了解磁盘IO的那些事
了解磁盘IO的那些事
我们作为一名开发,经常耳熟能详的一句话,就是提高程序的性能。对于一个应用程序存在问题的直观体现:页面打开很慢,需要等待。造成这样的问题的主要原因有以下几种:1.网络问题。带宽和网络质量。2.硬件问题。cpu、硬盘、磁盘。3.程序问题。业务逻辑、程序流程、慢sql。当你的网络稳定、硬件资源充足、程序不存在问题的情况,你还想继续优化应用程序,给用户良好的体验,这时候你需要考虑的就是IO的问题。也就是我们常说的磁盘IO与网络IO。
磁盘IO读的那些事
什么是磁盘IO?举个简单的例子,当你程序的运行,内存中不存在,这个时候应用程序就会触发系统调用,去磁盘中读取相应的数据加载到内存中。这个过程就是一个经典的磁盘IO。
1、IO中断原理
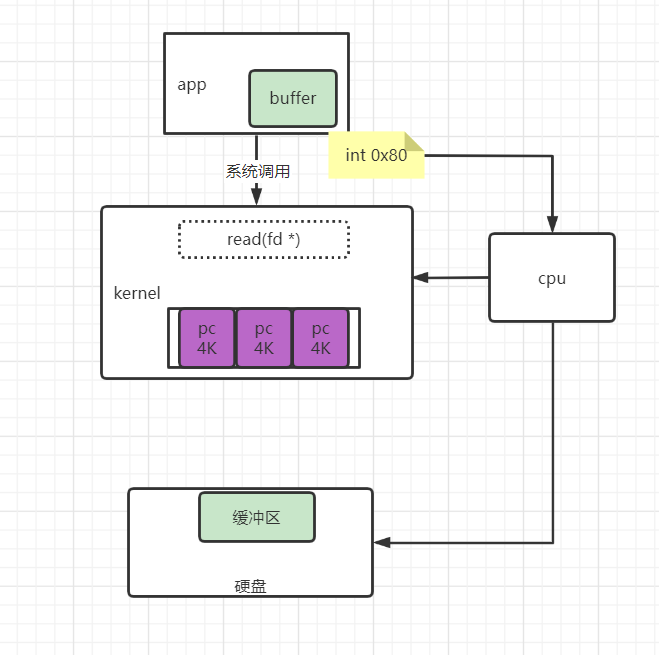
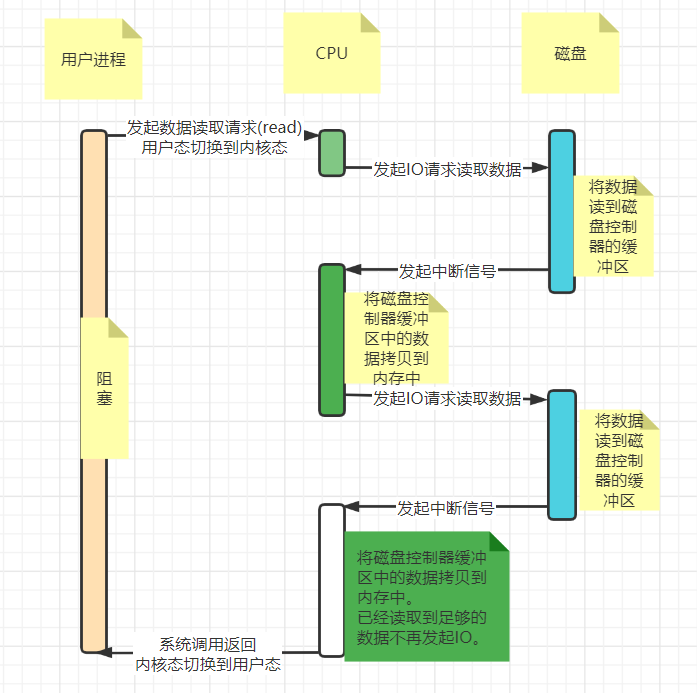
整个流程如下:
用户进程调用read等系统调用向操作系统发出IO请求,请求读取数据到自己的内存缓冲区中。自己进入阻塞状态。
操作系统收到请求后,进一步将IO请求发送磁盘。
磁盘驱动器收到内核的IO请求,把数据从磁盘读取到驱动器的缓冲中。此时不占用CPU。当驱动器的缓冲区被读满后,向内核发起中断信号告知自己缓冲区已满。
内核收到中断,使用CPU时间将磁盘驱动器的缓存中的数据拷贝到内核缓冲区中。
如果内核缓冲区的数据少于用户申请的读的数据,重复步骤3跟步骤4,直到内核缓冲区的数据足够多为止。
CPU将数据从内核缓冲区拷贝到用户缓冲区,同时从系统调用中返回。完成任务。
由上图,我们可以看出数据的取需要cpu的参与,数据流向磁盘>>cpu缓冲区>>内存。且一旦读取的数据量多时,必然需要CPU的多次参与,在一定程度上会占用cpu的时间片。当数据从磁盘到内存这个过程,无需cpu的参与时,那么效率必然更高效。
2.DMA原理
针对于IO中断方式的磁盘IO,为了减少cpu的参与,所以协处理器DMA参与的磁盘IO应运而生。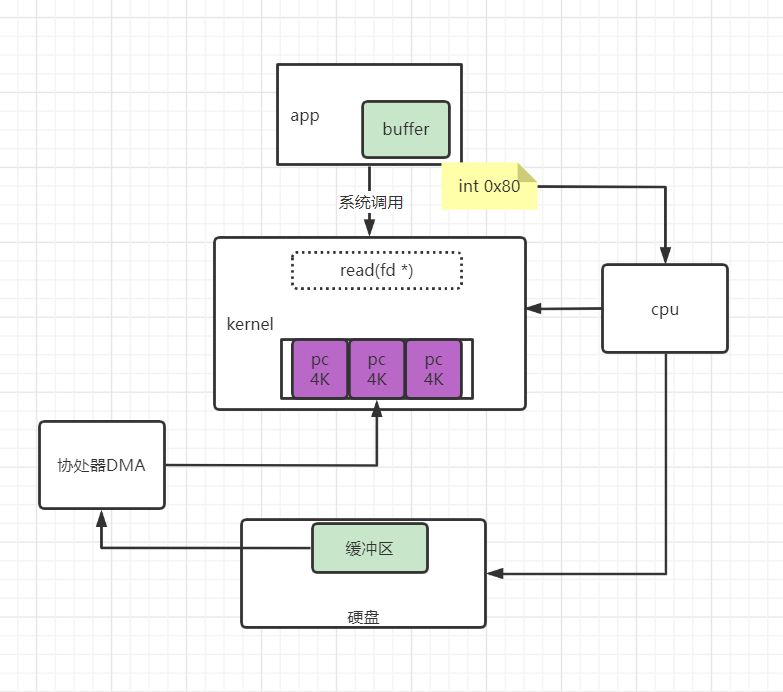
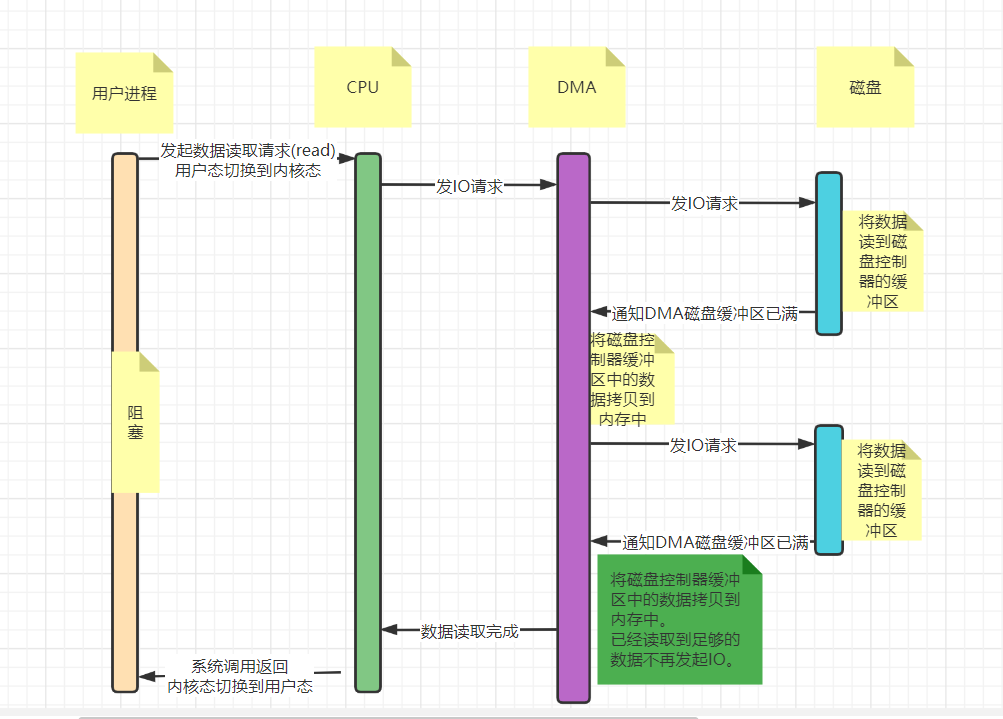
具体流程如下:
用户进程调用read等系统调用向操作系统发出IO请求,请求读取数据到自己的内存缓冲区中。自己进入阻塞状态。
操作系统收到请求后,进一步将IO请求发送DMA。然后让CPU干别的活去。
DMA进一步将IO请求发送给磁盘。
磁盘驱动器收到DMA的IO请求,把数据从磁盘读取到驱动器的缓冲中。当驱动器的缓冲区被读满后,向DMA发起中断信号告知自己缓冲区已满。
DMA收到磁盘驱动器的信号,将磁盘驱动器的缓存中的数据拷贝到内核缓冲区中。此时不占用CPU(IO中断这里是占用CPU的)。
这个时候只要内核缓冲区的数据少于用户申请的读的数据,内核就会一直重复步骤3跟步骤4,直到内核缓冲区的数据足够多为止。
当DMA读取了足够多的数据,就会发送中断信号给CPU。
CPU收到DMA的信号,知道数据已经准备好,于是将数据从内核拷贝到用户空间,系统调用返回。
有了DMA的参与,数据可以直接从磁盘拷贝到内存,无需cpu的参与。
在磁盘IO发生的过程中有几个地方需要我么去了解一下。
1.什么是DMA?
DMA(Direct Memory Access),直接存储器 是所有现代电脑的重要特色,它允许不同速度的硬件装置来沟通,而不需要依赖于CPU的大量中断负载。否则,CPU 需要从来源把每一片段的资料复制到暂存器,然后把它们再次写回到新的地方。在这个时间中,CPU 对于其他的工作来说就无法使用。DMA可以减少cpu的调用。这个机制属于内核优化机制。
2.什么是pagecache
page cache,又称pcache,其中文名称为页高速缓冲存储器,简称页高缓。page cache的大小为一页,通常为4K。在linux读写文件时,它用于缓存文件的逻辑内容,从而加快对磁盘上映像和数据的访问。从磁盘中读取数据都是以页的形式读取。当程序缓存中不存在需要的数据时,也就是所谓的缺页,也就是触发缺页中断的系统调用,从磁盘中读取数据。一旦程序修改了内存中的数据,那么这个数据页就会被标记为脏,也就是脏页。内核将会在合适的时间把脏页的数据写到磁盘中。多个应用程序对于内存中page cache的数据是可以共享,无需重复读取。
3.mmap
尽管有了协处理器DMA的参与,但是数据的读取依然存在多次的数据搬运的过程,减少数据多次的搬运,是否能提高程序运行的性能?答案是肯定。如果能减少数据的多次搬运产生的消耗,那么程序运行的时间会更短,所需等待的时间也会越短。mmap应运而生。
mmap是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动回写脏页面到对应的文件磁盘上,即完成了对文件的操作而不必再调用read,write等系统调用函数。相反,内核空间对这段区域的修改也直接反映用户空间,从而可以实现不同进程间的文件共享。
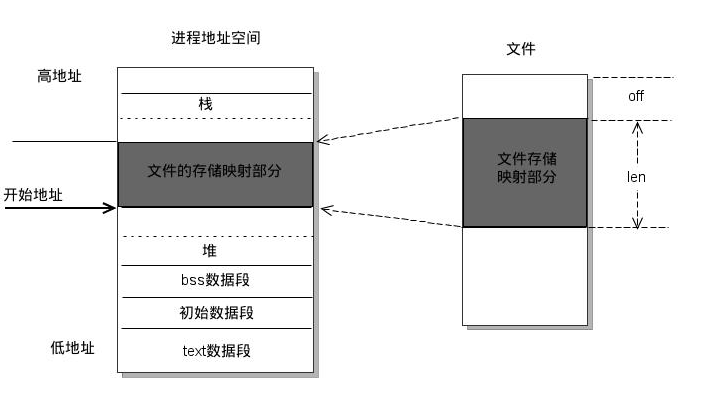
从IO中断到MMAP的过程,其本质就是减少系统调用以及数据的搬运,从而提高系统的性能,减少资源上的浪费。
磁盘IO写的那些事
对于数据写磁盘的事情也是受到操作系统内核的约束,我们在程序开发的时候,经常性做的一件事件就是将写的操作放到一块,一起写入磁盘,而不是需要写的时候就直接写入,尤其在操作数据库的时候。其本质也是在减少操作系统内核的调用,提升程序的性能。
接下来两段小程序可以证明,数据集中写入可以提高性能。
1.没有buffer的IO
public class OSFileIO {
static byte[] data = "123456789\n".getBytes();
static String path = "/root/testfileio/out.txt";
public static void testBasicFileIO() throws Exception {
File file = new File(path);
FileOutputStream out = new FileOutputStream(file);
while(true){
out.write(data);
}
}
}
2.使用buffer的IO
public class OSFileIO2 {
static byte[] data = "123456789\n".getBytes();
static String path = "/root/testfileio/out1.txt";
public static void testBufferedFileIO() throws Exception {
File file = new File(path);
BufferedOutputStream out = new BufferedOutputStream(new FileOutputStream(file));
while(true){
out.write(data);
}
}
}
JVM中默认的buffer大小为8K。
这两段程序在往文件中写入数据,在规定时间内,可以比较文件大小。使用buffer的IO的写操作明显比无buffer的IO快。
所以写磁盘的速度也是:普通IO<< buffer IO << mmap。
文件读写时发生的事
public void whatByteBuffer(){
// ByteBuffer buffer = ByteBuffer.allocate(1024);
ByteBuffer buffer = ByteBuffer.allocateDirect(1024);
System.out.println("postition: " + buffer.position());
System.out.println("limit: " + buffer.limit());
System.out.println("capacity: " + buffer.capacity());
System.out.println("mark: " + buffer);
buffer.put("123".getBytes());
System.out.println("-------------put:123......");
System.out.println("mark: " + buffer);
buffer.flip(); //读写交替
System.out.println("-------------flip......");
System.out.println("mark: " + buffer);
buffer.get();
System.out.println("-------------get......");
System.out.println("mark: " + buffer);
buffer.compact();
System.out.println("-------------compact......");
System.out.println("mark: " + buffer);
buffer.clear();
System.out.println("-------------clear......");
System.out.println("mark: " + buffer);
}
关于文件的读写有几个特别的方法:
put:往buffer中放入数据,pos向后移动
flip:反转,pos回到可以读取数据的位置,limit的位置回到能读取位置的最后。
get():一次读取一个位置。pos向后移动。
compact:将读取过的内容挤压掉,pos指向可以put数据的位置。
clear():清除,初始化,变成最初状态
pos:读取位置或者放入数据的位置
limit:buffer的容量,或者可读取的字节数
capicity:总容量的大小。
以上几个方法就是buffer数据写入和读取的过程。
几个容易迷失的注意点
1.当程序写操作运行结束,数据是否已经写入磁盘?
答案是否定的,写操作也是受到操作系统内核的限制,在操作系统内核没有触发刷盘操作时,数据是没有真正持久化到磁盘中,依然有丢失数据的问题存在。
2.为什么有buffer的IO比普通IO的数据快?
主要是因为普通的IO频繁触发了系统调用,而在JVM中只有buffer满了,才会触发系统调用,将数据写入磁盘中。
3.当频繁的往一个文件中写入数据,是否会存在内存中?
当内存空间足够时,数据会存在内存中。当内存空间不够时,会优先淘汰掉最早写入的数据。
4.mmap是否可以不需要操作系统内核直接写入数据?
不可以。mmap也需要收到内核系统的约束。
linux内核中几个重要的参数
vm.dirty_background_ratio = 0 内核往磁盘同步脏页的阈值(百分比)
vm.dirty_background_bytes = 1048576 内核往磁盘同步脏页的字节阈值
vm.dirty_ratio = 0 当程序不停向page cache写入数据达到这个阈值,就会阻塞,开始写入磁盘。
vm.dirty_bytes = 1048576 当程序不停向page cache写入数据达到这个字节限制阈值,就会阻塞,写入磁盘
vm.dirty_writeback_centisecs = 5000 脏页写入磁盘的时间(单位:0.01秒)
vm.dirty_expire_centisecs = 30000 脏页的生命周期可以存多久(单位:0.01秒)
总结
对于磁盘IO的读与写,其整个过程都是在减少数据的搬运,操作系统内核的参与,从而提高系统的性能。但是无论采用何种手段,操作系统是没办法保证数据不丢失。其实这是操作系统在数据的可靠性与系统的性能上做了一个取舍。选择了系统性能,承担了在一定时间内丢失数据的风险。作为程序开发,我们的任务就是在操作系统允许的范围内,了解其原理,减少磁盘IO中数据的搬运以及系统的调用的次数,提高系统的性能。
了解磁盘IO的那些事的更多相关文章
- 磁盘io的那些事
1.使用hdparm命令 hdparm -Tt /dev/sda /dev/sda: Timing cached reads: 6676 MB in 2.00 seconds = 3340.18 M ...
- 【好书摘要】性能优化中CPU、内存、磁盘IO、网络性能的依赖
系统优化是一项复杂.繁琐.长期的工作,优化前需要监测.采集.测试.评估,优化后也需要测试.采集.评估.监测,而且是一个长期和持续的过程,不 是说现在优化了,测试了,以后就可以一劳永逸了,也不是说书本上 ...
- Linux按照CPU、内存、磁盘IO、网络性能监测
系统优化是一项复杂.繁琐.长期的工作,优化前需要监测.采集.测试.评估,优化后也需要测试.采集.评估.监测,而且是一个长期和持续的过程,不 是说现在优化了,测试了,以后就可以一劳永逸了,也不是说书 ...
- inux按照CPU、内存、磁盘IO、网络性能监测
http://my.oschina.net/chape/blog/159640 系统优化是一项复杂.繁琐.长期的工作,优化前需要监测.采集.测试.评估,优化后也需要测试.采集.评估.监测,而且是一个长 ...
- linux性能优化cpu 磁盘IO MEM
系统优化是一项复杂.繁琐.长期的工作,优化前需要监测.采集.测试.评估,优化后也需要测试.采集.评估.监测,而且是一个长期和持续的过程,不 是说现在优化了,测试了,以后就可以一劳永逸了,也不是说书本上 ...
- 网络IO和磁盘IO详解
1. 缓存IO 缓存I/O又被称作标准I/O,大多数文件系统的默认I/O操作都是缓存I/O.在Linux的缓存I/O机制中,数据先从磁盘复制到内核空间的缓冲区,然后从内核空间缓冲区复制到应用程序的地址 ...
- 性能优化中CPU、内存、磁盘IO、网络性能的依赖(转)
关于系统性能优化,推荐一篇不错的博客! 系统优化是一项复杂.繁琐.长期的工作,优化前需要监测.采集.测试.评估,优化后也需要测试.采集.评估.监测,而且是一个长期和持续的过程,不 是说现在优化了,测试 ...
- Linux按照CPU、内存、磁盘IO、网络性能监测【转载】
本文转载地址:https://my.oschina.net/chape/blog/159640 系统优化是一项复杂.繁琐.长期的工作,优化前需要监测.采集.测试.评估,优化后也需要测试.采集.评估.监 ...
- 性能优化中CPU、内存、磁盘IO、网络性能的依赖
系统优化是一项复杂.繁琐.长期的工作,优化前需要监测.采集.测试.评估,优化后也需要测试.采集.评估.监测,而且是一个长期和持续的过程,不 是说现在优化了,测试了,以后就可以一劳永逸了,也不是说书本上 ...
随机推荐
- luoguP5319 [BJOI2019]奥术神杖(分数规划,AC自动机DP)
luoguP5319 [BJOI2019]奥术神杖(分数规划,AC自动机DP) Luogu 题解时间 难点在于式子转化,设有c个满足的子串,即求最大的 $ ans = \sqrt[c]{\prod_{ ...
- 建立META-INF/spring.factories文件的意义何在
平常我们如何将Bean注入到容器当中 @Configuration @EnableConfigurationProperties(HelloProperties.class) public class ...
- cookie可设置哪些属性?httponly?
chrome控制台的application下可查看: cookie name 字段为一个cookie的名称. value 字段为一个cookie的值. domain 字段为可以访问此cookie的域名 ...
- String s = "Hello";s = s + " world!";这两行代码执行后,原始的String对象中的内容到底变了没有?
没有.因为String被设计成不可变(immutable)类,所以它的所有对象都是不可变对象.在这段代码中,s原先指向一个String对象,内容是 "Hello",然后我们对s进行 ...
- kafka中的 zookeeper 起到什么作用,可以不用zookeeper么?
zookeeper 是一个分布式的协调组件,早期版本的kafka用zk做meta信息存储,consumer的消费状态,group的管理以及 offset的值.考虑到zk本身的一些因素以及整个架构较大概 ...
- springBoot集成Elasticsearch抛出Factory method 'restHighLevelClient' threw exception; nested exception is java.lang.NoSuchFieldError: IGNORE_DEPRECATIONS
org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'restHighLeve ...
- 信号量,semaphore源代码之我见
信号量,Semaphore,一个限定访问线程数量的工具类,属于并发包java.util.concurrent 里面的类. Semaphore,内部提供了构造方法(包含默认的非公平信号量构造方法,已经可 ...
- 遇到过的问题之“解决 No qualifying bean of type 问题”
1.问题 解决 No qualifying bean of type 问题 2.思路: 1 检查是否添加了对应注解 2 检查配置是否正确,扫描包名, 类名及id是否正确 一 . 传统SSM项目 ssm ...
- python中一切皆对象的理解
一切皆对象? 学过Java都知道,Java中有8个基本类型,其余的都是继承自Object类的引用类型.方法内的基本类型变量会在栈上分配,而引用类型会通过逃逸分析来决定在栈上分配或堆上分配.Java中关 ...
- 从零到一:用Phaser.js写意地开发小游戏(Chapter 3 - 加载游戏资源)
回顾 上一节我们搭建了游戏的骨架,添加了四个游戏场景,分别是加载.开始.游戏.结束.那么这一节我们来介绍加载这个场景,顺带丰富一下各个场景的基本内容. Phaser.Loader Phaser框架自带 ...