SQL Server调优系列基础篇 - 并行运算总结(二)
前言
上一篇文章我们介绍了查看查询计划的并行运行方式。
本篇我们接着分析SQL Server的并行运算。
闲言少叙,直接进入本篇的正题。
技术准备
同前几篇一样,基于SQL Server2008R2版本,利用微软的一个更简洁的案例库(Northwind)进行解析。
内容
文章开始前,我们先来回顾上一篇中介绍的并行运算,来看文章最后介绍的并行运算语句:
SELECT B1.[KEY],B1.DATA,B2.DATA
FROM BigTable B1 JOIN BigTable2 B2
ON B1.[KEY]=B2.[KEY]
WHERE B1.DATA<
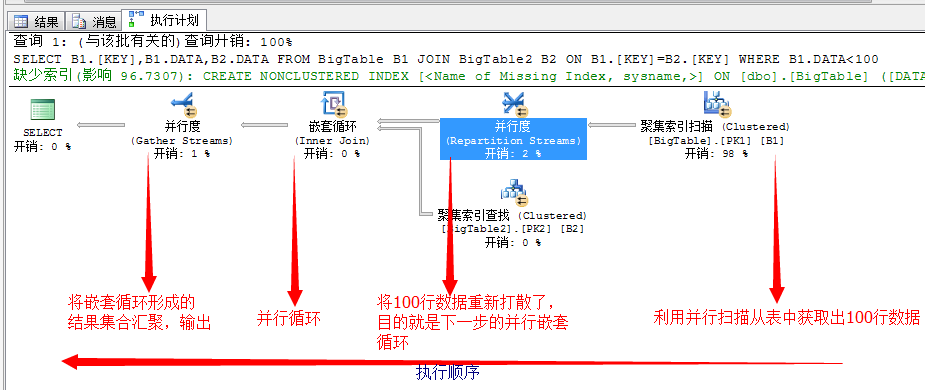
上面是详细的执行计划,从右边依次向左执行,上图中有一个地方很有意思,就是在聚集索引扫描后获取的数据,又重新了使用了一次重新分配任务的过程
(Repartition Streams),就是上图的将获取的100行数据重新分配到并行的各个线程中。
其实这里本可以直接将索引扫描出来的100行数据直接扔到嵌套循环中执行。它这里又重新分配任务的目的就是为了后面嵌套循环的并行执行,最大限度的利用硬件资源!
但这样做又带了另一个弊端就是执行完嵌套循环之后,需要将结果重新汇总,就是下面的(Gather Sreams)运算符。
我们来看看该语句如果不并行的执行计划
SELECT B1.[KEY],B1.DATA,B2.DATA
FROM BigTable B1 JOIN BigTable2 B2
ON B1.[KEY]=B2.[KEY]
WHERE B1.DATA<100
option(maxdop 1)
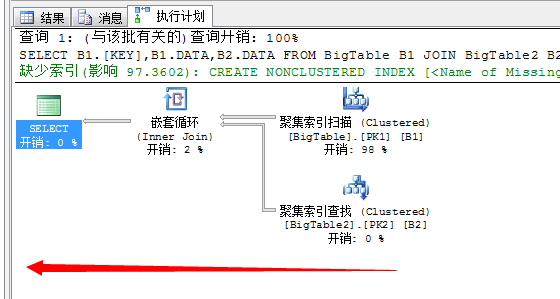
这才是正宗的串行执行计划。
和上面的并行执行计划相比较,你会发现SQL Server充分利用硬件资源而形成的并行计划,是不是很帅!
如果还没感觉到SQL Server并行执行计划的魅力,我们再来举个例子,看如下语句

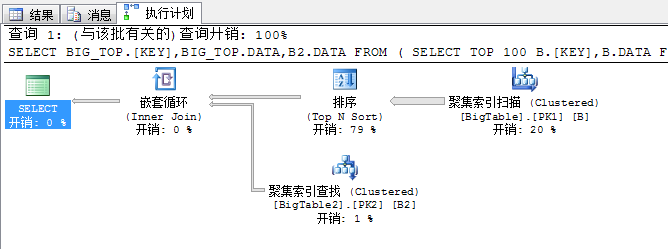
SELECT BIG_TOP.[KEY],BIG_TOP.DATA,B2.DATA
FROM
(
SELECT TOP 100 B.[KEY],B.DATA
FROM BigTable B
ORDER BY DATA
) BIG_TOP,
BigTable2 B2
WHERE BIG_TOP.[KEY]=B2.[KEY]
先来分析下上面的语句,这个语句我们在外表中加入了TOP 100.....ORDER BY DATA关键字,这个关键字是很有意思....
因为我们知道这个语句是获取根据DATA关键字排序,然后获取出前100行的意思...
1、根据DATA排序.....丫的多线程我看你怎么排序?每个线程排列自己的?那你排列完了在汇聚在一起...那岂不是还得重新排序!!
2、获取前100行数据,丫多线程怎么获取?假如我4个线程扫描每个线程获取25条数据?这样出来的结果对嘛?
3、我们的目标是让外表和上面的100行数据还要并行嵌套循环连接,因为这样才能充分利用资源,这个怎么实现呢?
上面的这些问题,我们来看强大的SQL Server将为我们怎样生成强悍的执行计划
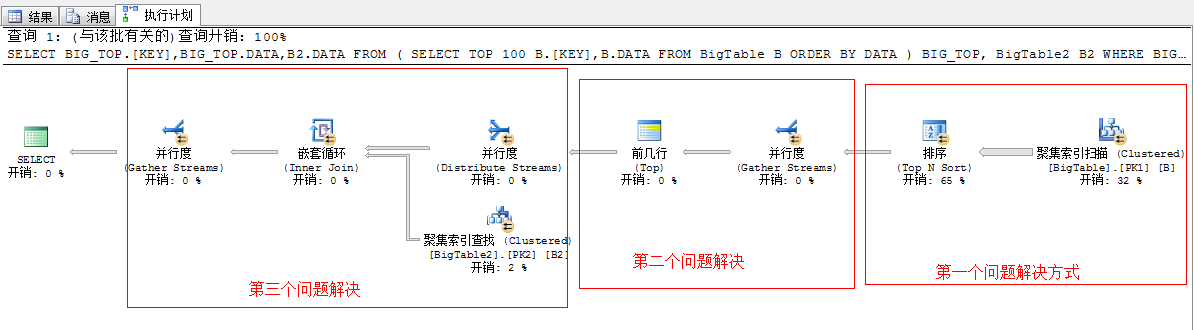
上面的执行计划已经解决了我们以上所述的三个问题,我们依次来分析下,这几个问题的解决方法
第一个问题,关于并列排序问题
首选根据聚集索引扫描的方式采用并列的方式从表中获取出数据
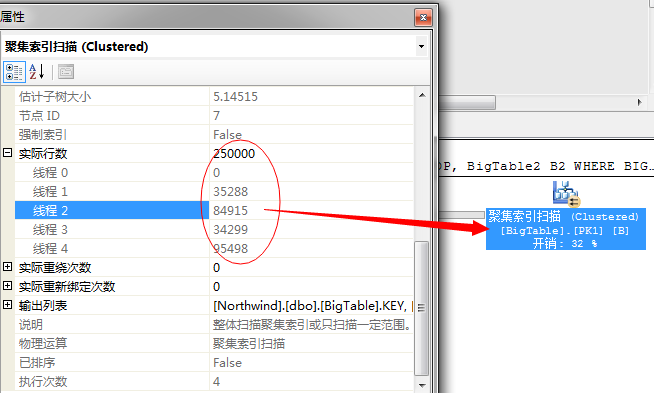
然后,在并行的根据各个线程中的数据进行排序,获取前几列值,我们知道,我们的目标获取的是前100行,它这里获取的方式是冗余获取,也就是说每个线程各自排序自己的数据
然后获取出前面的数据,通过循环赛的方式进行交换,获取出一部分数据
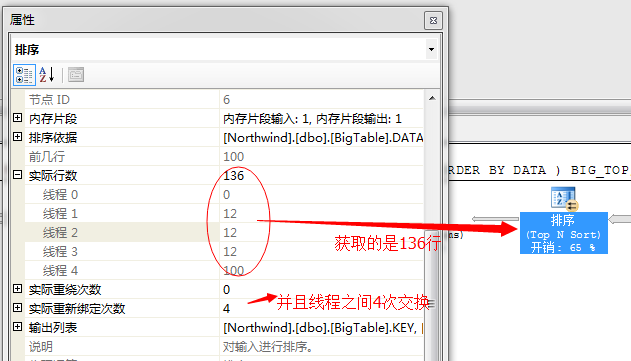
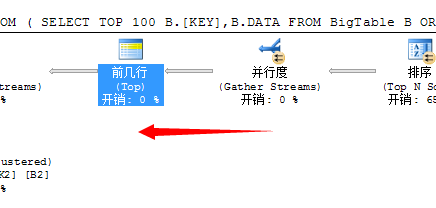
第二个问题,关于并列获取前100行数据问题
我们知道要想获取前100行数据,就必须将各个线程的数据汇总到一起,然后通过比较获取前100行数据,这是必须的,于是在这一步里SQL Server又的重新将数据汇总到一起
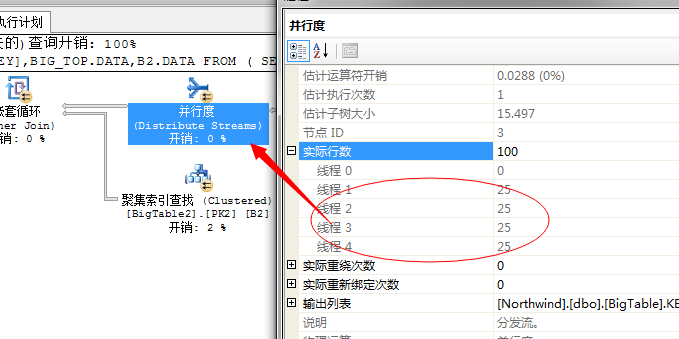
第三个问题,下一步需要将这100行数据和外表进行连接,获取出结果,这里面采用的嵌套循环连接的方式,为了充分利用资源,提升性能,SQL Server又不得不将这100行数据均分到各个线程中去执行,所以这里又采用了一个拆分任务的运算符分发流(Distribute Sreams)任务
所以经过此步骤又将系统的硬件资源充分利用起来了,然后下一步同样就是讲过嵌套循环进行关联获取结果,然后再重新将结果汇总,然后输出
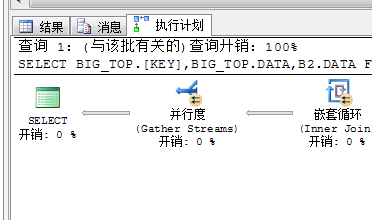
我们可以看到上面的一个流程,SQLServer经过了:先拆分(并行扫描)——》再并行(获取TOP 100....)——》再拆分(为了并行嵌套循环)——》再并行(为了合并结果)
总之,SQL Server在运行语句的时候,经过各种评估之后,利用各种拆分、各种汇总,目的就是充分的利用硬件资源,达到一个性能最优化的方式!这就是SQL Server并行运算的精髓。
当然凡事有利就有弊,我们通过这条语句来对比一下串行和并行在SQL Server中的优劣项
一下是串行执行计划:
SELECT BIG_TOP.[KEY],BIG_TOP.DATA,B2.DATA
FROM
(
SELECT TOP 100 B.[KEY],B.DATA
FROM BigTable B
ORDER BY DATA
) BIG_TOP,
BigTable2 B2
WHERE BIG_TOP.[KEY]=B2.[KEY]
option(maxdop 1)
串行执行的执行计划:简单、大气、没有复杂的各种拆分、各种汇总及并行。
我们来比较下两者的不同项,先比较一个T-SQL语句的各个参数值:
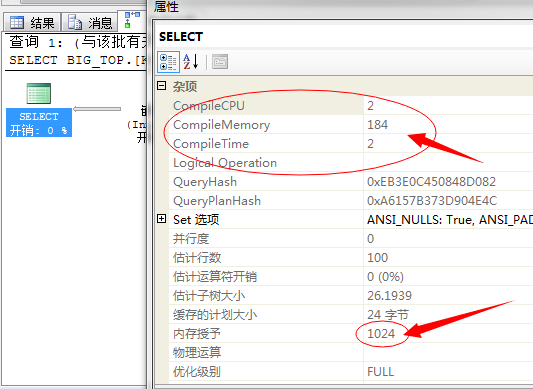
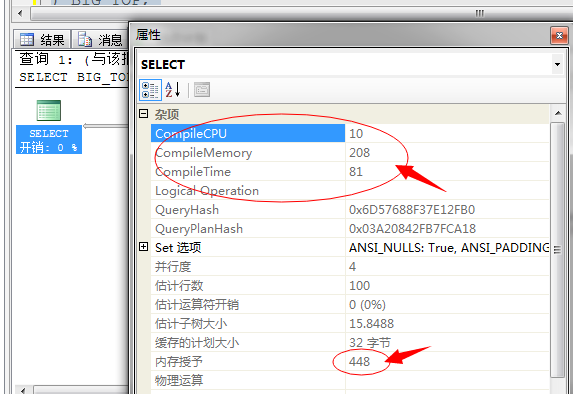
前者是串行、后者是并行
串行编译耗费CPU:2、并行编译耗费CPU:10
串行编译耗费内存:184、并行编译耗费内存:208
串行编译耗时:2、并行编译耗时:81
上面是采取并行的缺点:1、更消耗CPU、2、编译更消耗内存、3、编译时间更久
我们来看一下并行的优点:
上图中串行内存使用(1024),并行内存(448)
优点就是:并行执行消耗内存更小
当然还有一个更重要的优点:执行速度更快!
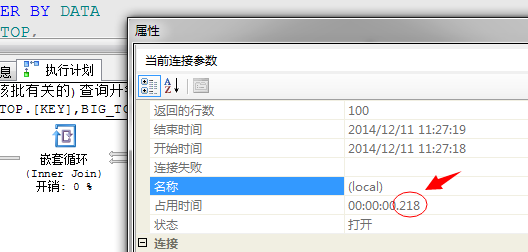
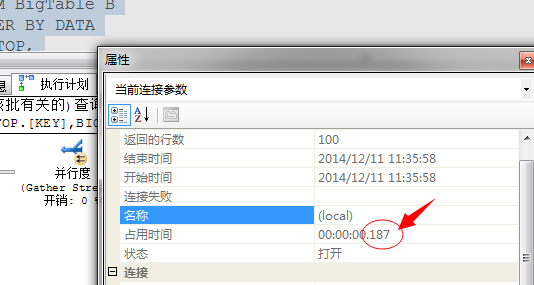
采用并行的执行方式,执行时间从218毫秒提升到187毫秒!数据量少,我机器性能差所以提升不明显!
在并行运算执行过程中,还有一种运算符经常遇到:位图运算符,这里我们顺带也介绍一下
举个例子:
SELECT B1.[KEY],B1.DATA,B2.[KEY]
FROM BigTable B1 JOIN BigTable2 B2
ON B1.DATA=B2.DATA
WHERE B1.[KEY]<
这里我们获取大表中Key列小于10000行的数据。
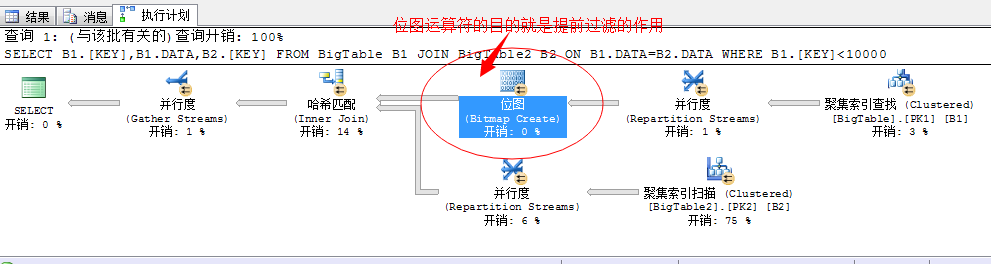
上述的执行语句,就引入了位图计算。
其实位图计算的目标很简单:提前过滤,因为我们的语句中要求获取的结果项比较多10000行数据,在我们后面的线程中采用的并行扫描的方式获取出数据。由于数据量比较多的原因,各个线程在执行的过程中获取完数据的时间不同,为了避免因某个线程执行速度缓慢,导致整体堵塞,索引引入了位图运算,先将获取出来的部分结果过滤输出到前面的哈希匹配,完整执行。
关于位图运算符更多详细可参照:http://msdn.microsoft.com/zh-cn/library/bb510541
结语
此篇文章先到此吧,本篇主要是上一篇并行运算的一个延续,两篇文章介绍了SQL Server中关于并行运算的原理和使用方式,关于并行运算这块就到这吧,下一篇我们补充SQL Server中关于索引的利用方式和动态索引的内容,关于索引我相信很多了解数据库产品的人都熟悉,但是SQL Server中一些语句利用索引的方式可能还不清楚,我们下一篇分析这块,借此了解索引的建立方式和优化技巧,有兴趣可提前关注,关于SQL Server性能调优的内容涉及面很广,后续文章中依次展开分析。
SQL Server调优系列基础篇 - 并行运算总结(二)的更多相关文章
- SQL Server 调优系列基础篇 - 并行运算总结(二)
前言 上一篇文章我们介绍了查看查询计划的并行运行方式. 本篇我们接着分析SQL Server的并行运算. 闲言少叙,直接进入本篇的正题. 技术准备 同前几篇一样,基于SQL Server2008R2版 ...
- SQL Server调优系列基础篇 - 并行运算总结(一)
前言 上三篇文章我们介绍了查看查询计划的方式,以及一些常用的连接运算符.联合运算符的优化技巧. 本篇我们分析SQL Server的并行运算,作为多核计算机盛行的今天,SQL Server也会适时调整自 ...
- SQL Server 调优系列基础篇 - 并行运算总结(一)
前言 上三篇文章我们介绍了查看查询计划的方式,以及一些常用的连接运算符.联合运算符的优化技巧. 本篇我们分析SQL Server的并行运算,作为多核计算机盛行的今天,SQL Server也会适时调整自 ...
- SQL Server调优系列基础篇(并行运算总结)
前言 上三篇文章我们介绍了查看查询计划的方式,以及一些常用的连接运算符.联合运算符的优化技巧. 本篇我们分析SQL Server的并行运算,作为多核计算机盛行的今天,SQL Server也会适时调整自 ...
- SQL Server调优系列基础篇(并行运算总结篇二)
前言 上一篇文章我们介绍了查看查询计划的并行运行方式. 本篇我们接着分析SQL Server的并行运算. 闲言少叙,直接进入本篇的正题. 技术准备 同前几篇一样,基于SQL Server2008R2版 ...
- SQL Server调优系列基础篇(常用运算符总结——三种物理连接方式剖析)
前言 上一篇我们介绍了如何查看查询计划,本篇将介绍在我们查看的查询计划时的分析技巧,以及几种我们常用的运算符优化技巧,同样侧重基础知识的掌握. 通过本篇可以了解我们平常所写的T-SQL语句,在SQL ...
- SQL Server调优系列基础篇(联合运算符总结)
前言 上两篇文章我们介绍了查看查询计划的方式,以及一些常用的连接运算符的优化技巧,本篇我们总结联合运算符的使用方式和优化技巧. 废话少说,直接进入本篇的主题. 技术准备 基于SQL Server200 ...
- SQL Server调优系列基础篇(索引运算总结)
前言 上几篇文章我们介绍了如何查看查询计划.常用运算符的介绍.并行运算的方式,有兴趣的可以点击查看. 本篇将分析在SQL Server中,如何利用先有索引项进行查询性能优化,通过了解这些索引项的应用方 ...
- SQL Server调优系列基础篇(子查询运算总结)
前言 前面我们的几篇文章介绍了一系列关于运算符的介绍,以及各个运算符的优化方式和技巧.其中涵盖:查看执行计划的方式.几种数据集常用的连接方式.联合运算符方式.并行运算符等一系列的我们常见的运算符.有兴 ...
随机推荐
- boost总结之any
boost中any库相对variant简单,any可以不限定类型,variant中对我们事先会定义好我们所需的类型,但是any无此限制,any的类型检测是在run time时. boost::an ...
- mysqld_multi配置MySQL多实例
# This is an example of a my.cnf file for mysqld_multi.# Usually this file is located in home dir ~/ ...
- [摘]selenium-ide编辑命令
----//编辑命令 selenium为我们录制的脚本不是100%符合我们的需求的,所以,编辑录制的脚本是必不可少的工作. 1. 编辑一行命令或注释. 在Table标签下选中某一行命令,命令由com ...
- opencv保存选择图像中的区域
在自己建立行人检测的图像库时用到,参考别人的修改了一下: #include "opencv2/core/core.hpp" #include "opencv2/highg ...
- 【HTML】Advanced4:Accessible Links
1.Tab <ul> <li><a href="here.html" tabindex="1">Here</a> ...
- POJ-3070Fibonacci(矩阵快速幂求Fibonacci数列) uva 10689 Yet another Number Sequence【矩阵快速幂】
典型的两道矩阵快速幂求斐波那契数列 POJ 那是 默认a=0,b=1 UVA 一般情况是 斐波那契f(n)=(n-1)次幂情况下的(ans.m[0][0] * b + ans.m[0][1] * a) ...
- 只需三步:使用C# 操作 Azure 队列
Step 1 : 安装windows Azure package Step 2 : 配置文件增加: <appSettings> <add key="StorageConne ...
- 用BigDecimal类实现Fibonacci算法
Fibonacci(N)=Fibonacii(N-1)+Fibonacci(N-2) 其中 Fibonacci(0)=0;Fibonacci(1)=1 用循环或则递归实现Fibonacci算法很简单, ...
- Redis常用数据类型
Redis常用数据类型 转载自:http://blog.sina.com.cn/s/blog_7f37ddde0101021q.html Redis最为常用的数据类型主要有以下五种: ●Str ...
- DevExpress GridControl 显示行号、设置行号宽
显示行号类 /// <summary> /// GridView 显示行号 设置行号列的宽度 /// </summary> /// <param name="g ...