Hadoop详解(09) - Hadoop新特性
Hadoop详解(09) - Hadoop新特性
Hadoop2.x新特性
远程主机之间的文件复制
- scp实现两个远程主机之间的文件复制
推 push:scp -r hello.txt root@hadoop103:/user/atguigu/hello.txt
拉 pull:scp -r root@hadoop103:/user/atguigu/hello.txt hello.txt
是通过本地主机:
通过本地主机中转实现两个远程主机的文件复制;如果在两个远程主机之间ssh没有配置的情况下可以使用该方式。
scp -r root@hadoop103:/user/atguigu/hello.txt root@hadoop104:/user/atguigu //是通过本地主机中转实现两个远程主机的文件复制;如果在两个远程主机之间ssh没有配置的情况下可以使用该方式。
- 采用distcp命令实现两个Hadoop集群之间的递归数据复制
[hadoop@hadoop102 hadoop-3.1.3]$ bin/hadoop distcp hdfs://hadoop102:9820/user/hadoop/hello.txt hdfs://hadoop105:9820/user/hadoop/hello.txt
小文件存档
- HDFS存储小文件弊端
每个文件均按块存储,每个块的元数据存储在NameNode的内存中,因此HDFS存储小文件会非常低效。因为大量的小文件会耗尽NameNode中的大部分内存。但注意,存储小文件所需要的磁盘容量和数据块的大小无关。例如,一个1MB的文件设置为128MB的块存储,实际使用的是1MB的磁盘空间,而不是128MB。
- 解决存储小文件办法之一
HDFS存档文件或HAR文件,是一个更高效的文件存档工具,它将文件存入HDFS块,在减少NameNode内存使用的同时,允许对文件进行透明的访问。具体说来,HDFS存档文件对内还是一个一个独立文件,对NameNode而言却是一个整体,减少了NameNode的内存。
- 案例实操
需要启动YARN进程
start-yarn.sh
归档文件
把/user/hadoop/input目录里面的所有文件归档成一个叫input.har的归档文件,并把归档后文件存储到/user/hadoop/output路径下。
hadoop archive -archiveName input.har -p /user/hadoop/input /user/hadoop/output
查看归档
hadoop fs -ls /user/hadoop/output/input.har
hadoop fs -ls har:///user/hadoop/output/input.har
解归档文件
hadoop fs -cp har:///user/hadoop/output/input.har/* /user/hadoop
回收站
开启回收站功能,可以将删除的文件在不超时的情况下,恢复原数据,起到防止误删除、备份等作用。
1)回收站参数设置及工作机制
- 开启回收站功能参数说明:
1、默认值fs.trash.interval=0,0表示禁用回收站;其他值表示设置文件的存活时间。
2、默认值fs.trash.checkpoint.interval=0,检查回收站的间隔时间。如果该值为0,则该值设置和fs.trash.interval的参数值相等。
3、要求fs.trash.checkpoint.interval<=fs.trash.interval。
- 回收站的工作机制
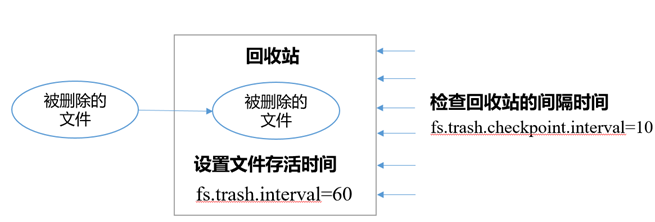
- 启用回收站
修改core-site.xml,配置垃圾回收时间为1分钟。
<property>
<name>fs.trash.interval</name>
<value>1</value>
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>1</value>
</property>
- 查看回收站
回收站目录在hdfs集群中的路径:/user/hadoop/.Trash/….
- 通过程序删除的文件不会经过回收站,需要调用moveToTrash()才进入回收站
Trash trash = New Trash(conf);
trash.moveToTrash(path);
- 通过网页上直接删除的文件也不会走回收站。
- 只有在命令行利用hadoop fs -rm命令删除的文件才会走回收站。
hadoop fs -rm -r /user/hadoop/input
2020-07-14 16:13:42,643 INFO fs.TrashPolicyDefault: Moved: 'hdfs://hadoop102:9820/user/hadoop/input' to trash at: hdfs://hadoop102:9820/user/hadoop/.Trash/Current/user/hadoop/input
- 恢复回收站数据
hadoop fs –mv /user/hadoop/.Trash/Current/user/hadoop/input /user/hadoop/input
Hadoop3.x新特性
多NN的HA架构
HDFS NameNode高可用性的初始实现为单个活动NameNode和单个备用NameNode,将edits复制到三个JournalNode。该体系结构能够容忍系统中一个NN或一个JN的故障。
但是,某些部署需要更高程度的容错能力。Hadoop3.x允许用户运行多个备用NameNode。例如,通过配置三个NameNode和五个JournalNode,群集能够容忍两个节点而不是一个节点的故障。
纠删码
HDFS中的默认3副本方案在存储空间和其他资源(例如,网络带宽)中具有200%的开销。但是,对于I/O活动相对较低暖和冷数据集,在正常操作期间很少访问其他块副本,但仍会消耗与第一个副本相同的资源量。纠删码(Erasure Coding)能够在不到50% 的数据冗余情况下提供和3副本相同的容错能力,因此,使用纠删码作为副本机制的改进是自然而然的。
查看集群支持的纠删码策略:hdfs ec -listPolicies
Hadoop详解(09) - Hadoop新特性的更多相关文章
- 详解Hadoop3.x新特性功能-HDFS纠删码
文章首发于微信公众号:五分钟学大数据 EC介绍 Erasure Coding 简称EC,中文名:纠删码 EC(纠删码)是一种编码技术,在HDFS之前,这种编码技术在廉价磁盘冗余阵列(RAID)中应用 ...
- linux useradd(adduser)命令参数及用法详解(linux创建新用户命令)
linux useradd(adduser)命令参数及用法详解(linux创建新用户命令) useradd可用来建立用户帐号.帐号建好之后,再用passwd设定帐号的密码.而可用userdel删除帐号 ...
- 小甲鱼PE详解之输入表(导出表)详解(PE详解09)
小甲鱼PE详解之输出表(导出表)详解(PE详解09) 当PE 文件被执行的时候,Windows 加载器将文件装入内存并将导入表(Export Table) 登记的动态链接库(一般是DLL 格式)文件一 ...
- Java精通并发-自旋对于synchronized关键字的底层意义与价值分析以及互斥锁属性详解与Monitor对象特性解说【纯理论】
自旋对于synchronized关键字的底层意义与价值分析: 对于synchronized关键字的底层意义和价值分析,下面用纯理论的方式来对它进行阐述,自旋这个概念就会应运而生,还是很重要的,下面阐述 ...
- 【图文详解】Hadoop集群搭建(CentOs6.3)
本文主要详细地描述了hadoop集群的搭建以及一些配置文件的说明,用于自己复习以及供新人学习,若有错误之处还请指出. 前期准备 先给出我的集群架构: 到hadoop官网下载好hadoop安装包http ...
- [Big Data]Hadoop详解一
从数据爆炸开始... 一. 第三次工业革命 第一次:18世纪60年代,手工工厂向机器大生产过渡,以蒸汽机的发明和使用为标志. 第二次:19世纪70年代,各种新技术新发明不断被应 ...
- Hadoop详解一:Hadoop简介
从数据爆炸开始... 一. 第三次工业革命 第一次:18世纪60年代,手工工厂向机器大生产过渡,以蒸汽机的发明和使用为标志. 第二次:19世纪70年代,各种新技术新发明不断被应 ...
- Js apply方法与call方法详解 附ES6新写法
我在一开始看到javascript的函数apply和call时,非常的模糊,看也看不懂,最近在网上看到一些文章对apply方法和call的一些示例,总算是看的有点眉目了,在这里我做如下笔记,希望和大家 ...
- FFmpeg开发笔记(五):ffmpeg解码的基本流程详解(ffmpeg3新解码api)
若该文为原创文章,未经允许不得转载原博主博客地址:https://blog.csdn.net/qq21497936原博主博客导航:https://blog.csdn.net/qq21497936/ar ...
- APNS推送服务证书制作 图文详解教程(新)
iOS消息推送的工作机制可以简单的用下图来概括: Provider是指某个iPhone软件的Push服务器,APNS是Apple Push Notification Service的缩写,是苹果的服务 ...
随机推荐
- C语言编译环境中的 调试功能及常见错误提示
文章目录 1 .调试功能 2 . 编译中的常见错误例析 3 .常见错误信息语句索引 1 .调试功能 1.常用健 <F10> : 激活系统菜单 <F6> : 将光标在编辑窗口和. ...
- MYSQL一键导库脚本
上周完成了一个性能测试环境搭建,有富余时间的同时研究了一个一键导库的脚本,一周的开始先马住!!! 一.思路 准备:54.158服务器上分别已经装好了MYSQL数据库 目的:把部分库从54导出并导入到1 ...
- MySQL 是怎么加行级锁的?为什么一会是 next-key 锁,一会是间隙锁,一会又是记录锁?
大家好,我是小林. 是不是很多人都对 MySQL 加行级锁的规则搞的迷迷糊糊,一会是 next-key 锁,一会是间隙锁,一会又是记录锁. 坦白说,确实还挺复杂的,但是好在我找点了点规律,也知道如何如 ...
- [leetcode] 547. Number of Provinces
题目 There are n cities. Some of them are connected, while some are not. If city a is connected direct ...
- CLR、CLS、CTS概述
在学习.NET的过程中,都会不可避免地接触到这三个概念,那么这三个东西是什么以及它们之间的关系是怎样的呢?任何编程语言,如果想要在.NET CLR上执行,就必需提供一个编译器,将此语言的程序编译成.N ...
- CSP-J2022 题解报告
\(CSP-J2022\) 题解报告 \(T1\) 乘方: 发现 \(2^{32}>10^9\),所以这个题只需要特判 \(a=1\) 的情况为 \(1\),其他直接枚举再判断即可. Code: ...
- scp工具上传下载
1.从本地复制到远程 scp local_file remote_username@remote_ip:remote_folder 或者 scp local_file remote_username@ ...
- python面试题常用语句
一.比较与交换1.比较并输出大的 print(a if a>b else b) 2.交换两个元素 a,b = b,alist1[i],list[j]=list1[j],list[i] 二.排序 ...
- jquery组件解决option选项框的样式自定义方案
记录一下今天工作中遇到的一个需求和自行找到的解决办法 需求: 在原始的select选项框中的增加一个标识.(我想增加一个具有样式的span元素,试了半天在option里无法添加span,更别说具有样式 ...
- js 金钱3位格式化
function formatCash(str) { return str.split('').reverse().reduce((prev, next, index) => { return ...