DataX的使用——大数据同步技术
准备工作:
1.视频教学http://113.31.104.47/portal/#/course/dashboard/b34d160db64624732ef152a1118af11a
2.DataX的安装部署https://www.cnblogs.com/qingyunzong/p/9759993.html#_label1_0
3.DataX的使用Python版本要求:2.7.X,DataX未更新至Python3Win10下python 2.7与python 3.6双环境安装图文教程
设计json文档:(sqlserver to mysql)
{
"job": {
"setting": {
"speed": {
"channel": 3,
"byte": 1048576
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "sqlserverreader",
"parameter": {
"username": "sa",
"password": "######",
"where": "",
"column": [
"bname",
"bpwd"
],
"connection": [
{
"table": ["buyer"],
"jdbcUrl": [
"jdbc:sqlserver://localhost:1433;DatabaseName=bookshop"
]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "######",
"column": [
"name",
"pwd"
],
"session": [],
"connection": [
{
"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/hotwords?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=GMT%2B8",
"table": ["user"]
}
]
}
}
}
]
}
}
官方解读各个数据库文档https://github.com/alibaba/DataX
运行:
python 空格{datax文件夹路径}\bin\datax.py 空格{json配置文件的路径}
python2 D:\download\datax\datax\bin\datax.py D:\download\datax\job\sqlserverTomysql.json

乱码输入:
CHCP 65001
出错:
ERROR RetryUtil - Exception when calling callable, 即将尝试执行第1次重试.本次重试计划等待[1000]ms,实际等待[1000]ms, 异常Msg:[DataX无法连接对应的数据库,可能原因是:1) 配置的ip/port/database/jdbc错误,无法连接。2) 配置的username/password错误,鉴权失败。请和DBA确认该数据库的连接信息是否正确。]

解决方法:
datax里面的mysql驱动更换成合适的8.x的版本就好了:
查询你的mysql版本,下载相应的mysql-connector jar包
mysql -uroot -p
替换:
datax->plugins->reader->mysqlreader->libs->mysql-connector-5...的jar包换成8.XX的版本
datax->plugins->write->mysqlwriter->libs->coonector-5...的jar包换成8.XX的版本
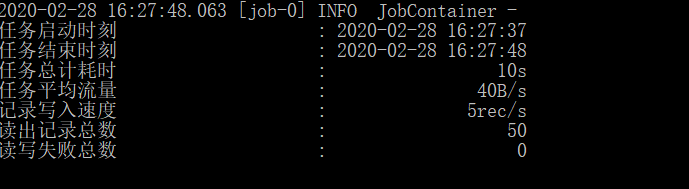
运行成功:
DataX的使用——大数据同步技术的更多相关文章
- 中国大数据六大技术变迁记(CSDN)
大会召开前期,特别梳理了历届大会亮点以记录中国大数据技术领域发展历程,并立足当下生态圈现状对即将召开的BDTC 2014进行展望: 追本溯源,悉大数据六大技术变迁 伴随着大数据技术大会的发展,我们亲历 ...
- 大数据 --> 大数据关键技术
大数据关键技术 大数据环境下数据来源非常丰富且数据类型多样,存储和分析挖掘的数据量庞大,对数据展现的要求较高,并且很看重数据处理的高效性和可用性. 传统数据处理方法的不足 传统的数据采集来源单一,且存 ...
- 一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了
一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了 转载: 大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞生的.你可以把它 ...
- 案例分析:大数据平台技术方案及案例(ppt)
大数据平台是为了计算,现今社会所产生的越来越大的数据量,以存储.运算.展现作为目的的平台.大数据技术是指从各种各样类型的数据中,快速获得有价值信息的能力.适用于大数据的技术,包括大规模并行处理(MPP ...
- AI加持的阿里云飞天大数据平台技术揭秘
摘要:2019云栖大会大数据&AI专场,阿里云智能计算平台事业部研究员关涛.资深专家徐晟来为我们分享<AI加持的阿里云飞天大数据平台技术揭秘>.本文主要讲了三大部分,一是原创技术优 ...
- 大数据-hdfs技术
hadoop 理论基础:GFS----HDFS:MapReduce---MapReduce:BigTable----HBase 项目网址:http://hadoop.apache.org/ 下载路径: ...
- 了解大数据的技术生态系统 Hadoop,hive,spark(转载)
首先给出原文链接: 原文链接 大数据本身是一个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞生的.你能够把它比作一个厨房所以须要的各种工具. 锅碗瓢盆,各 ...
- 一文教你看懂大数据的技术生态圈:Hadoop,hive,spark
转自:https://www.cnblogs.com/reed/p/7730360.html 大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞 ...
- 一文看懂大数据的技术生态Hadoop, hive,spark都有了[转]
大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞生的.你可以把它比作一个厨房所以需要的各种工具.锅碗瓢盆,各有各的用处,互相之间又有重合.你可 ...
随机推荐
- qt中的拖拽及其使用技巧
关于qt中的拖放操作,首先可以看这篇官方文档:http://doc.qt.io/qt-5.5/dnd.html 一.QDrag 首先是创建QDrag,可以在mousePressEvent或者mouse ...
- CSS-18-媒体查询
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- 自学前端开发,现在手握大厂offer,我的故事还在继续
简要背景 我是一个非科班出身的程序员,而且是连续跨专业者,用一句话总结就是:16 届本科学完物流,保送研究生转交通,自学前端开发的休学创业者. 17 年休学创业,正式开始学习前端,离开创业公司后,我又 ...
- mint ui的tabBar监听路由变化实现tabBar切换
说明 最近学习vue,使用了mint ui的tabBar,感觉好难受,结合 tab-container使用更难受,因为它不是根据路由来切换页面的.mui与它基本相反,因此它能根据搜索栏的路由变化,相应 ...
- 1-NoSQL介绍及Redis安装
背景 随着互联网的不断发展和软件架构的不断复杂化,同时随着网站访问量的日渐上升,导致传统单机关系型数据库应用已经无法满足人们的需求,在高并发的场景下,频繁的数据库存取操作使得服务器压力剧增,甚至导致服 ...
- 6、RIP
在路由查找时,有类路由查找方式和无类路由查找的区别:有类路由查找:1.首先匹配主网条目.主网信息2.匹配上主网之后,再去查找子网信息3.查找到子网,就会转发,否则就丢弃4.有一种例外,没有找到主网和子 ...
- eclipse编写代码所遇到的问题
spring方面: 1.Pre-instantiating singletons in org.springframework.beans.factory.support.DefaultListabl ...
- 视觉slam十四讲第七章课后习题6
版权声明:本文为博主原创文章,转载请注明出处: http://www.cnblogs.com/newneul/p/8545450.html 6.在PnP优化中,将第一个相机的观测也考虑进来,程序应如何 ...
- ionic2的返回按钮的编辑问题
ionic2 返回按钮 首先可以在 app.module.ts 文件中配置. @NgModule 中的 imports 属性的 IonicModule.forRoot 第二个参数,如下: IonicM ...
- Go语言实现:【剑指offer】链表中环的入口结点
该题目来源于牛客网<剑指offer>专题. 给一个链表,若其中包含环,请找出该链表的环的入口结点,否则,输出null. Go语言实现: /** * Definition for sing ...