flink编译支持CDH6.2.0(hadoop3.0.0)
准备工作
因为在编译时需要下载许多依赖包,在执行编译前最好先配置下代理仓库
<mirrors>
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>*</mirrorOf>
<name>Nexus aliyun</name>
<url>https://maven.aliyun.com/repository/public</url>
</mirror>
</mirrors>
编译flink-shaded
因为flink依赖flink-shaded工程,基本的依赖项都是在这个工程里面定义的,所以要先编译这个工程
下载flink-shaded工程flink-shaded
在写文章时,最新的release版本是8.0,里面用的hadoop及zookeeper对应版本如下
<properties>
<avro.version>1.8.2</avro.version>
<slf4j.version>1.7.15</slf4j.version>
<log4j.version>1.2.17</log4j.version>
<hadoop.version>2.4.1</hadoop.version>
<zookeeper.version>3.4.10</zookeeper.version>
<findbugs.version>1.3.9</findbugs.version>
</properties>
将hadoop和zk改成自己CDH6.2.0对应的版本,修改flink-shaded-hadoop-2工程的pom文件
<properties>
<avro.version>1.8.2</avro.version>
<slf4j.version>1.7.15</slf4j.version>
<log4j.version>1.2.17</log4j.version>
<hadoop.version>3.0.0</hadoop.version>
<zookeeper.version>3.4.5</zookeeper.version>
<findbugs.version>1.3.9</findbugs.version>
</properties>
修改编译后的版本号
- 设置/Users/chengaofeng/git/flink-shaded/tools/releasing/update_branch_version.sh 工程中的OLD_VERSION=8.0和NEW_VERSION=9.0
- 在tools目录下执行 sh releasing/update_branch_version.sh 命令
修改flink-shaded-hadoop-2和flink-shaded-hadoop-2-uber工程中依赖的外部变量名称
<artifactId>flink-shaded-hadoop-2-uber</artifactId>
<name>flink-shaded-hadoop-2-uber</name> <packaging>jar</packaging>
<version>${hadoop.version}-9.0</version>
<artifactId>flink-shaded-hadoop-2</artifactId>
<name>flink-shaded-hadoop-2</name> <packaging>jar</packaging>
<version>${hadoop.version}-9.0</version>
进入flink-shaded目录执行编译
mvn clean install -DskipTests -Drat.skip=true -Pvendor-repos -Dhadoop.version.cdh=3.0.0
效果图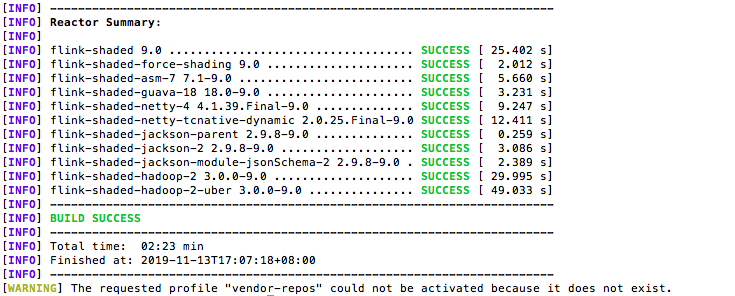
编译flink
下载源码flink
写文章时最新的release版本是1.9,所以下载1.9版本的代码
修改对应的hadoop和flink.shaded.version值为我们需要的值
<hadoop.version>3.0.0</hadoop.version>
...
<flink.shaded.version.old>7.0</flink.shaded.version.old>
<flink.shaded.version>9.0</flink.shaded.version>
...
<hivemetastore.hadoop.version>3.0.0</hivemetastore.hadoop.version>因为只想更新hadoop的版本,所以依赖的其他flink-shaded版本不做变更,以下jackson举例说明,还是用旧的版本(用最新的编译没有编译过)
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-shaded-jackson</artifactId>
<version>${jackson.version}-${flink.shaded.version.old}</version>
</dependency> <dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-shaded-jackson-module-jsonSchema</artifactId>
<version>${jackson.version}-${flink.shaded.version.old}</version>
</dependency>
修改flink-connectors/flink-hbase中依赖的hbase版本号
<properties>
<hbase.version>2.1.2</hbase.version>
</properties>
之后需要修改这个工程中的AbstractTableInputFormat.java,TableInputFormat.java以及junit中的编译错误
修改版本号
修改tools/change-version.sh中新旧版本号OLD="1.9-SNAPSHOT"
NEW="1.9-H3"执行脚本change-version.sh
注释掉不需要编译的工程,因为这个编译太耗时间,可以把测试相关的包去掉
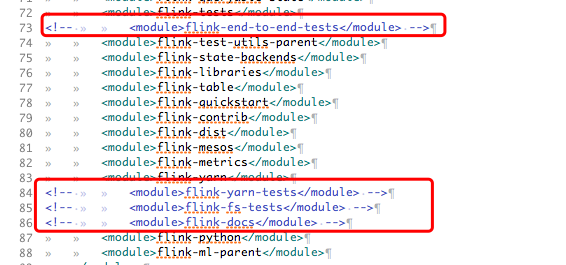
执行编译
mvn clean install -DskipTests -Pvendor-repos -Drat.skip=true -Pinclude-hadoop
编译结果
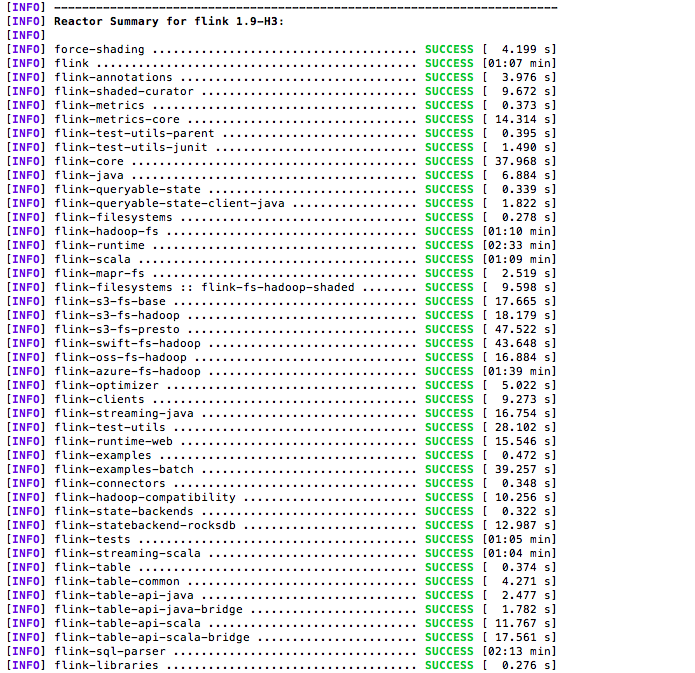
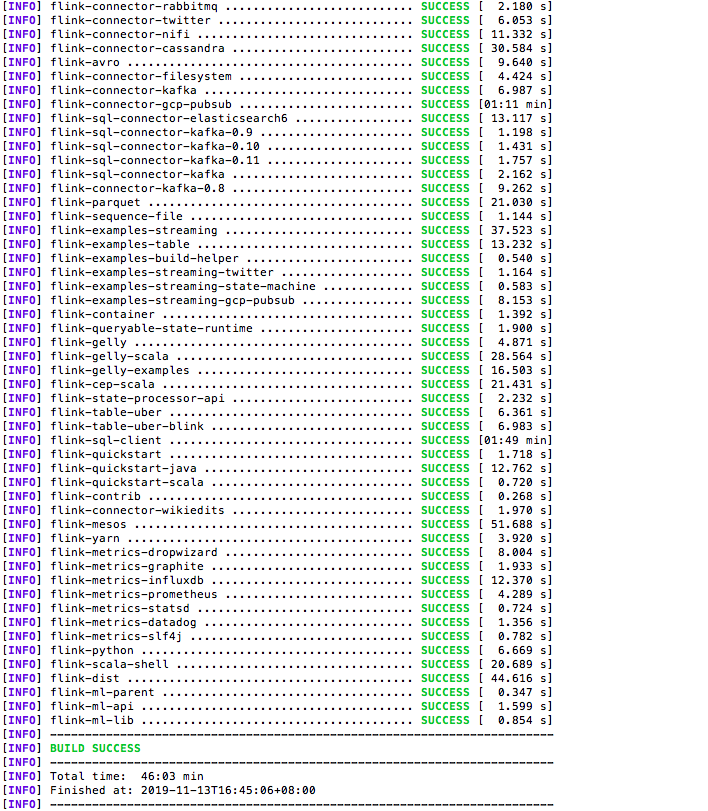
在工程中使用新编译出的版本
<properties>
<flink.version>1.9-H3</flink.version>
</properties>对应修改后的代码地址github 版本:release-1.9
flink编译支持CDH6.2.0(hadoop3.0.0)的更多相关文章
- Hadoop3.2.0使用详解
1.概述 Hadoop3已经发布很久了,迭代集成的一些新特性也是很有用的.截止本篇博客书写为止,Hadoop发布了3.2.0.接下来,笔者就为大家分享一下在使用Hadoop3中遇到到一些问题,以及解决 ...
- CentOS7搭建Hadoop-3.3.0集群手记
前提 这篇文章是基于Linux系统CentOS7搭建Hadoop-3.3.0分布式集群的详细手记. 基本概念 Hadoop中的HDFS和YARN都是主从架构,主从架构会有一主多从和多主多从两种架构,这 ...
- Gobblin编译支持CDH5.4.0
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 Gobblin的前身是linkedin的Camus,好多人也用过,准备用Gobblin的方式来抽 ...
- nginx编译支持HTTP2.0
nginx编译支持HTTP2.0 nginx编译支持HTTP2.0 wget https://www.openssl.org/source/openssl-1.1.0i.tar.gz #openssl ...
- hadoop搭建伪分布式集群(centos7+hadoop-3.1.0/2.7.7)
目录: Hadoop三种安装模式 搭建伪分布式集群准备条件 第一部分 安装前部署 1.查看虚拟机版本2.查看IP地址3.修改主机名为hadoop4.修改 /etc/hosts5.关闭防火墙6.关闭SE ...
- [环境配置]Ubuntu 16.04 源码编译安装OpenCV-3.2.0+OpenCV_contrib-3.2.0及产生的问题
1.OpenCV-3.2.0+OpenCV_contrib-3.2.0编译安装过程 1)下载官方要求的依赖包 GCC 4.4.x or later CMake 2.6 or higher Git GT ...
- PHP7 学习笔记(一)Ubuntu 16.04 编译安装Nginx-1.10.3、 PHP7.0.9、Redis3.0 扩展、Phalcon3.1 扩展、Swoole1.9.8 扩展、ssh2扩展(全程编译安装)
==================== PHP 7.0 编译安装================== wget http://cn2.php.net/get/php-7.0.9.tar.bz2/fr ...
- hadoop3.1.0 window win7 基础环境搭建
https://blog.csdn.net/wsh596823919/article/details/80774805 hadoop3.1.0 window win7 基础环境搭建 前言:在windo ...
- 【hadoop】hadoop3.2.0应用环境搭建与使用指南
下面列出我搭建hadoop应用环境的文章整理在一起,不定期更新,供大家参考,互相学习!!! 杂谈篇: [英语学习]Re-pick up English for learning big data (n ...
随机推荐
- 2019-2-28-C#-16-进制字符串转-int-
title author date CreateTime categories C# 16 进制字符串转 int lindexi 2019-02-28 11:51:36 +0800 2018-04-2 ...
- P1070 东风谷早苗
题目描述 在幻想乡,东风谷早苗是以高达控闻名的高中生宅巫女.某一天,早苗终于入手了最新款的钢达姆模型.作为最新的钢达姆,当然有了与以往不同的功能了,那就是它能够自动行走,厉害吧(好吧,我自重).早苗的 ...
- 解决浏览器中点击input输入框时,placeholder的值不消失的方法
版权声明:本文为博主原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/lianwenxiu/article/det ...
- H3CSTP、RSTP的问题
- asp dotnet core 支持客户端上传文件
本文告诉大家如何在 asp dotnet core 支持客户端上传文件 新建一个 asp dotnet core 程序,创建一个新的类,用于给客户端上传文件的信息 public class Kanaj ...
- 2019-9-2-win10-uwp-获得焦点改变
title author date CreateTime categories win10 uwp 获得焦点改变 lindexi 2019-09-02 12:57:38 +0800 2018-2-13 ...
- codeforces 220B . Little Elephant and Array 莫队+离散化
传送门:https://codeforces.com/problemset/problem/220/B 题意: 给你n个数,m次询问,每次询问问你在区间l,r内有多少个数满足其值为其出现的次数 题解: ...
- springmvc 参数校验/aop失效/@PathVariable 参数为空
添加依赖 <!-- 参数校验 --> <dependency> <groupId>org.hibernate.validator</groupId> & ...
- jdk8下面的ArrayList的扩容
一. ArrayList class ArrayList<E> extends AbstractList<E> implements List<E>, Random ...
- b方式操作文件
f=open('test11.py','rb',encoding='utf-8') #b的方式不能指定编码 f=open('test11.py','rb') #b的方式不能指定编码 data=f.re ...