SQLite入门与分析(八)---存储模型(1)
写在前面:SQLite作为嵌入式数据库,通常针对的应用的数据量相对于通常DBMS的数据量是较小的。所以它的存储模型设计得非常简单,总的来说,SQLite把一个数据文件分成若干大小相等的页面,然后以B树的形式来组织这些页面。而对于大型的数据库管理系统,比如Oracle,或者DM ,存储模型要复杂得多。就拿Oracle来说吧,它对数据文件不仅从物理进行分块,而且从逻辑上进行分段,盘区和页的一个层次划分,DM也一样。不管怎么说,数据库文件要存储大量的数据,为了更好管理,查询和操作数据文件,DBMS不得不从物理上、逻辑上对数据文件的数据进行复杂的组织。本节主要讨论文件格式,下节讨论页面格式。
1、文件格式
1.1、数据库名称
应用程序通过sqlite3_open API来打开数据库,该函数的一个参数为数据库文件的名称。SQLite内部命名为main数据库(除了临时数据库和内存数据库)。SQLite对每一个数据库都创建一个独立的文件。
在SQLite内部,数据文件名不是数据库名。SQLite对应用程序的每一个连接都维护着一个单独的临时数据库(temp数据库),临时数据库存临时对象,例如:表以及相应的索引。这些临时对象仅仅对同一个连接可见(对同一个线程,进程的其它连接是不可见的),SQLite存储临时数据库到一个单独的临时文件中,当应用程序关闭对main数据库的连接时,就删除临时文件。
1.2、数据库文件结构
除了内存数据库,SQLite把一个数据库(main和temp)都存储到一个单独的文件。
1.2.1、页面(page)
为了更好的管理和读/写数据库,SQLite把一个数据库(包括内存数据库)分成一个个固定大小的页面。页面大小的范围从512-32768(两者都包含),页面默认大小为1024个字节(1KB),实际上,页面的上限由2个字节的有符号整数决定。整个数据库可以看成这些页面的数组,页面数组的下标为页面的编号(page number),page number从1开始,一直到2,147,483,647 (2^31– 1)。实际上,数组上界还受文件系统允许的最大文件大小决定。0号页面视为空页面(NULL page),物理上不存在,1号页面从文件的0偏移处开始,一个页面接着下一个页面。
注:一旦数据库创建,SQLite使用编译时确定的默认的页面大小。当然,在创建第一个表之前,可以通过pragma命令改变页面大小。SQLite把该值作为元数据的一部分存储在文件中。
1.2.2、页面类型
页面(page)分四种类型:叶子页面(leaf),内部页面(internal),溢出页面(overflow)和空闲页面(free)。内部页面包含查询时的导航信息,叶子页面存储数据,例如元组。如果一个元组的数据太大,一个页面容纳不下,则一些数据存储在B树的页面中,余下的存储在溢出页面中。
1.2.3、文件头(file header)
作为文件开始的1号页面比较特殊,它包括100个字节的文件头。当SQLite创建文件时例初始化文件头,文件头的格式如下:
Structure of database file header |
||
|
Offset |
Size |
Description |
|
0 |
16 |
Header string |
|
16 |
2 |
Page size in bytes |
|
18 |
1 |
File format write version |
|
19 |
1 |
File format read version |
|
20 |
1 |
Bytes reserved at the end of each page |
|
21 |
1 |
Max embedded payload fraction |
|
22 |
1 |
Min embedded payload fraction |
|
23 |
1 |
Min leaf payload fraction |
|
24 |
4 |
File change counter |
|
28 |
4 |
Reserved for future use |
|
32 |
4 |
First freelist page |
|
36 |
4 |
Number of freelist pages |
|
40 |
60 |
15 4-byte meta values |
示例数据(100个字节):
|
53 51 4C 69 74 65 20 66 SQLite f 6F 72 6D 61 74 20 33 00 ormat 3. 04 00 01 01 00 40 20 20 .....@ 00 00 00 11 00 00 00 00 ........ 00 00 00 00 00 00 00 00 ........ 00 00 00 01 00 00 00 01 ........ 00 00 00 00 00 00 00 00 ........ 00 00 00 01 00 00 00 00 ........ 00 00 00 00 00 00 00 00 ........ 00 00 00 00 00 00 00 00 ........ 00 00 00 00 00 00 00 00 ........ 00 00 00 00 00 00 00 00 ........ 00 00 00 00 |
Header string(头字符串):
16个字节:"SQLite format 3."
Page size:
页面大小:0x04 00 ,即1024
File format:
文件格式:0x01 ,0x01,在当前的版本都为1。
Reserved space:
保留空间:0x00,1个字节,SQLite在每个页面的末尾都会保留一定的空间,留作它用,默认为0。
Embedded payload:
max embedded payload fraction(偏移21)的值限定了B树内节点(页面)中一个元组(记录,单元)最多能够使用的空间。255意味着100%,默认值为0x40,即64(25%),这保证了一个结点(页面)至少有4个单元。如果一个单元的负载(payload,即数据量)超过最大值,则溢出的数据保存到溢出的页面,一旦SQLite分配了一个溢出页面,它会尽可能多的移动数据到溢出页面,下限为min embedded payload fraction value(偏移为22),默认的值为32,即12.5% 。
min leaf payload fraction的含义与min embedded payload fraction类似,只不过是它是针对B树的叶子结点,默认值为32,即12.5%,叶子结点最大的负载为通常是100%,这不用保存。
File change counter:
文件修改计数,通常被事务使用,它由事务增加其值。该值的主要目的是数据库改变时,pager避免对缓存进行刷盘。
Freelist:
空闲页面链表,在文件头偏移32的4个字节记录着空闲页面链的第一个页面,偏移36处的4个字节为空闲页面的数量。空闲页面链表的组织形式如下: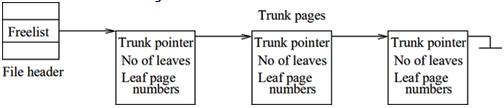
空闲页面分为两种页面:trunk pages(主页面)和leaf pages(叶子页面)。文件头的指针指向空闲链表的第一个trunk page,每个trunk page指向多个叶子页面。
Trunk page的格式如下,从页面的起始处开始:
(1)4个字节,指向下一个trunk page的页面号;
(2)4个字节,该页面的叶子页面指针的数量;
(3)指向叶子页面的页面号,每项4个字节。
当一个页面不再使用时,SQLite把它加入空闲页面链表,并不从本地文件系统中释放掉。当添加新的数据到数据库时,SQLite就从空闲链表上取出空闲页面用来在存储数据。当空闲链表为空时,SQLite就通过本地文件系统增加新的页面,添加到数据库文件的末尾。
注:可以通过vacuum命令删除空闲链表,该命令通过把数据库中数据拷贝到临时文件,然后在事务的保护下,用临时文件中的复本覆盖原数据库文件。
Meta variables
元数据变量:从偏移为40开始,为15个4字节的元数据变量,这些元数据主要与B树和VM有关。如下:
|
** Meta values are as follows: ** meta[0] Schema cookie. Changes with each schema change. ** meta[1] File format of schema layer. ** meta[2] Size of the page cache. ** meta[3] Use freelist if 0. Autovacuum if greater than zero. ** meta[4] Db text encoding. 1:UTF-8 2:UTF-16LE 3:UTF-16BE ** meta[5] The user cookie. Used by the application. ** meta[6] ** meta[7] ** meta[8] ** meta[9] |
1.2.4、读取文件头
当应用程序调用API sqlite3_open打开数据库文件时,SQLite就会读取文件头进行数据库的初始化。
int sqlite3BtreeOpen(
const char *zFilename, /* Name of the file containing the BTree database */
sqlite3 *pSqlite, /* Associated database handle */
Btree **ppBtree, /* Pointer to new Btree object written here */
int flags /* Options */
){
//读取文件头
sqlite3pager_read_fileheader(pBt->pPager, sizeof(zDbHeader), zDbHeader);
//设置页面大小
pBt->pageSize = get2byte(&zDbHeader[16]);
//…
}
SQLite入门与分析(八)---存储模型(1)的更多相关文章
- SQLite入门与分析(八)---存储模型(2)
3.页面结构(page structure) 数据库文件分成固定大小的页面.SQLite通过B+tree模型来管理所有的页面.页面(page)分三种类型:要么是tree page,或者是overflo ...
- SQLite入门与分析(八)---存储模型(3)
写在前面:接上一节,本节主要讨论索引页面格式,以及索引与查询优化的关系. (1)索引页面格式sqlite> select * from sqlite_master;table|episodes| ...
- SQLite入门与分析(二)---设计与概念(续)
SQLite入门与分析(二)---设计与概念(续) 写在前面:本节讨论事务,事务是DBMS最核心的技术之一.在计算机科学史上,有三位科学家因在数据库领域的成就而获ACM图灵奖,而其中之一Jim G ...
- SQLite入门与分析(二)---设计与概念
写在前面:谢谢各位的关注,没想到会有这么多人关注.高兴的同时,也感到压力,因为我接触SQLite也就几天,也没在实际开发中用过,只是最近项目的需求才来研究它,所以我很担心自己的文章是否会有错误,误导别 ...
- SQLite入门与分析(四)---Page Cache之事务处理(1)
写在前面:从本章开始,将对SQLite的每个模块进行讨论.讨论的顺序按照我阅读SQLite的顺序来进行,由于项目的需要,以及时间关系,不能给出一个完整的计划,但是我会先讨论我认为比较重要的内容.本节讨 ...
- SQLite入门与分析(三)---内核概述(2)
写在前面:本节是前一节内容的后续部分,这两节都是从全局的角度SQLite内核各个模块的设计和功能.只有从全局上把握SQLite,才会更容易的理解SQLite的实现.SQLite采用了层次化,模块化的设 ...
- SQLite入门与分析(四)---Page Cache之事务处理(2)
写在前面:个人认为pager层是SQLite实现最为核心的模块,它具有四大功能:I/O,页面缓存,并发控制和日志恢复.而这些功能不仅是上层Btree的基础,而且对系统的性能和健壮性有关至关重要的影响. ...
- SQLite入门与分析(三)---内核概述(1)
写在前面:从本章开始,我们开始进入SQLite的内核.为了能更好的理解SQLite,我先从总的结构上讨论一下内核,从全局把握SQLite很重要.SQLite的内核实现不是很难,但是也不是很简单.总的来 ...
- SQLite入门与分析(七)---浅谈SQLite的虚拟机
写在前面:虚拟机技术在现在是一个非常热的技术,它的历史也很悠久.最早的虚拟机可追溯到IBM的VM/370,到上个世纪90年代,在计算机程序设计语言领域又出现一件革命性的事情——Java语言的出现,它与 ...
随机推荐
- 一个ASP函数库
<% '****************************** '类名: '名称:通用库 '日期:2008/10/28 '作者:by xilou '网址: '描述:通用库 '版权:转载请注 ...
- items 与iteritems
dict的items函数返回的是键值对的元组的列表,而iteritems使用的是键值对的generator. items当使用时会调用整个列表 iteritems当使用时只会调用值. >> ...
- JavaScript高级程序设计(九):基本概念----语句的特殊点
一.Label语句.break/continue语句和for循环语句的结合使用: 1.Label语句可以在代码中添加标签,以便将来使用.语法: label:statment eg: start:f ...
- iOS开发——百度云推送
由于公司项目是集成的极光推送,详见下一篇博客. 集成百度推送大体相当,最好都参考官方文档集成,官方文档或官方网站教程是最好的博客. 百度Push服务SDK用户手册(iOS版) http://push. ...
- Python快速入门学习笔记(二)
注:本学习笔记参考了廖雪峰老师的Python学习教程,教程地址为:http://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb49318210 ...
- I/O继承关系图
InputStream/OutputStream继承关系图
- 文件服务——Vsftpd
文件传输协议(FTP): 能够让用户在互联网中上传.下载文件的文件协议,FTP服务就是支持FTP传输协议的主机,要想完成文件传输则需要FTP服务端和FTP客户端的配合才行. 通常用户使用FTP客户端软 ...
- day19 数据库的初步认识
一:数据库的概念 数据库:一个用于储存数据并可以对之进行管理和使用的软件系统. sql:struct(结构) query(查询) language(语言) 结构化查询语言: 其实是一种国际化语言标 ...
- Java知识总结--三大框架
1 应用服务器有哪些:weblogic,jboss,tomcat 2 Hibernate优于JDBC的地方 1)对jdbc访问数据库进行了封装,简化了数据访问层的重复代码 2)Hibernate 操作 ...
- PHPCMS二次开发教程(转)
转自:http://www.cnblogs.com/semcoding/p/3347600.html PHPCMS V9 结构设计 根目录 |–api 结构文件目录 |–caches 缓存文件目录 ...