云栖深度干货 | 打造“云边一体化”,时序时空数据库TSDB技术原理深度解密
本文选自云栖大会下一代云数据库分析专场讲师自修的演讲——《TSDB云边一体化时序时空数据库技术揭秘》 自修 —— 阿里云智能数据库产品事业部高级专家


- 这种架构方式被很多数据库系统采用并证明是有效;
- 接口定义清晰,不同的执行计算算子可以独立优化,而不影响其他算子;
- 易于扩展:通过增加新的计算算子,很容易实现扩展功能。比如目前查询协议里只定义了tag上的查询条件。如果要支持指标值上的查询条件(cpu.usage <= 70% and cpu.usage <=90%),可以通过增加一个新的FieldFilterOp来实现
- 从查询优化器到生成执行计划,把查询语句重写成子查询后构建Operator Tree, 执行器驱动Operators完成聚合逻辑,执行Fragment顺序:Filtering -> Grouping -> Downsampling -> Interpolation -> Aggregation -> Rate Conversion -> Functions
- 区分不同查询场景,采用不同聚合算子分别优化,支持结果集的流式读取和物化, Operator的结果在包含None,dsOp等情况下采用流式聚合,而一些时间线之间的聚合仍然是物化运算。
1.水平可扩展集群方案 2.全局内存管理 3.全面兼容TICK生态
- 使用raft实现influxDB数据节点的高可用,同时提供多个高可用方案,让用户可以在可用性和成本中选择最适合自己的方案。
- 阿里云influxDB®支持根据数据量大小,动态增加influxDB数据节点的高可用组。
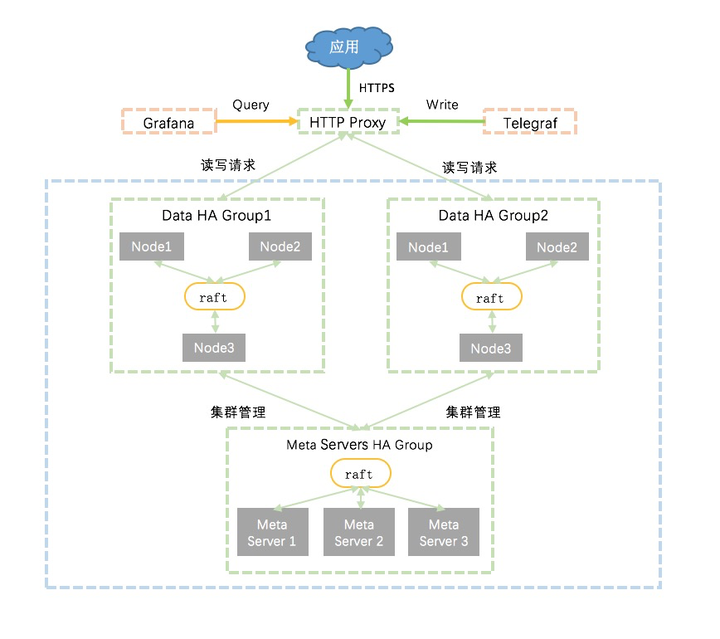
- 阿里云influxDB®通过对influxDB代码的优化,实现了全局内存管理,可以通过动态调整内存使用
- 全局内存管理支持阿里云influxDB创建任意多个database
- 全局内存管理实现了数据写入以及数据查询的内存管理,可以非常显著的防止由于OOM引发的稳定性问题,提高整个系统的可用性
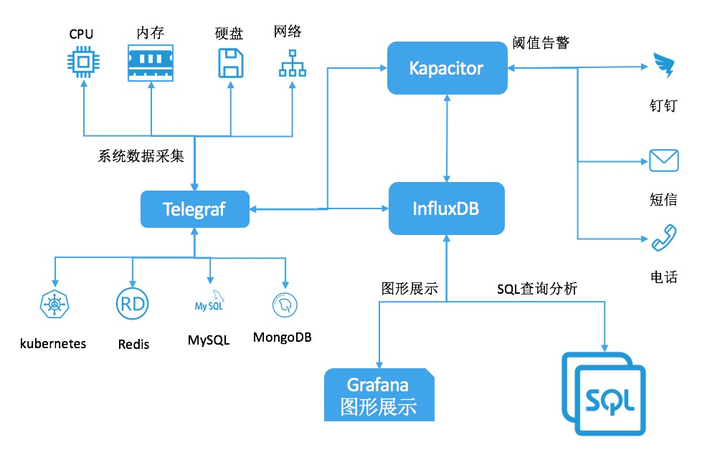
- 阿里云influxDB全面兼容TICK生态,支持对接telegraf,chronograf以及kapacitor
- 除此之外,阿里云influxDB支持对接grafana,用户能够使用更加丰富的图形化工具展示influxDB中的数据
- 阿里云influxDB提供“一键式”的数据采集工具,用户可以非常方便的安装、启动数据采集工具,并且在阿里云管理平台上管理数据采集工具
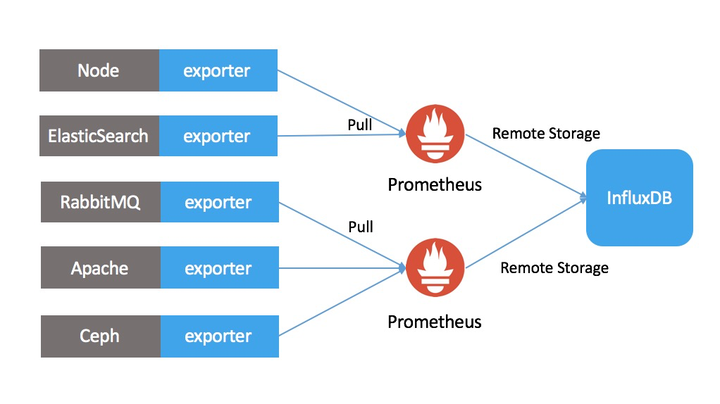
- 无缝对接InfluxDB
- 无需代码修改、仅需修改配置
- InfluxDB通过Remote Storage长期存储Prometheus数据
- InfluxDB远程存储可以实现“多写一读”的查询模式,多个prometheus对接同一个influxDB,允许联合查询多个Prometheus,实现数据“全局化”查询
- InfluxDB高可用为Prometheus提供高可用存储功能
- InfluxDB使用的云盘实现Prometheus数据高可靠,有效防止数据丢失
云栖深度干货 | 打造“云边一体化”,时序时空数据库TSDB技术原理深度解密的更多相关文章
- 打造“云边一体化”,时序时空数据库TSDB技术原理深度解密
本文选自云栖大会下一代云数据库分析专场讲师自修的演讲——<TSDB云边一体化时序时空数据库技术揭秘> 自修 —— 阿里云智能数据库产品事业部高级专家 认识TSDB 第一代时序时空数据处理工 ...
- 云栖大会压轴好戏 阿里云发布视频云V5计划与系列新产品
9月25 - 27日,2019云栖大会如期召开.在大会最后一天下午,阿里云智能视频云分论坛为今年的云栖大会献上了一场精彩的压轴好戏. 视频云V5计划发布 使能生态合作伙伴 会上,阿里云智能研究员金戈进 ...
- 零距离接触阿里云时序时空数据库TSDB
概述 最近,Amazon新推出了完全托管的时间序列数据库Timestream,可见,各大厂商对未来时间序列数据库的重视与日俱增.阿里云TSDB是阿里巴巴集团数据库事业部研发的一款高性能分布式时序时空数 ...
- 非IT人士的云栖酱油之行 (程序猿迷妹的云栖之行)
摘要: 熟悉我的人都知道,我是一个贪玩儿且不学无术的姑娘,对于互联网我也是知之甚少:这次去到杭州参加阿里巴巴集团主办的为期4天的科技大会也是很例外:但是不得不说这次的会议真是让我很震惊.今天我就和大家 ...
- 阿里云发布新版SaaS上云工具包,全面助力SaaS上云
9月26日,在云栖大会SaaS加速器专场上,阿里云发布了新版的SaaS上云工具包(SaaS Launch Kit),发布了API网关的新功能,以及推出了全新升级的能力中心. SaaS上云工具包,顾名思 ...
- 云栖干货回顾 | 云原生数据库POLARDB专场“硬核”解析
POLARDB是阿里巴巴自主研发的云原生关系型数据库,目前兼容三种数据库引擎:MySQL.PostgreSQL.Oracle.POLARDB的计算能力最高可扩展至1000核以上,存储容量可达100TB ...
- 杂项-分布式-EDAS:深度解析阿里云EDAS服务
ylbtech-杂项-分布式-EDAS:深度解析阿里云EDAS服务 1.返回顶部 1. 深度解析阿里云EDAS服务 弹性伸缩 摘要: 第一种只适用于业务较少的情况,而在新业务不断增加的情况下,增加新应 ...
- 2019云栖大会开幕,5G边缘计算成首日焦点
9月25日,全球顶尖科技盛会——2019云栖大会如期上演,1000余位当代技术领军人物与数万名开发者集结杭州,聚焦数字经济,共话面向未来20年的基础科学.科技创新与应用突破.其中,边缘计算技术领域因5 ...
- 2020云栖大会智慧出行专场:聚焦高精地图/算法、智能模型、自动驾驶、AR导航
2020云栖大会将于9月17日-18日在线举行,届时将通过官网为全球科技人带来前沿科技.技术产品.产业应用等领域的系列重要分享. 阿里巴巴高德地图携手合作伙伴精心筹备了“智慧出行”专场.我们将为大 ...
随机推荐
- Python学习之路7☞装饰器
一:命名空间与作用域 1.1命名空间 局部命名空间: def foo(): x=1 def func(): pass 全局命名空间: import time class ClassName:pass ...
- Introduction to 3D Game Programming with DirectX 12 学习笔记之 --- 第十二章:几何着色器(The Geometry Shader)
原文:Introduction to 3D Game Programming with DirectX 12 学习笔记之 --- 第十二章:几何着色器(The Geometry Shader) 代码工 ...
- phpcms分类信息地区识别跳转
<script src="http://int.dpool.sina.com.cn/iplookup/iplookup.php?format=js"></scri ...
- Libevent:1前言
一:libevent概述: libevent是一个用来编写快速.可移植.非阻塞IO程序的库,它的设计目标是:可移植性.高效.可扩展性.便捷. libevent包含下列组件: evutil:对不同平台下 ...
- 数组工具类 Day07
package com.sxt.arraytest2; /* * 数组的工具类 */ import java.util.Arrays; public class TestArrays { public ...
- PHP笔试题(11道题)详解
题目一 <?php echo -10%3; ?> 答案:-1. 考查:优先级. 因为-的优先级比%求余的优先级低, 也就是-(10%3). 2 题目二: print (int)pow(2, ...
- Oracle函数——COALESCE
COALESCE 含义:COALESCE是一个函数, (expression_1, expression_2, ...,expression_n)依次参考各参数表达式,遇到非null值即停止并返回该值 ...
- Celery后台任务
Celery 在程序运行过程中,经常会遇到一些耗时耗资源的任务,为了避免这些任务阻塞主进程的运行,我们会采用多线程或异步任务去处理.比如在Web中需要对新注册的用户发一封激活邮件来验证账户,而发邮件本 ...
- @noi - 172@ 追捕大象
目录 @description@ @solution@ @accepted code@ @details@ @description@ 在一块平原上有一头大象. 平原被分成 n×m 个格子.初始时大象 ...
- Element-ui学习笔记3--Form表单(一)
Radio单选框 要使用 Radio 组件,只需要设置v-model绑定变量,选中意味着变量的值为相应 Radio label属性的值,label可以是String.Number或Boolean. & ...