【elasticsearch】数据早8小时Or晚8小时,你知道为什么吗,附解决方案
前言
- 这篇文章,不会解释什么是本初子午线,只想以做实验的方式来理解数据差8小时的问题。下面就先说结论,再来谈原理。
解决方案
- 想必大家都很清楚:中国标准时间= UTC + 8小时。
- 那么所有和时区有关的地方,都有可能成为“凶手”。
如果是java写入es怎么解决时区问题?
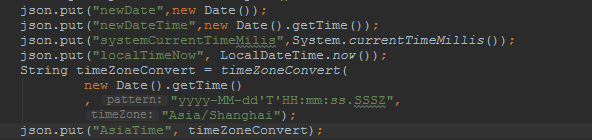
- 如果你使用java程序来写入es,我推荐你写入带T的时间字符串。提供程序如下:
/**
* String timeZoneConvert = timeZoneConvert(
* new Date().getTime()
* , "yyyy-MM-dd'T'HH:mm:ss.SSSZ",
* "Asia/Shanghai");
*
* @param date 毫秒
* @param pattern format时间格式
* @param timeZone 时区
* @return 如:2019-12-30T16:32:07.616+0800
*/
public static String timeZoneConvert(Long date,String pattern,String timeZone){
SimpleDateFormat simpleDateFormat=new SimpleDateFormat(pattern);
simpleDateFormat.setTimeZone(TimeZone.getTimeZone(timeZone));
return simpleDateFormat.format(date);
}
- 为什么?因为java有些api是带时区的。如new Date().getTime()默认是东八区,System.currentTimeMillis() 依赖于当前时区来计算毫秒值。
- 虽然上述例子依赖了这个api,但是这里只是想说明java程序所处的环境的时区同样有影响,特别是这个程序很可能是容器化的,那么可能又和系统镜像的时区有关了。
如果是logstash写入es怎么解决时区问题?
- 建议input的时间源数据就是带上时区的字符串,否则就要进行转换。
mutate{
gsub => [
"time", "[+]", "T"
]
}
mutate{
replace => ["time","%{time}+08:00"]
}
或是:
date {
match => ["timestamp", "yyyy-MM-dd HH:mm:ss"]
target => "my_timestamp"
timezone => "+08:00"
}
如果是语句聚合es数据怎么解决时区问题?
- 指定time_zone配置
"aggs": {
"by_day": {
"date_histogram": {
"field": "date",
"interval": "day",
"time_zone": "Asia/Shanghai"
}
}
}
kibana显示怎么解决时区问题?
- Management>>Advanced Settings设置时区。

原理&试验
Es中和时间相关的数据类型
- 一般在写入es的时候,会以json的方式写入,由于json中没有日期数据类型,所以日期如何存储显示,是由es决定的,也就是说es会进行隐式的类型转换。
- es中的日期可以是:
- 格式化日期的字符串,例如"2019-12-30"或"2019/12/30 12:10:30"。
- 毫秒值。
- 秒值。
试验
- 这里以不同的时间api准备了一些数据写入es,让我们来看看会发生什么。
- 数据打印出来如下:
{
"AsiaTime":"2019-12-30T16:32:07.616+0800",
"newDateTime":1577694727581,
"localTimeNow":"2019-12-30T16:32:07.615",
"systemCurrentTimeMilis":1577694727581,
"newDate":1577694727581
}
默认不设置索引模板的情况,写入es后,我们发现带 时区‘T’的数据类型为date。
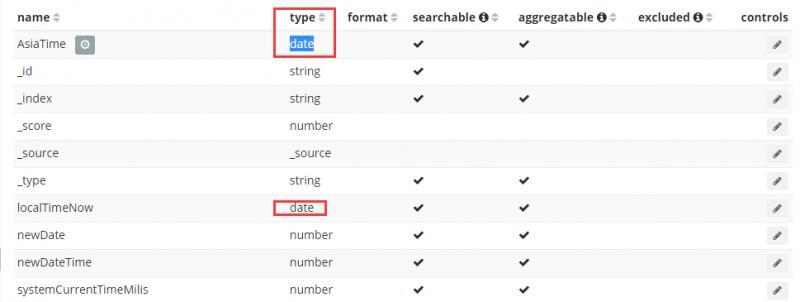
接下来,我们将轮流设置这两个字段为kibana的时间搜索字段,看看会发生什么。
两个实验对时区的思考
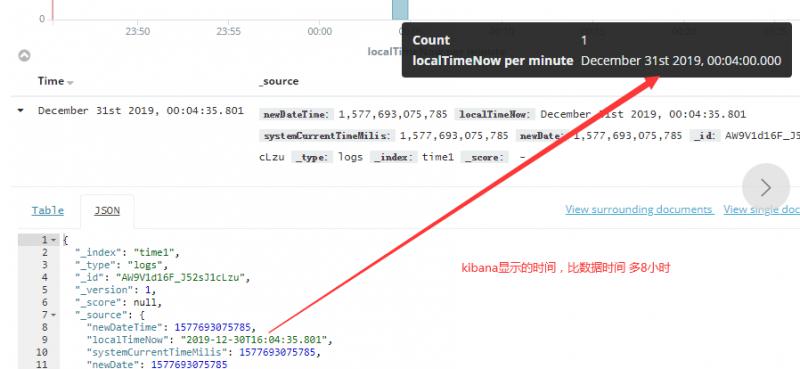
实验一:以localTimeNow做时间搜索字段,显示比数据时间晚了8小时。
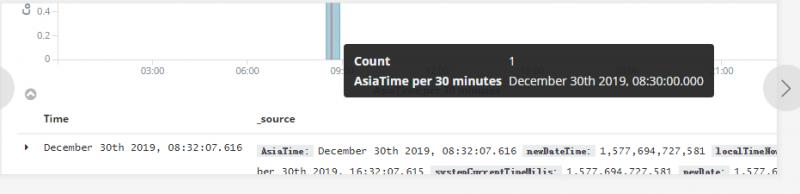
实验二:以AsiaTime做时间搜索字段,显示比数据时间早了8小时。
如何解释?当然是由于时区影响。记住这几个点,就很好理解了:
- es内部,时间会转换成UTC格式,实际按照数值型存储。可以理解为毫秒数。
- kibana会通过获取时区配置显示时间到界面。
首先来说实验一,为什么kibana上显示的时比数据时间多8个小时呢?明明是30号的数据,愣是跑到31号去了?
这条数据 "localTimeNow":"2019-12-30T16:32:07.615"。带时区T,默认是UTC时区,
而kibana获取的时区配置是Asia/Shanghai,为东8区,相当于在原来的时间上加上8个小时显示,所以跑到31号去了。
用大腿想一下,你肯定知道,这种情况下如果把kibana时区设置为UTC,当然数据就显示正常啦。再来说实验二, "AsiaTime":"2019-12-30T16:32:07.616+0800,由于上面设置了当前kibana时区为UTC,数据带东八区的时区,所以晚了8小时。同理将kibana时区改为东八区后显示正常。
总结
- 时区问题,万变不离其宗,搞清楚原理后,任意数据怎么变化,我们都能够有方法应对,希望这篇文章对你有所帮助。
欢迎来公众号【侠梦的开发笔记】 一起交流进步
【elasticsearch】数据早8小时Or晚8小时,你知道为什么吗,附解决方案的更多相关文章
- elasticsearch数据组织结构
elasticsearch数据组织结构 1. mapping 1.1. 简介 mapping:意为映射关系,特别是指组织结构.在此语境中可理解为数据结构,包括表结构,表约束,数据类型等 ...
- myeclipse中控制台日志比实际晚8小时解决方法及java日志处理
今天终于忍不住要解决myeclipse控制台中日志显示比实际晚8小时的问题,开始以为myeclipse编辑器时间问题,后来想想不对,myeclipse控制台打印的是tomcat的日志,随后以为是log ...
- win7和ubuntu双系统,win7时间晚8小时解决办法。
装了Win7和Ubuntu双系统后发现,使用Ubuntu后再登陆win7时系统显示时间不准确,比实际时间晚了8小时. 搜索后发现原来Linux和Windows的系统时间管理是不同的.Linux是以主板 ...
- 【原创】大叔经验分享(26)hive通过外部表读写elasticsearch数据
hive通过外部表读写elasticsearch数据,和读写hbase数据差不多,差别是需要下载elasticsearch-hadoop-hive-6.6.2.jar,然后使用其中的EsStorage ...
- Oracle和Elasticsearch数据同步
Python编写Oracle和Elasticsearch数据同步脚本 标签: elasticsearchoraclecx_Oraclepython数据同步 Python知识库 一.版本 Pyth ...
- elasticsearch数据备份还原
elasticsearch数据备份还原 1.在浏览器中运行http://XXX.XXX.XXX.XXX:9200/_flush,确保索引数据能保存到硬盘中. 2.原数据的备份.主要是elasticse ...
- 18-10-15 服务器删除数据的方法【Elasticsearch 数据删除 (delete_by_query 插件安装使用)】方法二没有成功
rpa 都是5.xx ueba 分为2.0 或者5.0 上海吴工删除数据的方法 在许多项目中,用户提供的数据存储盘大小有限,在运行一段时间后,大小不够就需要删除历史的 Elasticsearch 数 ...
- [转] [Elasticsearch] 数据建模 - 处理关联关系(1)
[Elasticsearch] 数据建模 - 处理关联关系(1) 标签: 建模elasticsearch搜索搜索引擎 2015-08-16 23:55 6958人阅读 评论(0) 收藏 举报 分类: ...
- 服务追踪数据使用 RabbitMQ 进行采集 + 数据存储使用 Elasticsearch + 数据展示使用 Kibana
服务追踪数据使用 RabbitMQ 进行采集 + 数据存储使用 Elasticsearch + 数据展示使用 Kibana https://www.cnblogs.com/xishuai/p/elk- ...
随机推荐
- HZOJ Silhouette
转化一下题意:给出矩阵每行每列的最大值,求满足条件的矩阵个数. 先将A,B按从大到小排序,显然没有什么影响.如果A的最大值不等于B的最大值那么无解否则一定有解. 考虑从大到小枚举A,B中出现的数s,那 ...
- nodeJs学习-03 GET数据请求,js拆解/querystring/url
原生JS解析参数: const http = require('http'); http.createServer(function(req,res){ var GET = {}; //接收数据容器 ...
- 【datagrid】动态加载列 2016-01-03 16:32 2013人阅读 评论(19) 收藏
之前我们的项目在前台显示只需要把数据从数据库读出来进行显示就可以,datagrid的表头字段都是写死的,把数据往表里一扔,就基本没什么事儿了,结果客户前几天要求,其中一个字段不能是死的,应该是有多少项 ...
- Android系列之Android 命令行手动编译打包详解
Android 命令行手动编译打包过程图 [详细步骤]: 1使用aapt生成R.java类文件: 例: E:\androidDev\android-sdk-windows2.2\tools> ...
- hdu 4629 Burning (扫描线)
Problem - 4629 以前写过PSLG模拟的版本,今天写了一下扫描线做这题. 其实这题可以用set存线段来做,类似于判断直线交的做法.不过实现起来有点麻烦,于是我就直接暴力求交点了. 代码如下 ...
- windows环境下安装nodeJS和express,一直提示command not found-配置环境变量
1.安装NodeJS后,使用npm指令安装express框架,使用 npm install -g express npm install -g express-generator 安装了大半天的时间, ...
- H3C 典型数据链路层标准
- 反思K-S指标(KPMG大数据挖掘)
评估信用评级模型,反思K-S指标 2015-12-05 KPMG大数据团队 KPMG大数据挖掘 “信用评级”的概念听起来可以十分直截了当.比如一天早上你接到电话,有个熟人跟你借钱,而你将在半睡半醒间迅 ...
- The 'decorators' plugin requires a 'decoratorsBeforeExport' option, ...(npm start报错)
问题描述: 在npm start启动react项目的时候,出现了如下报错: The 'decorators' plugin requires a 'decoratorsBeforeExport' op ...
- java线程与进程的比较
线程具有许多传统进程所具有的特征,故又称为轻型进程(Light—Weight Process)或进程元:而把传统的进程称为重型进程(Heavy—Weight Process),它相当于只有一个线程的任 ...