php外挂python脚本抓取ajax数据
之前我写过一遍php外挂python脚本处理视频的文章。今天和大家分享下php外挂python实现输入关键字搜索的脚本
首先我们先来分析一波网站:
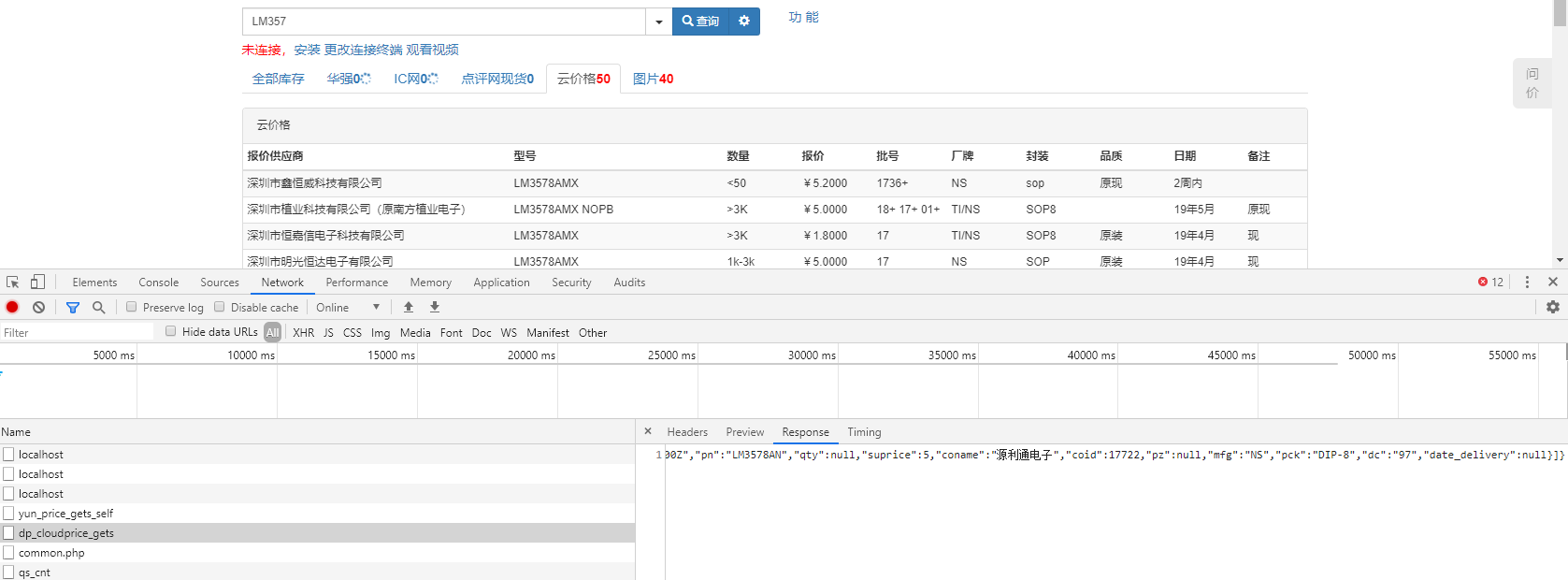
我们可以看到,普通的抓取网站已经不能满足我们的需求了。此网站采用了二次获取数据。我们再来看看头部;
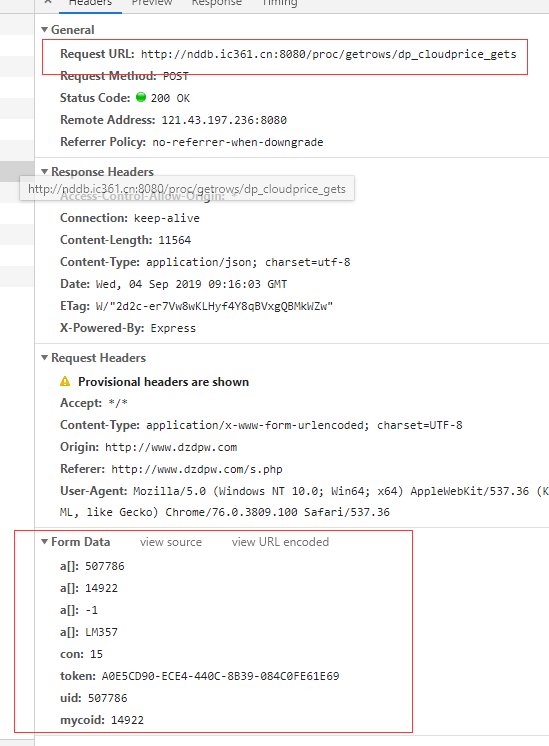
可以看到数据是通过ajax获取的。我们吧拿到的链接放到浏览器直接打开报错了。有些网站是直接拿到链接就能获取数据,但是明显,这个接口采用post接口请求
我们先来请求一波:
代码走起:
# -*- coding: utf-8 -*-
# @Time : 2019/9/4 14:43
# @Author : wujf
# @Email : 1028540310@qq.com
# @File : 爬取ajax数据.py
# @Software: PyCharm
'''
json.loads(json_str) json字符串转换成字典
json.dumps(dict) 字典转换成json字符串
'''
import requests
import json
url = "http://nddb.ic361.cn:8080/proc/getrows/dp_cloudprice_gets"
seach = input("请输入您要搜索的内容:")
list = ['507786','14922','-1']
list.append(seach)
d = {
'token':'A0E5CD90-ECE4-440C-8B39-084C0FE61E69',
'uid':'507786',
'mycoid':'14922',
'con':'15',
'a':list
}

果然能得到数据。
接下来就好办了:
上代码--------
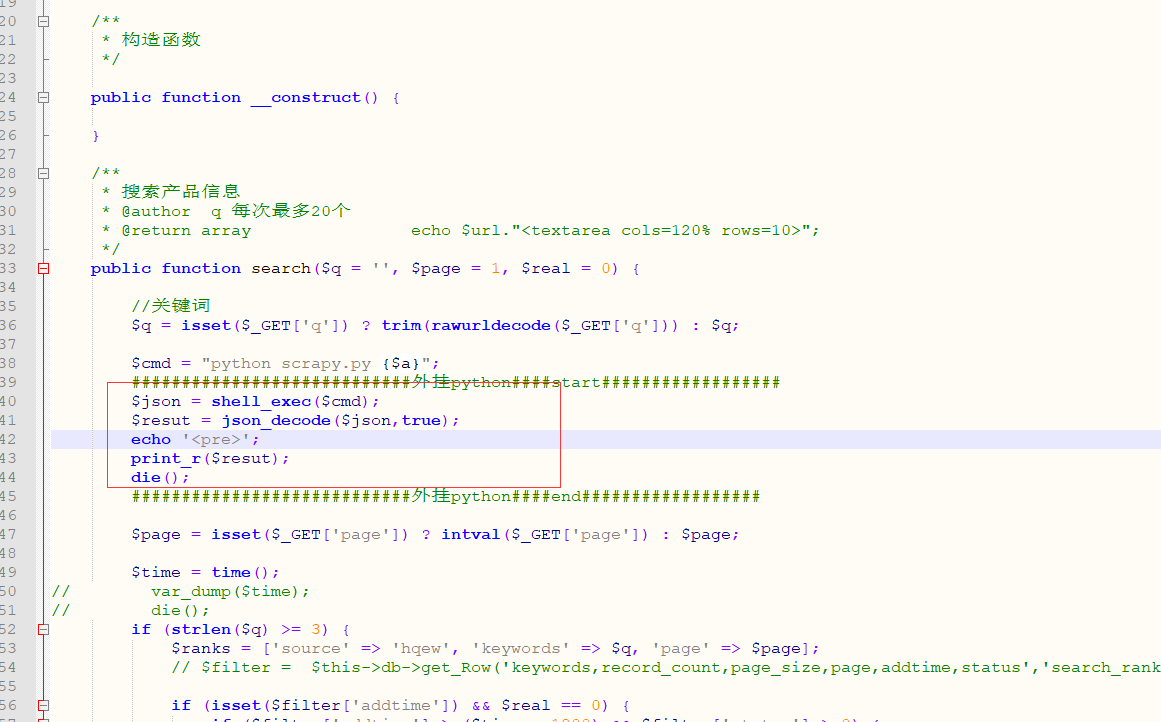
import requests
import json
import sys
url = "http://nddb.ic361.cn:8080/proc/getrows/dp_cloudprice_gets"
seach = sys.argv[1]
#seach1 = sys.argv[2]
#item = seach+'-'+seach1
# with open(r'D:\\phpStudy_server\\PHPTutorial\\WWW\\demo\\log.txt','a') as f:
# try:
# f.write(seach)
# except Exception as e:
# print(e)
# seach = input("请输入您要搜索的内容:")
list = ['507786','14922','-1']
list.append(seach)
d = {
'token':'A0E5CD90-ECE4-440C-8B39-084C0FE61E69',
'uid':'507786',
'mycoid':'14922',
'con':'15',
'a':list
}
r = requests.post(url,data=d)
dic = r.json()
print(json.dumps(dic))
然后我们来看下打印结果:

php外挂python脚本抓取ajax数据的更多相关文章
- Python 逆向抓取 APP 数据
今天继续给大伙分享一下 Python 爬虫的教程,这次主要涉及到的是关于某 APP 的逆向分析并抓取数据,关于 APP 的反爬会麻烦一些,比如 Android 端的代码写完一般会进行打包并混淆加密加固 ...
- python 多线程抓取动态数据
利用多线程动态抓取数据,网上也有不少教程,但发现过于繁杂,就不能精简再精简?! 不多解释,直接上代码,基本上还是很好懂的. #!/usr/bin/env python # coding=utf-8 i ...
- pythonのscrapy抓取网站数据
(1)安装Scrapy环境 步骤请参考:https://blog.csdn.net/c406495762/article/details/60156205 需要注意的是,安装的时候需要根据自己的pyt ...
- Python脚本抓取京东手机的配置信息
以下代码是使用python抓取京东小米8手机的配置信息 首先找到小米8商品的链接:https://item.jd.com/7437788.html 然后找到其配置信息的标签,我们找到其配置信息的标签为 ...
- Python爬虫抓取东方财富网股票数据并实现MySQL数据库存储
Python爬虫可以说是好玩又好用了.现想利用Python爬取网页股票数据保存到本地csv数据文件中,同时想把股票数据保存到MySQL数据库中.需求有了,剩下的就是实现了. 在开始之前,保证已经安装好 ...
- python scrapy 抓取脚本之家文章(scrapy 入门使用简介)
老早之前就听说过python的scrapy.这是一个分布式爬虫的框架,可以让你轻松写出高性能的分布式异步爬虫.使用框架的最大好处当然就是不同重复造轮子了,因为有很多东西框架当中都有了,直接拿过来使用就 ...
- python requests抓取NBA球员数据,pandas进行数据分析,echarts进行可视化 (前言)
python requests抓取NBA球员数据,pandas进行数据分析,echarts进行可视化 (前言) 感觉要总结总结了,希望这次能写个系列文章分享分享心得,和大神们交流交流,提升提升. 因为 ...
- Java语言实现通过Ajax抓取后台数据及图片
1.Java语言实现通过Ajax抓取后台数据及图片信息 1.1数据库设计: create table picture( pic_id number not null, pic_name )not nu ...
- 手把手教你用python打造网易公开课视频下载软件3-对抓取的数据进行处理
上篇讲到抓取的数据保存到rawhtml变量中,然后通过编码最终保存到html变量当中,那么html变量还会有什么问题吗?当然会有了,例如可能html变量中的保存的抓取的页面源代码可能有些标签没有关闭标 ...
随机推荐
- Java TreeMap使用方法
1.使用默认的TreeMap 构造函数,其中key值需要有比较规则. 2.使用默认的TreeMap 构造函数,Key中添加自定义类型,自定义类型必须继承Comparator. 3.使用比较器类来来实现 ...
- 查看php相关信息
1.最常见的就是 创建一个 php页面 ,例如 test.php, 内容如下 <?php phpinfo();?> 直接访问 这个页面,就可以看到php的 信息了 2.其它方法 直 ...
- 编译安装php依赖软件libiconv-1.14报错及其解决办法
make && make install报如下错误: ./stdio.h:1010:1: 错误:‘gets’未声明(不在函数内) _GL_WARN_ON_USE (gets, &quo ...
- 保留yum安装的软件包
文件路径 /etc/yum.conf [root@opvnserver ~]# grep "keepcache" /etc/yum.conf keepcache=0 [root@o ...
- 多校二 1003Maximum Sequence 模拟
Maximum Sequence Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) ...
- 文本段落缩进text-indent:2em
中文文字中的段前习惯空两个文字的空白,这个特殊的样式可以用下面代码来实现: p{text-indent:2em;} <p>1922年的春天,一个想要成名名叫尼克卡拉威(托比?马奎尔Tobe ...
- Android Intent用法总结
Android中提供了Intent机制来协助应用间的交互与通讯,Intent负责对应用中一次操作的动作.动作涉及数据.附加数据进行描述,Android则根据此Intent的描述,负责找到对应的组件,将 ...
- Android中实现照片滑动时左右进出的动画的xml代码
场景 Android中通过ImageSwitcher实现相册滑动查看照片功能(附代码下载): https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/det ...
- centos docker redis 安装
1.下载redis镜像 docker pull redis 2.下载redis.conf文件 https://redis.io/topics/config 这边查找自己服务器redis对应的版本文件 ...
- 疫情之下,使用FRP实现内网穿透,远程连接公司电脑进行办公
当前情况下,经常会有需要到公司电脑进行一些操作,比如连接内网OA,数据库或者提交文档.为了减少外出,将使用frp进行内网穿透的方法进行一个说明. 前提条件 1. 一台拥有公网 IP 的设备(如果没有, ...