标准方程法_岭回归_LASSO算法_弹性网
程序所用文件:https://files.cnblogs.com/files/henuliulei/%E5%9B%9E%E5%BD%92%E5%88%86%E7%B1%BB%E6%95%B0%E6%8D%AE.zip
标准方程法
标准方程法是求取参数的另一种方法,不需要像梯度下降法一样进行迭代,可以直接进行结果求取

那么参数W如何求,下面是具体的推导过程

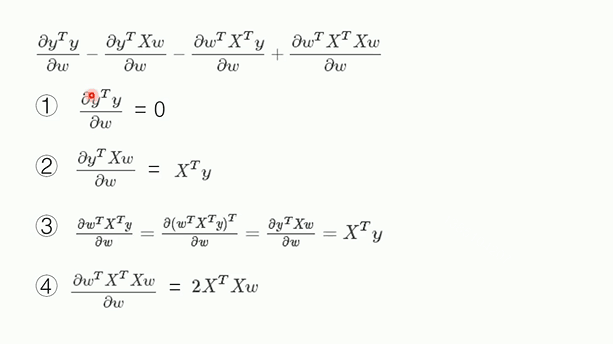

因此参数W可以根据最后一个式子直接求取,但是我们知道,矩阵如果线性相关,那么就无法取逆,如下图

因此,对比梯度下降法和标准方程法我们可以得到下面的图

下面的demo是标准方程法实现拟合
import numpy as np
from matplotlib import pyplot as plt
from numpy import genfromtxt
#载入数据
data = genfromtxt('data.csv',delimiter=',')
x_data = data[:,,np.newaxis]#一维变为二维
y_data = data[:,,np.newaxis]
plt.scatter(x_data,y_data)
plt.show()
print(np.mat(x_data).shape)
print(np.mat(y_data).shape)
#给样本添加偏置项
X_data = np.concatenate((np.ones((,)),x_data),axis=)
print(X_data.shape)
#标准方程法求解回归参数
def weights(xArr, yArr):
xMat = np.mat(xArr)#array变为mat,方便进行矩阵运算
yMat = np.mat(yArr)
xTx = xMat.T * xMat
if np.linalg.det(xTx) == 0.0: #一、np.linalg.det():矩阵求行列式二、np.linalg.inv():矩阵求逆三、np.linalg.norm():求范数
print("该矩阵不可逆")
return
ws = xTx.I * xMat.T * yMat
return ws
ws = weights(X_data,y_data)
print(ws[].shape)
#画图
x_test = np.array([[], []])
print(x_test.shape)
y_test = ws[] + x_test * ws[]
plt.plot(x_data, y_data, 'b.')
plt.plot(x_test, y_test, 'r')
plt.show()
捎带一下两个小的知识点
数据归一化
由于单位的原因,不同单位之间数据产别太大,影响数据分析,所以我们一般会对某些数据进行归一化,即把数据归一化到某个范围之内。


交叉验证
当样本数据比较小的时候,为了避免验证集“浪费”太多的训练数据,采用样本交叉验证的方法,并把平均值作为结果

过拟合,欠拟合,正确拟合
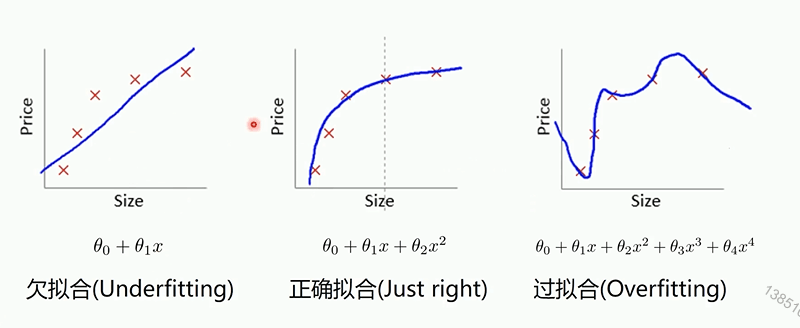
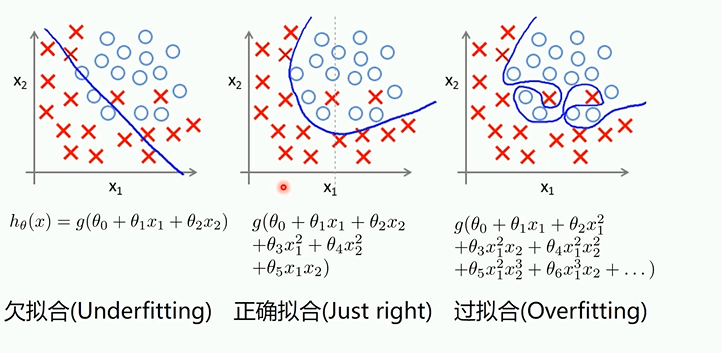
过拟合会导致训练集拟合效果好,测试集效果差,欠拟合都差。为防止过拟合

正则化就是在原来的损失函数基础上加入一项,来减少高次项的值,使得曲线平滑

岭回归
为解决标准方程法中存在的矩阵不可逆问题,引入了岭回归



import numpy as np
from matplotlib import pyplot as plt
from sklearn import linear_model
#读取数据
data = np.genfromtxt("longley.csv", delimiter=',')
print(data)
#切分数据
x_data = data[:,:]
y_data = data[:,]
#创建模型
#生成0.001到1的五十个岭系数值
alphas_to_test = np.linspace(0.001, )#从0.001到1共五十个数据,默认在start和end之间有50个数据,这五十个数据是假设的岭系数
model = linear_model.RidgeCV(alphas= alphas_to_test, store_cv_values= True)#store_cv_values表示存储每个岭系数和样本对应下的损失值
model.fit(x_data, y_data)
print(model.alpha_)#最小损失函数对应的岭系数
print(model.cv_values_.shape)#*50的矩阵
#绘图
#岭系数和loss值得关系
plt.plot(alphas_to_test, model.cv_values_.mean(axis = ))# 求在每个系数下对应的平均损失函数,axis=1表示横轴,方向从左到右;0表示纵轴,方向从上到下
plt.plot(model.alpha_, min(model.cv_values_.mean(axis = )),'ro')#最优点
plt.show()
model.predict(x_data[,np.newaxis])#对一个样本进行预测
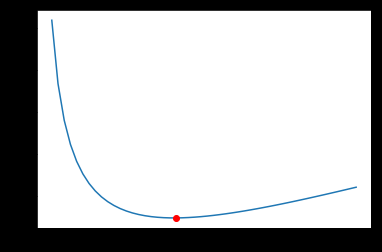 岭系数和损失函数对应的关系图
岭系数和损失函数对应的关系图
简单说一下arange,range,linspace的区别,arange和range都是在start和end之间以step作为等差数列对应的数组,只不过arange的step
可以是小数,而range必须为整数,而且arange属于numpy,linspace则是在start和end之间取num个数 np.linspace(start,end,num)
LASSO算法
由于岭回归计算得到的系数很难为0,而Lasso算法可以使一些指标为0


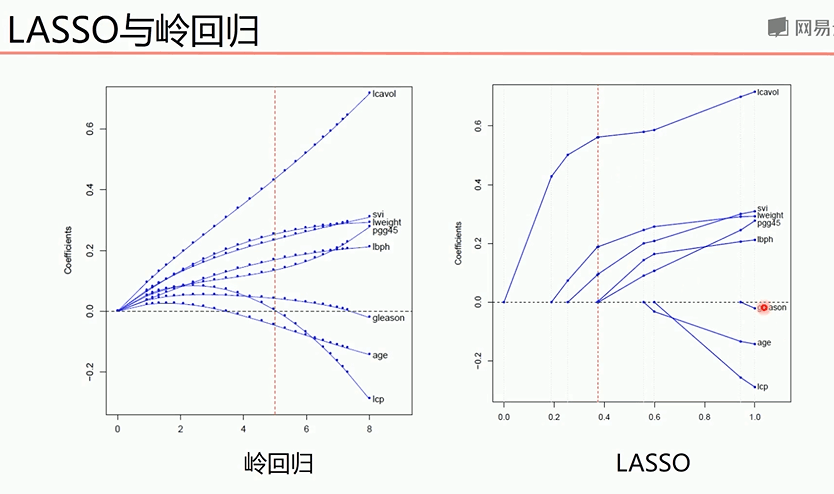
从上图可以看出,LASSo在入系数某个取值下某些特征的系数就归为0了
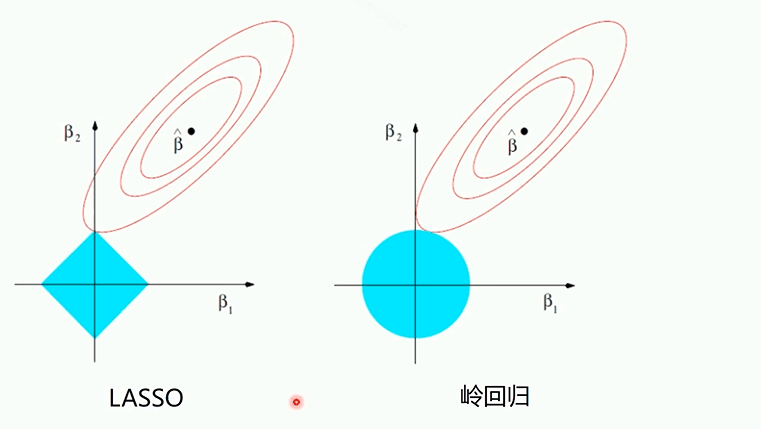
交点处变为最优取值处
import numpy as np
from matplotlib import pyplot as plt
from sklearn import linear_model
#读取数据
data = np.genfromtxt("longley.csv", delimiter=',')
print(data)
#切分数据
x_data = data[:,:]
y_data = data[:,]
#创建模型
model = linear_model.LassoCV()
model.fit(x_data,y_data)
#lasso系数
print(model.alpha_)
#相关系数,发现某些系数为零,说明这些系数权重比较小,可以忽视
print(model.coef_)#[0.10206856 0.00409161 0.00354815 . . . ]
#验证
model.predict(x_data[-,np.newaxis])
弹性网


对lasso和岭系数方法综合起来
import numpy as np
from matplotlib import pyplot as plt
from sklearn import linear_model
#读取数据
data = np.genfromtxt("longley.csv", delimiter=',')
print(data)
#切分数据
x_data = data[:,:]
y_data = data[:,]
#创建模型
model = linear_model.ElasticNetCV()
model.fit(x_data,y_data)
#lasso系数
print(model.alpha_)
#相关系数,发现某些系数为零,说明这些系数权重比较小,可以忽视
print(model.coef_)#[0.10206856 0.00409161 0.00354815 . . . ]
#验证
print(model.predict(x_data[-,np.newaxis]))
标准方程法_岭回归_LASSO算法_弹性网的更多相关文章
- 『算法设计_伪代码』贪心算法_最短路径Dijkstra算法
Dijkstra算法实际上是一个贪婪算法(Greedy algorithm).因为该算法总是试图优先访问每一步循环中距离起始点最近的下一个结点.Dijkstra算法的过程如下图所示. 初始化 给定图中 ...
- Dijkstra算法_北京地铁换乘_android实现-附带源码.apk
Dijkstra算法_北京地铁换乘_android实现 android 2.2+ 源码下载 apk下载 直接上图片 如下: Dijkstra(迪杰斯特拉)算法是典型的最短路径路由算法,用于计 ...
- cb51a_c++_STL_算法_根据第n个元素排序nth_element
cb51a_c++_STL_算法_根据第n个元素排序nth_elementnth_element(b,n,e),比如最大的5个数排序,或者最小的几个数nth_element(b,n,e,p)对比:pa ...
- cb50a_c++_STL_算法_局部排序partial_sort
cb50a_c++_STL_算法_局部排序partial_sort partial_sort(b,se,e)排序一部分,begin,source end,endcout << " ...
- cb49a_c++_STL_算法_对所有元素排序_sort_stable_sort
cb49a_c++_STL_算法_对所有元素排序_sort_stable_sort sort(b,e) sort(b,e,p) stable_sort(b,e) stable_sort(b,e,p) ...
- cb48a_c++_STL_算法_重排和分区random_shuffle_stable_partition
cb48a_c++_STL_算法_重排和分区random_shuffle_stable_partition random_shuffle()//重排,随机重排,打乱顺序 partition()分区,把 ...
- cb47a_c++_STL_算法_排列组合next_prev_permutation
cb47a_c++_STL_算法_排列组合next_prev_permutation 使用前必须先排序.必须是 1,2,3或者3,2,1.否者结果不准确.如果, 1,2,4,6.这样数据不会准确nex ...
- cb46a_c++_STL_算法_逆转和旋转reverse_rotate函数advance
cb46a_c++_STL_算法_逆转和旋转reverse_rotateSTL算法--变序性算法reverse() 逆转reverse_copy()一边复制一般逆转rotate()旋转,某个位置开始前 ...
- cb45a_c++_STL_算法_删除_(3)_unique(唯一的意思)删除连续性的重复的数据
cb45a_c++_STL_算法_删除_(3)_unique(唯一的意思)删除连续性的重复的数据unique(b,e),删除连续性的,删除重复的数据,比如如果有两个连续的5,5,则留下一个.uniqu ...
随机推荐
- Hadoop节点集群挂了,Hbase数据源损坏怎么办
今天集群节点一下子挂了5台,hbase的数据块也损坏. hadoop日志 .0.15:36642 dest: /ip:50010 2014-08-26 15:01:14,918 WARN org.ap ...
- 【POJ】3660 Cow Contest
题目链接:http://poj.org/problem?id=3660 题意:n头牛比赛,有m场比赛,两两比赛,前面的就是赢家.问你能确认几头牛的名次. 题解:首先介绍个东西,传递闭包,它可以确定尽可 ...
- [每日一个小技巧] CentOS 下使用yum安装一类软件包
版权声明:本文为博主原创文章,欢迎转载,转载请注明出处. https://blog.csdn.net/robertsong2004/article/details/37775313 yum 提供了丰富 ...
- OC开发系列-@property和@synthesize
property和synthesize 创建一个Person类.提供成员属性的_age和_height的setter和getter方法. #import <Foundation/Foundati ...
- 笔记:简单的面向对象-web服务器
import socket import re import multiprocessing import time import mini_frame class WSGIServer(object ...
- Linux sed -i 字符串替换
sed -i 直接替换文件中的内容不输出, 如 将 laravel .env中的 QUEUE_DRIVER=sync 替换为 QUEUE_DRIVER=redis, 在Laravel的项目根目录中运行 ...
- The Counting Problem
The Counting Problem 询问区间\([a,b]\)中\(1\sim 9\)出现的次数,0 < a, b < 100000000. 解 显然为数位递推,考虑试填法,现在关键 ...
- CF 540D Bad Luck Island
一看就是DP题(很水的一道紫题) 设\(dp[i][j][k]\)为留下\(i\)个\(r\)族的人,死去\(j\)个\(s\)族的人,死去\(k\)个\(p\)族的人的概率(跟其他的题解有点差别,但 ...
- Python中虚拟环境venv的基本用法
环境windows 7 venv为python3中的默认库,无需安装. 创建新的venv方法, 在当前文件夹下执行cmd,输入如下代码 python -m venv bob bob为需要创建的文件夹名 ...
- 混合云存储组合拳:基于云存储网关与混合云备份的OSS数据备份方案
前言 阿里云对象存储(OSS)用户众多.很多用户因为业务或者合规性需求,需要对OSS内的数据做备份,无论是线上备份,还是线下备份.用户可以选择使用OSS的开放API,按照业务需求,做数据的备份,也可以 ...