方法成功后,为了获得 offset 使用 transform() 代替 foreachRDD()方法,然后进一步调用spark方法,要意识到在RDD分区和Kafka分区之间是一对一关系所以获得offset方法不能保留在 shuffle 或者repartition之后,比如reduceByKey() 或者 windows().
另一个要注意的地方因为这个方法没有receivers方法,所以与接收器相关联的配置不起任何作用,代替的使用 spark.streaming.kafka.*.配置,一个比较重要的配置是利用直接读取的api 从Kafka的每个分区 每秒钟读取的数据量 spark.streaming.kafka.maxRatePerPartition。
spark streaming 整合kafka(二)的更多相关文章
- Spark学习之路(十六)—— Spark Streaming 整合 Kafka
一.版本说明 Spark针对Kafka的不同版本,提供了两套整合方案:spark-streaming-kafka-0-8和spark-streaming-kafka-0-10,其主要区别如下: s ...
- Spark 系列(十六)—— Spark Streaming 整合 Kafka
一.版本说明 Spark 针对 Kafka 的不同版本,提供了两套整合方案:spark-streaming-kafka-0-8 和 spark-streaming-kafka-0-10,其主要区别如下 ...
- spark streaming 整合 kafka(一)
转载:https://www.iteblog.com/archives/1322.html Apache Kafka是一个分布式的消息发布-订阅系统.可以说,任何实时大数据处理工具缺少与Kafka整合 ...
- Spark之 Spark Streaming整合kafka(并演示reduceByKeyAndWindow、updateStateByKey算子使用)
Kafka0.8版本基于receiver接受器去接受kafka topic中的数据(并演示reduceByKeyAndWindow的使用) 依赖 <dependency> <grou ...
- Spark之 Spark Streaming整合kafka(Java实现版本)
pom依赖 <properties> <scala.version>2.11.8</scala.version> <hadoop.version>2.7 ...
- spark streaming整合kafka
版本说明:spark:2.2.0: kafka:0.10.0.0 object StreamingDemo { def main(args: Array[String]): Unit = { Logg ...
- Spark Streaming 整合 Kafka
一:通过设置检查点,实现单词计数的累加功能 object StatefulKafkaWCnt { /** * 第一个参数:聚合的key,就是单词 * 第二个参数:当前批次产生批次该单词在每一个分区出现 ...
- Spark Streaming和Kafka整合是如何保证数据零丢失
转载:https://www.iteblog.com/archives/1591.html 当我们正确地部署好Spark Streaming,我们就可以使用Spark Streaming提供的零数据丢 ...
- Spark Streaming和Kafka整合保证数据零丢失
当我们正确地部署好Spark Streaming,我们就可以使用Spark Streaming提供的零数据丢失机制.为了体验这个关键的特性,你需要满足以下几个先决条件: 1.输入的数据来自可靠的数据源 ...
随机推荐
- POJ 2689 - Prime Distance - [埃筛]
题目链接:http://poj.org/problem?id=2689 Time Limit: 1000MS Memory Limit: 65536K Description The branch o ...
- 可视化&地图__公司收集
原文地址:https://github.com/zhongcaiwei/Data-visualization-technology-sharing 一.数据可视化企业(部分) 数字冰雹 光启元-腾讯 ...
- 【摘】Fiddler工具使用介绍
摘自:https://www.cnblogs.com/miantest/p/7289694.html Fiddler基础知识 Fiddler是强大的抓包工具,它的原理是以web代理服务器的形式进行工作 ...
- asp.net NPOI导出xlsx格式文件,打开文件报“Excel 已完成文件级验证和修复。此工作簿的某些部分可能已被修复或丢弃”
NPOI导出xlsx格式文件,会出现如下情况: 点击“是”: 导出代码如下: /// <summary> /// 将datatable数据写入excel并下载 /// </summa ...
- mysql 目录
初识数据库 mysql 初识sql语句 mysql 操作sql语句 mysql 数据库操作 mysql 数据表操作 mysql 数据操作 mysql 权限管理 mysql内置功能之视图.触发器.事务. ...
- OrbSLAM2采集点云数据
因为条件限制,在Windows10平台下实现OrbSLAM2+Kinect2点云数据采集. 1. 遇到问题,启动运行没多久就跟丢了,有的地方哪怕轻微的旋转甚至不动都无法跟踪. 原因:相机的标定参数不对 ...
- WinDBG相关
WinDBG 技巧:如何生成Dump 文件(.dump 命令) 程序崩溃(crash)的时候, 为了以后能够调试分析问题, 可以使用WinDBG要把当时程序内存空间数据都保存下来,生成的文件称为d ...
- Hadoop 集群的三种方式
1,Local(Standalone) Mode 单机模式 $ mkdir input $ cp etc/hadoop/*.xml input $ bin/hadoop jar share/hadoo ...
- 20175208 《Java程序设计》第四周学习总结
第五章主要学习内容 1.子类的继承性: (1)子类与父类在同一包中的继承性:子类自然地继承了其父类中不是private的成员变量作为自己的成员变量. (2)子类与父类不在同一包中的继承性:子类只继承父 ...
- Solr入门介绍
solr入门案例 solr是apache下的一个全文检索引擎系统. 我们需要在服务器上单独去部署solr, 通过它的客户端工具包solrJ, 就是一个 jar包, 集成到我们项目中来调用服务器中 ...