Web服务并发I/O模型
I/O模型:
阻塞型、非阻塞型、复用型、信号驱动型、异步
同步/异步:
关注消息通知机制
消息通知:
同步:等待对方返回消息
异步:被调用者通过状态、通知或回调机制通知调用者被调用者的运行状态
阻塞/非阻塞:
关注调用者在等待结果返回之前所处的状态
阻塞:blocking,调用结果返回之前,调用者被挂起。此时进程处于睡眠态
非阻塞:noblocking,调用结果返回之前,调用者不会被挂起。此时进程处于忙等
那么I/O模型组合有三种:
同步阻塞型:
同步非阻塞型:
异步非阻塞型:
一次文件IO请求,都会有两个阶段组成
第一步:等待数据,即数据从磁盘到内核内存
第二步:复制数据,即数据内核内存到进程内存。
下面三个走的是同步机制:
阻塞型I/O:两个阶段都是阻塞的
非阻塞型I/O:第一个阶段是非阻塞,但是第二个阶段仍然是阻塞型的。
复用型I/O:两个阶段都是阻塞的,但是他们没有阻塞在一个单路的I/O上,而是阻塞在内核的I/O复用器上。这两者阻塞的位置不一样。
下面这一个走的异步机制:
信号驱动型:第一个阶段是非阻塞,但是第二个阶段仍然是阻塞型的。不过有一个回调通知接口。算不上完全的异步。
真正的异步机制:
异步:两个阶段都是异步的。
复用型IO调用的两种:
1)select():1024
2)poll():
信号驱动型IO:
1)epoll(Linux):libevent
2)Kqueue(BSD):
3)/dev/poll(solaris)
我们用一幅图来讲解
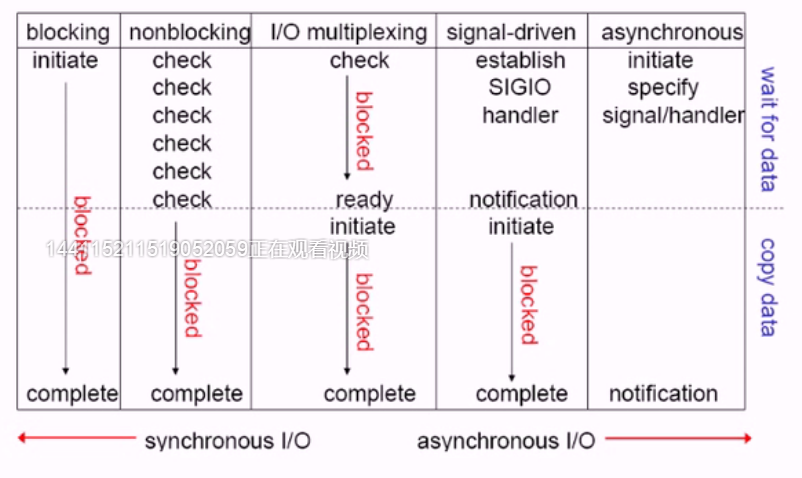
从网上找了一段,感觉还不错:
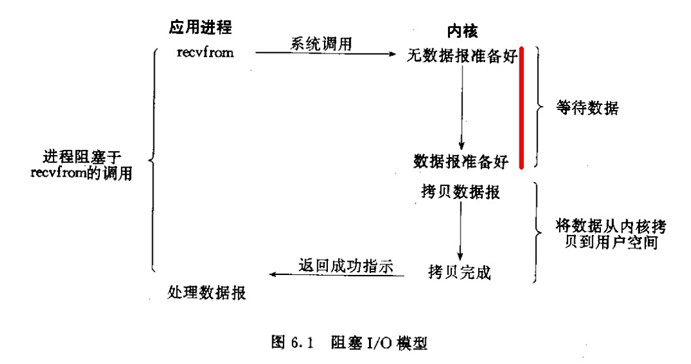
同步与异步 同步和异步关注的是消息通信机制 (synchronous communication/ asynchronous communication)。所谓同步,就是在发出一个*调用*时,在没有得到结果之前,该*调用*就不返回。但是一旦调用返回,就得到返回值了。换句话说,就是由*调用者*主动等待这个*调用*的结果。而异步则是相反,*调用*在发出之后,这个调用就直接返回了,所以没有返回结果。换句话说,当一个异步过程调用发出后,调用者不会立刻得到结果。而是在*调用*发出后,*被调用者*通过状态、通知来通知调用者,或通过回调函数处理这个调用。 典型的异步编程模型比如Node.js 举个通俗的例子:你打电话问书店老板有没有《分布式系统》这本书,如果是同步通信机制,书店老板会说,你稍等,"我查一下",然后开始查啊查,等查好了(可能是5秒,也可能是一天)告诉你结果(返回结果)。而异步通信机制,书店老板直接告诉你我查一下啊,查好了打电话给你,然后直接挂电话了(不返回结果)。然后查好了,他会主动打电话给你。在这里老板通过"回电"这种方式来回调。 阻塞与非阻塞 阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态.阻塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。 还是上面的例子,你打电话问书店老板有没有《分布式系统》这本书,你如果是阻塞式调用,你会一直把自己"挂起",直到得到这本书有没有的结果,如果是非阻塞式调用,你不管老板有没有告诉你,你自己先一边去玩了, 当然你也要偶尔过几分钟check一下老板有没有返回结果。在这里阻塞与非阻塞与是否同步异步无关。跟老板通过什么方式回答你结果无关。 I/O模型 由于进程是不可直接访问外部设备的,所以只能调用内核去调用外部的设备(上下文切换),然后外部设备比如磁盘,读出存储在设备自身的数据传送给内核缓冲区,内核缓冲区在copy数据到用户进程的缓冲区。在外部设备响应的给到用户进程过程中,包含了两个阶段;由于数据响应方式的不同,所以就有了不同的I/O模型。 一般有五种I/O模型: 阻塞式I/O模型: 默认情况下,所有套接字都是阻塞的。进程挂起,内核等待外部IO响应,IO完成传送数据到kernel buffer,数据再从buffer复制到用户的进程空间
非阻塞式I/O: 在内核请求IO设备响应指令发出后,数据就开始准备,在此期间用户进程没有阻塞,也就是没有挂起,它一值在询问或者check数据有没有传送到kernel buffer中,忙等…。但是第二个阶段(数据从kernel buffer复制到用户进程空间)依然是阻塞的。但这种IO模型会大量的占用CPU的时间,效率很低效,很少使用。
I/O多路复用(select,poll,epoll...):
在内核请求IO设备响应指令发出后,数据就开始准备,在此期间用户进程是阻塞的。数据从kernel buffer复制到用户进程的过程也是阻塞的。但是和阻塞I/O所不同的是,它可以同时阻塞多个I/O操作,而且可以同时对多个读操作,多个写操作的I/O函数进行检测,直到有数据可读或可写时,才真正调用I/O操作函数,也就是说一个线程可以响应多个请求
Apache和nginx比较:
由于web服务器是一对多的关系,通常完成并行处理的方式有多进程、多线程、异步三种方式。
多进程:多进程就是每个进程对应一个连接来处理请求,进程独立响应自己的请求,一个进程挂了,并不会影响到其他的请求;而且设计简单,不会产生内存泄漏等问题,因此进程比较稳定。但是进程在创建的时候一般是fork机制,会存在内存复制的问题,另外在高并发的情况下,上下文切换将很频繁,这样将消耗很多的性能和时间。早期的apache使用的prework模型就多进程方式,但是apache会预先创建几个进程,等待用户的响应,请求完毕,进程也不会结束。因此性能上有优化很多。
多线程:每个线程响应一个请求,由于线程之间共享进程的数据,所以线程的开销较小,性能就会提高。由于线程管理需要程序自己申请和释放内存,所以当存在内存等问题时,可能会运行很长时间才会暴露问题,所以在一定程度上还不是很稳定。apache的worker模式就是这种方式
异步的方式:nginx的epoll,apache的event也支持,不多说了
Nginx的IO模型是基于事件驱动的,使得应用程序在多个IO句柄间快速切换,实现所谓的异步IO。事件驱动服务器,最适合做的就是IO密集型工作,如反向代理,它在客户端与WEB服务器之间起一个数据中转作用,纯粹是IO操作,自身并不涉及到复杂计算。反向代理用事件驱动来做,显然更好,一个工作进程就可以run了,没有进程、线程管理的开销,CPU、内存消耗都小。
Apache这类应用服务器,一般要跑具体的业务应用,如科学计算、图形图像等。它们很可能是CPU密集型的服务,事件驱动并不合适。例如一个计算耗时2秒,那么这2秒就是完全阻塞的,什么event都没用。想想MySQL如果改成事件驱动会怎么样,一个大型的join或sort就会阻塞住所有客户端。这个时候多进程或线程就体现出优势,每个进程各干各的事,互不阻塞和干扰。当然,现代CPU越来越快,单个计算阻塞的时间可能很小,但只要有阻塞,事件编程就毫无优势。所以进程、线程这类技术,并不会消失,而是与事件机制相辅相成,长期存在。
总的说来,事件驱动适合于IO密集型服务,多进程或线程适合于CPU密集型服务
其实也就是说nginx比较适合做前端代理,或者处理静态文件(尤其高并发情况下),而apache适合做后端的应用服务器,功能强大[php, rewrite…],稳定性高。
Web服务并发I/O模型的更多相关文章
- 关于如何提高Web服务端并发效率的异步编程技术
最近我研究技术的一个重点是java的多线程开发,在我早期学习java的时候,很多书上把java的多线程开发标榜为简单易用,这个简单易用是以C语言作为参照的,不过我也没有使用过C语言开发过多线程,我只知 ...
- 如何提高Web服务端并发效率的异步编程技术
作为一名web工程师都希望自己做的web应用能被越来越多的人使用,如果我们所做的web应用随着用户的增多而宕机了,那么越来越多的人就会变得越来越少了,为了让我们的web应用能有更多人使用,我们就得提升 ...
- 如何测试Web服务.1
一.什么是web服务 web服务在简单术语中可被定义为通过安装了特定设备或服务器到另一装置或客户端应用程序通过WWW彼此通信后的应用程序(万维网)提供的服务. Web服务通常在计算机网络的应用层上使 ...
- Python Web学习笔记之并发编程IO模型
了解新知识之前需要知道的一些知识 同步(synchronous):一个进程在执行某个任务时,另外一个进程必须等待其执行完毕,才能继续执行 #所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调 ...
- 各I/O模型 对应Web服务应用模型(select,poll,epoll,kevent,"/dev/poll")
一.利用select多路复用I/O的Web服务应用模型 /* 可读.可写.异常三种文件描述符集的申明和初始化.*/ fd_set readfds, writefds, exceptionfds; F ...
- 高并发Web服务的演变:节约系统内存和CPU
一.越来越多的并发连接数 现在的Web系统面对的并发连接数在近几年呈现指数增长,高并发成为了一种常态,给Web系统带来不小的挑战.以最简单粗暴的方式解决,就是增加Web系统的机器和升级硬件配置.虽然现 ...
- 转---高并发Web服务的演变——节约系统内存和CPU
[问底]徐汉彬:高并发Web服务的演变——节约系统内存和CPU 发表于22小时前| 4223次阅读| 来源CSDN| 22 条评论| 作者徐汉彬 问底Web服务内存CPU并发徐汉彬 摘要:现在的Web ...
- Azure机器学习入门(四)模型发布为Web服务
接Azure机器学习(三)创建Azure机器学习实验,下一步便是真正地将Azure机器学习的预测模型发布为Web服务.要启用Web服务发布任务,首先点击底端导航栏的运行即"Run" ...
- EJB_开发EJB容器模型的WEB服务
开发EJB容器模型的WEB服务 WEB服务 Web服务也是一种分布式技术,它与EJB最大的不同是,Web服务属于行业规范,可以跨平台及语言.而EJB属于Java平台的规范,尽管理论上可以跨平台,但实现 ...
随机推荐
- Hadoop服务库与事件库的使用及其工作流程
Hadoop服务库与事件库的使用及其工作流程 Hadoop服务库: YARN采用了基于服务的对象管理模型,主要特点有: 被服务化的对象分4个状态:NOTINITED,INITED,STARTED, ...
- MyBatis从入门到放弃二:传参
前言 我们在mapper.xml写sql,如果都是一个参数,则直接配置parameterType,那实际业务开发过程中多个参数如何处理呢? 从MyBatis API中发现selectOne和selec ...
- asp.net 获取网站根地址
public static string GetSiteRoot() { string port = System.Web.HttpContext.Current.Request.ServerVari ...
- Extjs 项目中常用的小技巧,也许你用得着(1)
我在项目中遇到的一些知识点: 1.在GridPanel中显示图片,效果 对应的代码实现 { text: '是否启用', width: 80, // xtype: 'checkcolumn', data ...
- Maven配置国内镜像仓库
eclipse 位置
- hadoop fs,hadoop dfs,hdfs dfs
hadoop fs: FS relates to a generic file system which can point to any file systems like local, HDFS ...
- 第一篇 Spring boot 配置文件笔记
spring boot 不需要配置太多文件程序便可正常运行,特殊情况需要我们自己配置文件. 项目以IDEA写实例,系统会默认在src/main/java/resources目录下创建applicati ...
- 快速排序 java详解
1.快速排序简介: 快速排序由C. A. R. Hoare在1962年提出.它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此 ...
- Matlab illustrate stiffness
% matlab script to illustrate stiffness % using simple flame propagation model close all clear all % ...
- html页面背景设定相关
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...