并发队列之PriorityBlockingQueue
这一篇说一下PriorityBlockingQueue,引用书中的一句话:这就是带优先级的无界阻塞队列,每次出队都返回优先级最高或者最低的元素(这里规则可以自己制定),内部是使用平衡二叉树实现的,遍历不保证有序;
其实也比较容易,就是基于数组实现的一个平衡二叉树,不了解平衡二叉树的可以先了解一下,别想的太难,原理跟链表差不多,只不过链表中指向下一个节点的只有一个,而平衡二叉树中有两个,一个左,一个右,还有左边的节点的值小于当前节点的值,右边节点的值大于当前节点的值;看看平衡二叉树的增删改查即可;
一.认识PriorityBlockingQueue
底层是以数组实现的,我们看看几个重要的属性:
//队列默认初始化容量
private static final int DEFAULT_INITIAL_CAPACITY = 11;
//数组最大容量
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
//底层实现还是数组
private transient Object[] queue;
//队列容量
private transient int size;
//一个比较器,比较元素大小
private transient Comparator<? super E> comparator;
//一个独占锁,控制同时只有一个线程在入队和出队
private final ReentrantLock lock;
//如果队列是空的,还有线程来队列取数据,就阻塞
//这里只有一个条件变量,因为这个队列是无界的,向队列中插入数据的话就用CAS操作就行了
private final Condition notEmpty;
//一个自旋锁,CAS使得同时只有一个线程可以进行扩容,0表示没有进行扩容,1表示正在进行扩容
private transient volatile int allocationSpinLock;
简单看看构造器:
//默认数组大小是11
public PriorityBlockingQueue() {
this(DEFAULT_INITIAL_CAPACITY, null);
}
//可以指定数组大小
public PriorityBlockingQueue(int initialCapacity) {
this(initialCapacity, null);
}
//初始化数组、锁、条件变量还有比较器
public PriorityBlockingQueue(int initialCapacity,
Comparator<? super E> comparator) {
if (initialCapacity < 1)
throw new IllegalArgumentException();
this.lock = new ReentrantLock();
this.notEmpty = lock.newCondition();
this.comparator = comparator;
this.queue = new Object[initialCapacity];
}
//这个构造器也可以传入一个集合
public PriorityBlockingQueue(Collection<? extends E> c) {
this.lock = new ReentrantLock();
this.notEmpty = lock.newCondition();
boolean heapify = true; // true if not known to be in heap order
boolean screen = true; // true if must screen for nulls
if (c instanceof SortedSet<?>) {
SortedSet<? extends E> ss = (SortedSet<? extends E>) c;
this.comparator = (Comparator<? super E>) ss.comparator();
heapify = false;
}
else if (c instanceof PriorityBlockingQueue<?>) {
PriorityBlockingQueue<? extends E> pq =
(PriorityBlockingQueue<? extends E>) c;
this.comparator = (Comparator<? super E>) pq.comparator();
screen = false;
if (pq.getClass() == PriorityBlockingQueue.class) // exact match
heapify = false;
}
Object[] a = c.toArray();
int n = a.length;
// If c.toArray incorrectly doesn't return Object[], copy it.
if (a.getClass() != Object[].class)
a = Arrays.copyOf(a, n, Object[].class);
if (screen && (n == 1 || this.comparator != null)) {
for (int i = 0; i < n; ++i)
if (a[i] == null)
throw new NullPointerException();
}
this.queue = a;
this.size = n;
if (heapify)
heapify();
}
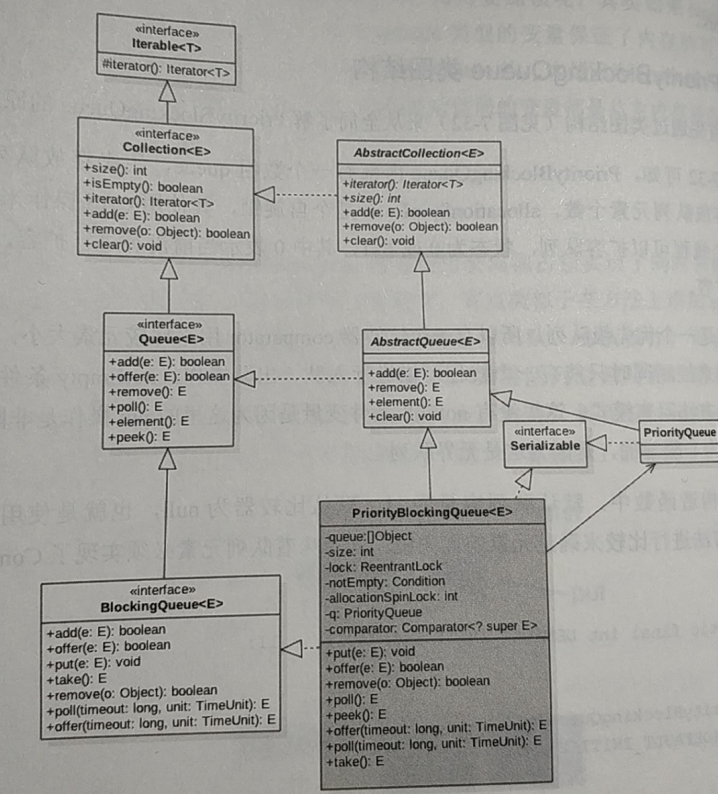
有兴趣的可以看看下面这个图,说的更详细,个人觉得看重要的地方就行了;
二.offer方法
在队列中插入一个元素,由于是无界队列,所以一直返回true;
public boolean offer(E e) {
//如果传入的是null,就抛异常
if (e == null)
throw new NullPointerException();
final ReentrantLock lock = this.lock;
//获取锁
lock.lock();
int n, cap;
Object[] array;
//[1]当前数组中实际数据总数>=数组容量,就进行扩容
while ((n = size) >= (cap = (array = queue).length))
//扩容
tryGrow(array, cap);
try {
Comparator<? super E> cmp = comparator;
//[2]默认比较器为空时
if (cmp == null)
siftUpComparable(n, e, array);
else
//[3]默认比较器不为空就用我们传进去的默认比较器
siftUpUsingComparator(n, e, array, cmp);
//数组实际数量加一
size = n + 1;
//唤醒notEmpty条件队列中的线程
notEmpty.signal();
} finally {
//释放锁
lock.unlock();
}
return true;
}
上面的代码中,我们就关注那三个地方就行了,首先是[1]中扩容:
private void tryGrow(Object[] array, int oldCap) {
//首先释放获取的锁,这里不释放也行,只是扩容有的时候很慢,需要花时间,此时入队和出队操作就不能进行了,极大地降低了并发性
lock.unlock(); // must release and then re-acquire main lock
Object[] newArray = null;
//自旋锁为0表示队列此时没有进行扩容,然后用CAS将自旋锁从0该为1
if (allocationSpinLock == 0 && UNSAFE.compareAndSwapInt(this, allocationSpinLockOffset, 0, 1)) {
try {
//用这个算法确定扩容后的数组容量,可以看到如果当前数组容量小于64,新数组容量就是2n+2,大于64,新的容量就是3n/2
int newCap = oldCap + ((oldCap < 64) ? (oldCap + 2) : (oldCap >> 1));
//判断新的数组容量是不是超过了最大容量,如果超过了,就尝试在老的数组容量加一,如果还是大于最大容量,就抛异常了
if (newCap - MAX_ARRAY_SIZE > 0) { // possible overflow
int minCap = oldCap + 1;
if (minCap < 0 || minCap > MAX_ARRAY_SIZE)
throw new OutOfMemoryError();
newCap = MAX_ARRAY_SIZE;
}
if (newCap > oldCap && queue == array)
newArray = new Object[newCap];
} finally {
//扩容完毕就将自旋锁变为0
allocationSpinLock = 0;
}
}
//第一个线程在上面的if中执行CAS成功之后,第二个线程就会到这里,然后执行yield方法让出CPU,尽量让第一个线程执行完毕;
if (newArray == null) // back off if another thread is allocating
Thread.yield();
//前面释放锁了,这里要获取锁
lock.lock();
//将原来的数组中的元素复制到新数组中
if (newArray != null && queue == array) {
queue = newArray;
System.arraycopy(array, 0, newArray, 0, oldCap);
}
}
再看[2]中的默认的比较器:
//这里k表示数组中实际数量,x表示要插入到数组中的数据,array表示存放数据的数组
private static <T> void siftUpComparable(int k, T x, Object[] array) {
//由此可知,我们要放进数组中的数据类型,必须要是实现了Comparable接口的
Comparable<? super T> key = (Comparable<? super T>) x;
//这里判断数组中有没有数据,第一次插入数据的时候,k=0,不满足这个循环条件,那就直接走最下面设置array[0] = key
//满足这个条件的话,首先获取父节点的索引,然后取出值,再比较该值和需要插入值的大小,决定是跳出循环还是继续循环
//这里比较重要,这个循环就是不断的调整二叉树平衡的,下面我们画图看看
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = array[parent];
if (key.compareTo((T) e) >= 0)
break;
array[k] = e;
k = parent;
}
array[k] = key;
}
随便举个例子看看怎么把平衡二叉树中的元素放到数组中,节点中的数据类型就以Integer了,其实就是将每一层从做到右一次放到数组中存起来,很明显,在数组中不是从小到大的顺序的;
这里注意一点,平衡二叉树的存放顺序不是唯一的,有很多种情况,跟你的存放顺序有关!

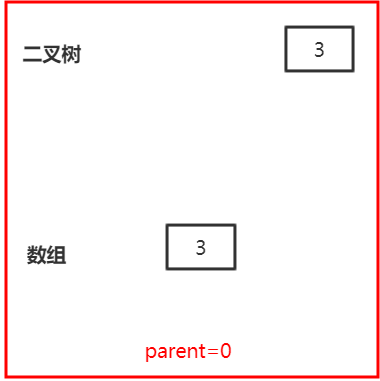
所以我们看看siftUpComparable方法中的while循环是怎么进行的?假设第一次调用offer(3),也就是调用siftUpComparable(0,3,array),这里假设array有足够的大小,不考虑扩容,那么第一次会走到while循环后面执行array[0]=3,下图所示:
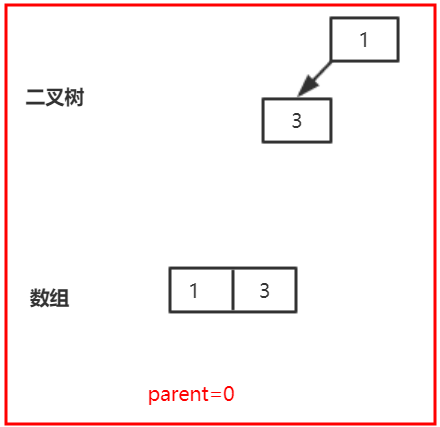
第二次调用offer(1),也就是调用siftUpComparable(1,1,array),k=1,parent=0,所以父节点此时应该是3,然后1<3,不满足if语句,设置array[1]=3,k=0,然后继续循环不满足条件,执行array[0]=1,下图所示:
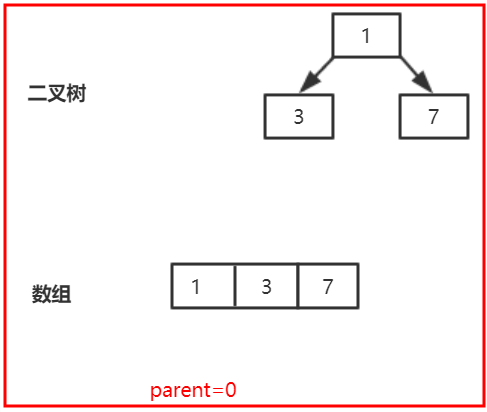
第三次调用offer(7),也就是调用siftUpComparable(2,7,array),k=2,parent=0,父节点为索引0的位置也就是1,因为7>1满足if语句,所以break跳出循环,执行array[2]=7,下图所示:
第四次调用offer(2),也就是调用siftUpComparable(3,2,array),k=3,parent=(k-1)>>>1=1,所以父节点表示索引为1的位置,也就是3,因为2<3,不满足if语句,所以设置array[3]=3,k=1,再进行一次循环,parent=0,此时父节点的值是1,2<3,不满足if,设置array[1]=1,k=0;再继续循环不满足循环条件,跳出循环,设置array[0] = 2

还是很容易的,有兴趣的话再多试试添加几个节点啊!其实还有[3]中使用我们自定义的比较器进行比较,其实i和上面代码一样的,另外put方法就是调用的offer方法,这里就不多说了
三.poll方法
poll方法的作用是获取并删除队列内部二叉树的根节点,如果队列为空,就返回nul;
public E poll() {
final ReentrantLock lock = this.lock;
//获取独占锁,说明此时不能有其他线程进行入队和出队操作,但是可以进行扩容
lock.lock();
try {
//获取并删除根节点,方法如下
return dequeue();
} finally {
//释放独占锁
lock.unlock();
}
}
//这个方法可以好好看看,很有意思
private E dequeue() {
int n = size - 1;
//如果队列为空,就返回null
if (n < 0)
return null;
else {
//否则就先取到数组
Object[] array = queue;
//取到第0个元素,这个也就是要返回的根节点
E result = (E) array[0];
//获取队列实际数量的最后一个元素,并把该位置赋值为null
E x = (E) array[n];
array[n] = null;
Comparator<? super E> cmp = comparator;
if (cmp == null)
//默认的比较器,这里是真正的移除根节点,然后调整在整个平衡二叉树,使得达到平衡
siftDownComparable(0, x, array, n);
else
//我们传入的自定义比较器
siftDownUsingComparator(0, x, array, n, cmp);
//然后数量减一
size = n;
//返回根节点
return result;
}
}
private static <T> void siftDownComparable(int k, T x, Object[] array, int n) {
if (n > 0) {
Comparable<? super T> key = (Comparable<? super T>)x;
//[1]
int half = n >>> 1; // loop while a non-leaf
//[2]
while (k < half) {
int child = (k << 1) + 1; // assume left child is least
Object c = array[child];
int right = child + 1;
//[3]
if (right < n &&((Comparable<? super T>) c).compareTo((T) array[right]) > 0)
c = array[child = right];
//[4]
if (key.compareTo((T) c) <= 0)
break;
array[k] = c;
k = child;
}
array[k] = key;
}
}
所以我们主要的是看看siftDownComparable方法中是怎么将一个去掉了根节点的平衡二叉树调整平衡的;比如现在有如下所示的平衡二叉树:

调用poll方法,先是把最后一个元素保存起来x=3,然后将最后一个位置设置为null,此时实际调用的是siftDownComparable(0,3,array,3),key=3,half=1,k=0,n=3,满足[2],于是child=1,c=1,right=2,不满足[3],不满足[4],设置array[0]=1,k=1;继续循环,不满足循环条件,跳出循环,直接设置array[1]=3,最后poll方法返回的时2,下图所示:
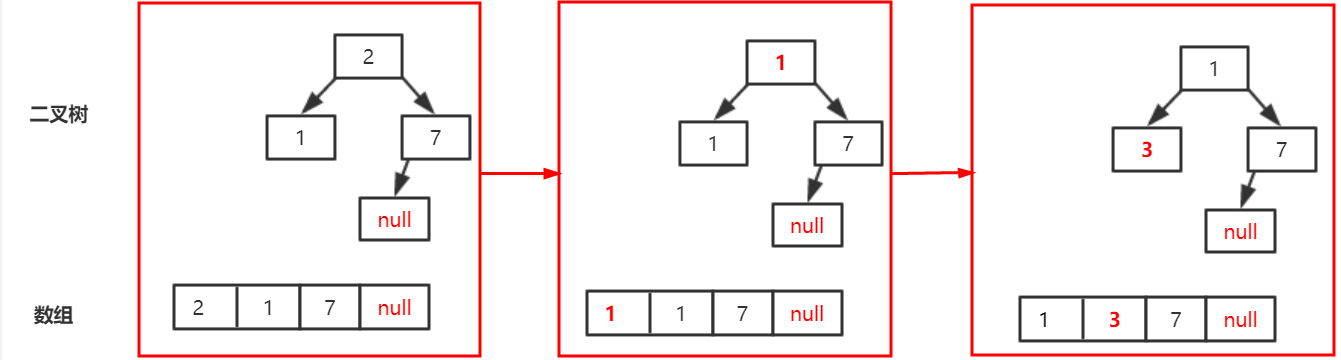
其实可以简单的说说,最开始将数组中最后一个值X保存起来在适当时机插入到二叉树中,什么时候是适当时机呢?首先去掉根节点之后,得到根节点左子节点和右子节点的值leftVal和rightVal,如果X比leftVal小,那就直接把X放入到根节点的位置,整个平衡二叉树就平衡了!如果X比leftVal大,那就将leftVal的值设置到根节点中,再以左子节点做递归,继续比较X和左子节点的左节点的大小!仔细看看也没啥。
四.take方法
这个方法作用是获取二叉树中的根节点,也就是数组的第一个节点,队列为空,就阻塞;
public E take() throws InterruptedException {
//获取锁,可中断
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
E result;
try {
//如果二叉树为空了,那么dequeue方法就会返回null,然后这里就会阻塞
while ( (result = dequeue()) == null)
notEmpty.await();
} finally {
//释放锁
lock.unlock();
}
return result;
}
//这个方法前面说过,就是删除根节点,然后调整平衡二叉树
private E dequeue() {
int n = size - 1;
if (n < 0)
return null;
else {
Object[] array = queue;
E result = (E) array[0];
E x = (E) array[n];
array[n] = null;
Comparator<? super E> cmp = comparator;
if (cmp == null)
siftDownComparable(0, x, array, n);
else
siftDownUsingComparator(0, x, array, n, cmp);
size = n;
return result;
}
}
五.一个简单的例子
前面看了这个多方法,那就说说怎么使用吧,看看PriorityBlockingQueue这个阻塞队列怎么使用;
package com.example.demo.study; import java.util.Random;
import java.util.concurrent.PriorityBlockingQueue; import lombok.Data; public class Study0208 { @Data
static class MyTask implements Comparable<MyTask>{
private int priority=0; private String taskName; @Override
public int compareTo(MyTask o) {
if (this.priority>o.getPriority()) {
return 1;
}
return -1;
}
} public static void main(String[] args) {
PriorityBlockingQueue<MyTask> queue = new PriorityBlockingQueue<MyTask>();
Random random = new Random();
//往队列中放是个任务,从TaskName是按照顺序放进去的,优先级是随机的
for (int i = 1; i < 11; i++) {
MyTask task = new MyTask();
task.setPriority(random.nextInt(10));
task.setTaskName("taskName"+i);
queue.offer(task);
} //从队列中取出任务,这里是按照优先级去拿出来的,相当于是根据优先级做了一个排序
while(!queue.isEmpty()) {
MyTask pollTask = queue.poll();
System.out.println(pollTask.toString());
} } }
并发队列之PriorityBlockingQueue的更多相关文章
- JAVA多线程(二) 并发队列和阻塞队列
github代码地址:https://github.com/showkawa/springBoot_2017/tree/master/spb-demo/spb-brian-query-service/ ...
- 【Java并发】并发队列与线程池
并发队列 阻塞队列与非阻塞队 ConcurrentLinkedQueue BlockingQueue ArrayBlockingQueue LinkedBlockingQueue PriorityBl ...
- 并发队列之DelayQueue
已经说了四个并发队列了,DelayQueue这是最后一个,这是一个无界阻塞延迟队列,底层基于前面说过的PriorityBlockingQueue实现的 ,队列中每个元素都有过期时间,当从队列获取元素时 ...
- 并发队列 ConcurrentLinkedQueue 及 BlockingQueue 接口实现的四种队列
队列是一种特殊的线性表,它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作.进行插入操作的端称为队尾,进行删除操作的端称为队头.队列中没有元素时,称为空队列. 在队列这 ...
- Java多线程之并发包,并发队列
目录 1 并发包 1.1同步容器类 1.1.1Vector与ArrayList区别 1.1.2HasTable与HasMap 1.1.3 synchronizedMap 1.1.4 Concurren ...
- 解读 java 并发队列 BlockingQueue
点击添加图片描述(最多60个字)编辑 今天呢!灯塔君跟大家讲: 解读 java 并发队列 BlockingQueue 最近得空,想写篇文章好好说说 java 线程池问题,我相信很多人都一知半解的,包括 ...
- 10分钟搞定 Java 并发队列好吗?好的
| 好看请赞,养成习惯 你有一个思想,我有一个思想,我们交换后,一个人就有两个思想 If you can NOT explain it simply, you do NOT understand it ...
- Java并发队列与容器
[前言:无论是大数据从业人员还是Java从业人员,掌握Java高并发和多线程是必备技能之一.本文主要阐述Java并发包下的阻塞队列和并发容器,其实研读过大数据相关技术如Spark.Storm等源码的, ...
- Java并发包源码学习系列:基于CAS非阻塞并发队列ConcurrentLinkedQueue源码解析
目录 非阻塞并发队列ConcurrentLinkedQueue概述 结构组成 基本不变式 head的不变式与可变式 tail的不变式与可变式 offer操作 源码解析 图解offer操作 JDK1.6 ...
随机推荐
- 洛谷$P3227\ [HNOI2013]$切糕 网络流
正解:网络流 解题报告: 传送门! 日常看不懂题系列,,,$QAQ$ 所以先放下题目大意趴$QwQ$,就说有个$p\cdot q$的矩阵,每个位置可以填一个$[1,R]$范围内的整数$a_{i,j}$ ...
- 使用这些idea插件让开发效率提高5倍
idea 有很多非常好用的插件,用好了这些插件能够极大的提高开发效率 插件用的好,bug 就追不上了我
- FlyweightPattern(享元模式)-----Java/.Net
享元模式(Flyweight Pattern)主要用于减少创建对象的数量,以减少内存占用和提高性能.这种类型的设计模式属于结构型模式,它提供了减少对象数量从而改善应用所需的对象结构的方式
- 「Main」
这里就是我的小主页辣. My Introduction I am Louch. 姓名:楼翰诚 性别:汉纸 生日:2004/03/09(和加加林同一天呢QAQ) 星座:双鱼座 学校:义乌中学 QQ:10 ...
- 「UVA1328」Period 解题报告
English题面 题意: 给你一个长度为n的字符串,依次取字符串前i个(前缀),如果前缀由k(k>0)个相同真子串构成,那么输出i和k 直到n为0结束,每组数据后要有一行空白 思路: KMP+ ...
- 谁再问elasticsearch集群Red怎么办?把这篇笔记给他
前言 可能你经历过这些Red. ...等等 那ES的Red是神么意思? 这里说的red,是指es集群的状态,一共有三种,green.red.yellow.具体含义: 冷静分析 从上图可知,集群red是 ...
- (二)Angular+spring-security-cas前后端分离(基于ticket代码实现
一.前端实现 1.1.路由守卫(用于拦截路由认证) import { Injectable, Inject } from "@angular/core"; import { Can ...
- IDEA 配置及常用快捷键
常用快捷键 1.Ctrl+Alt+T 把选择的代码放入 try{} 或者 if{} 里 2.Ctrl+O 重写方法提示 3.Alt+回车 导包提示 4.Alt+/ 代码提示(默认不是这个,需要参照后文 ...
- vue中动态设置echarts画布大小
document.getElementById('news-shopPagechart').style.height = this.heightpx2+'px'; //heightpx2定义在data ...
- 开发STM32MP1,你需要一块好开发板
STM32MP1系列的出现吸引了很多STM32的新老用户的关注,但是很多的人都会担心一个问题:以前是基于Cortex M系列MCU惊醒开发,对于cortex-A架构的处理器以及Linux系统都不熟悉. ...