Hadoop详解(09) - Hadoop新特性
Hadoop详解(09) - Hadoop新特性
Hadoop2.x新特性
远程主机之间的文件复制
- scp实现两个远程主机之间的文件复制
推 push:scp -r hello.txt root@hadoop103:/user/atguigu/hello.txt
拉 pull:scp -r root@hadoop103:/user/atguigu/hello.txt hello.txt
是通过本地主机:
通过本地主机中转实现两个远程主机的文件复制;如果在两个远程主机之间ssh没有配置的情况下可以使用该方式。
scp -r root@hadoop103:/user/atguigu/hello.txt root@hadoop104:/user/atguigu //是通过本地主机中转实现两个远程主机的文件复制;如果在两个远程主机之间ssh没有配置的情况下可以使用该方式。
- 采用distcp命令实现两个Hadoop集群之间的递归数据复制
[hadoop@hadoop102 hadoop-3.1.3]$ bin/hadoop distcp hdfs://hadoop102:9820/user/hadoop/hello.txt hdfs://hadoop105:9820/user/hadoop/hello.txt
小文件存档
- HDFS存储小文件弊端
每个文件均按块存储,每个块的元数据存储在NameNode的内存中,因此HDFS存储小文件会非常低效。因为大量的小文件会耗尽NameNode中的大部分内存。但注意,存储小文件所需要的磁盘容量和数据块的大小无关。例如,一个1MB的文件设置为128MB的块存储,实际使用的是1MB的磁盘空间,而不是128MB。
- 解决存储小文件办法之一
HDFS存档文件或HAR文件,是一个更高效的文件存档工具,它将文件存入HDFS块,在减少NameNode内存使用的同时,允许对文件进行透明的访问。具体说来,HDFS存档文件对内还是一个一个独立文件,对NameNode而言却是一个整体,减少了NameNode的内存。
- 案例实操
需要启动YARN进程
start-yarn.sh
归档文件
把/user/hadoop/input目录里面的所有文件归档成一个叫input.har的归档文件,并把归档后文件存储到/user/hadoop/output路径下。
hadoop archive -archiveName input.har -p /user/hadoop/input /user/hadoop/output
查看归档
hadoop fs -ls /user/hadoop/output/input.har
hadoop fs -ls har:///user/hadoop/output/input.har
解归档文件
hadoop fs -cp har:///user/hadoop/output/input.har/* /user/hadoop
回收站
开启回收站功能,可以将删除的文件在不超时的情况下,恢复原数据,起到防止误删除、备份等作用。
1)回收站参数设置及工作机制
- 开启回收站功能参数说明:
1、默认值fs.trash.interval=0,0表示禁用回收站;其他值表示设置文件的存活时间。
2、默认值fs.trash.checkpoint.interval=0,检查回收站的间隔时间。如果该值为0,则该值设置和fs.trash.interval的参数值相等。
3、要求fs.trash.checkpoint.interval<=fs.trash.interval。
- 回收站的工作机制
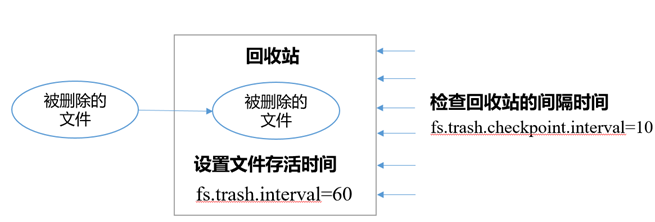
- 启用回收站
修改core-site.xml,配置垃圾回收时间为1分钟。
<property>
<name>fs.trash.interval</name>
<value>1</value>
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>1</value>
</property>
- 查看回收站
回收站目录在hdfs集群中的路径:/user/hadoop/.Trash/….
- 通过程序删除的文件不会经过回收站,需要调用moveToTrash()才进入回收站
Trash trash = New Trash(conf);
trash.moveToTrash(path);
- 通过网页上直接删除的文件也不会走回收站。
- 只有在命令行利用hadoop fs -rm命令删除的文件才会走回收站。
hadoop fs -rm -r /user/hadoop/input
2020-07-14 16:13:42,643 INFO fs.TrashPolicyDefault: Moved: 'hdfs://hadoop102:9820/user/hadoop/input' to trash at: hdfs://hadoop102:9820/user/hadoop/.Trash/Current/user/hadoop/input
- 恢复回收站数据
hadoop fs –mv /user/hadoop/.Trash/Current/user/hadoop/input /user/hadoop/input
Hadoop3.x新特性
多NN的HA架构
HDFS NameNode高可用性的初始实现为单个活动NameNode和单个备用NameNode,将edits复制到三个JournalNode。该体系结构能够容忍系统中一个NN或一个JN的故障。
但是,某些部署需要更高程度的容错能力。Hadoop3.x允许用户运行多个备用NameNode。例如,通过配置三个NameNode和五个JournalNode,群集能够容忍两个节点而不是一个节点的故障。
纠删码
HDFS中的默认3副本方案在存储空间和其他资源(例如,网络带宽)中具有200%的开销。但是,对于I/O活动相对较低暖和冷数据集,在正常操作期间很少访问其他块副本,但仍会消耗与第一个副本相同的资源量。纠删码(Erasure Coding)能够在不到50% 的数据冗余情况下提供和3副本相同的容错能力,因此,使用纠删码作为副本机制的改进是自然而然的。
查看集群支持的纠删码策略:hdfs ec -listPolicies
Hadoop详解(09) - Hadoop新特性的更多相关文章
- 详解Hadoop3.x新特性功能-HDFS纠删码
文章首发于微信公众号:五分钟学大数据 EC介绍 Erasure Coding 简称EC,中文名:纠删码 EC(纠删码)是一种编码技术,在HDFS之前,这种编码技术在廉价磁盘冗余阵列(RAID)中应用 ...
- linux useradd(adduser)命令参数及用法详解(linux创建新用户命令)
linux useradd(adduser)命令参数及用法详解(linux创建新用户命令) useradd可用来建立用户帐号.帐号建好之后,再用passwd设定帐号的密码.而可用userdel删除帐号 ...
- 小甲鱼PE详解之输入表(导出表)详解(PE详解09)
小甲鱼PE详解之输出表(导出表)详解(PE详解09) 当PE 文件被执行的时候,Windows 加载器将文件装入内存并将导入表(Export Table) 登记的动态链接库(一般是DLL 格式)文件一 ...
- Java精通并发-自旋对于synchronized关键字的底层意义与价值分析以及互斥锁属性详解与Monitor对象特性解说【纯理论】
自旋对于synchronized关键字的底层意义与价值分析: 对于synchronized关键字的底层意义和价值分析,下面用纯理论的方式来对它进行阐述,自旋这个概念就会应运而生,还是很重要的,下面阐述 ...
- 【图文详解】Hadoop集群搭建(CentOs6.3)
本文主要详细地描述了hadoop集群的搭建以及一些配置文件的说明,用于自己复习以及供新人学习,若有错误之处还请指出. 前期准备 先给出我的集群架构: 到hadoop官网下载好hadoop安装包http ...
- [Big Data]Hadoop详解一
从数据爆炸开始... 一. 第三次工业革命 第一次:18世纪60年代,手工工厂向机器大生产过渡,以蒸汽机的发明和使用为标志. 第二次:19世纪70年代,各种新技术新发明不断被应 ...
- Hadoop详解一:Hadoop简介
从数据爆炸开始... 一. 第三次工业革命 第一次:18世纪60年代,手工工厂向机器大生产过渡,以蒸汽机的发明和使用为标志. 第二次:19世纪70年代,各种新技术新发明不断被应 ...
- Js apply方法与call方法详解 附ES6新写法
我在一开始看到javascript的函数apply和call时,非常的模糊,看也看不懂,最近在网上看到一些文章对apply方法和call的一些示例,总算是看的有点眉目了,在这里我做如下笔记,希望和大家 ...
- FFmpeg开发笔记(五):ffmpeg解码的基本流程详解(ffmpeg3新解码api)
若该文为原创文章,未经允许不得转载原博主博客地址:https://blog.csdn.net/qq21497936原博主博客导航:https://blog.csdn.net/qq21497936/ar ...
- APNS推送服务证书制作 图文详解教程(新)
iOS消息推送的工作机制可以简单的用下图来概括: Provider是指某个iPhone软件的Push服务器,APNS是Apple Push Notification Service的缩写,是苹果的服务 ...
随机推荐
- 使用开源计算引擎提升Excel格式文件处理效率
对Excel进行解析\生成\查询\计算等处理是Java下较常见的任务,但Excel的文件格式很复杂,自行编码读写太困难,有了POI\EasyExcel\JExcel等类库就方便多了,其中POI最为出色 ...
- RedHat7.6安装mysql8步骤
1.官网下载mysql安装包 直达链接:https://dev.mysql.com/downloads/mysql/ 2.将下载好的安装包上传到redhat系统上(有多种上传方式,本次使用Sec ...
- Hadoop集群简单入门
Hadoop集群搭建 自己配置Hadoop的话太过复杂了,因为自己着急学习,就使用了黑马的快照.如果小伙伴们也想的话可以直接看黑马的课程,快照的话关注黑马程序员公众号,输入Hadoop就能获取资料,到 ...
- 题解 CF803A Maximal Binary Matrix
Luogu codeforces 前言 模拟赛原题.. 好好一道送分被我硬打成爆蛋.. \(\sf{Solution}\) 看了一波数据范围,感觉能 dfs 骗分. 骗成正解了. 大概就是将这个 \( ...
- 三、Python语法介绍
三.Python语言介绍 3.1.了解Python语言 Python 是1989 年荷兰人 Guido van Rossum (简称 Guido)在圣诞节期间为了打发时间,发明的一门面向对象的解释性编 ...
- 【性能测试】Loadrunner12.55(二)-飞机订票系统-脚本录制
1.1 飞机订票系统 Loadrunner 12.55不会自动安装飞机订票系统,要自己手动安装. 我们需要下载Web Tools以及一个小插件strawberry https://marketplac ...
- SpringBoot 过滤器和拦截器
过滤器 实现过滤器需要实现 javax.servlet.Filter 接口.重写三个方法.其中 init() 方法在服务启动时执行,destroy() 在服务停止之前执行. 可用两种方式注册过滤器: ...
- 使用jmx exporter采集kafka指标
预置条件 安装kafka.prometheus 使用JMX exporter暴露指标 下载jmx exporter以及配置文件.Jmx exporter中包含了kafka各个组件的指标,如server ...
- Day11.2:标签的使用
标签的使用 当我们在嵌套语句中,例如当我们在for的嵌套循环语句中,想要终止或重新开始当前循环以外的循环的时候,单独仅靠break和continue和还不够,需要在我们想要作用的循环语句处加上一个标签 ...
- Go语言核心36讲26
你好,我是郝林.今天我分享的主题是测试的基本规则和流程的(下)篇. Go语言是一门很重视程序测试的编程语言,所以在上一篇中,我与你再三强调了程序测试的重要性,同时,也介绍了关于go test命令的基本 ...