【elasticsearch】数据早8小时Or晚8小时,你知道为什么吗,附解决方案
前言
- 这篇文章,不会解释什么是本初子午线,只想以做实验的方式来理解数据差8小时的问题。下面就先说结论,再来谈原理。
解决方案
- 想必大家都很清楚:中国标准时间= UTC + 8小时。
- 那么所有和时区有关的地方,都有可能成为“凶手”。
如果是java写入es怎么解决时区问题?
- 如果你使用java程序来写入es,我推荐你写入带T的时间字符串。提供程序如下:
/**
* String timeZoneConvert = timeZoneConvert(
* new Date().getTime()
* , "yyyy-MM-dd'T'HH:mm:ss.SSSZ",
* "Asia/Shanghai");
*
* @param date 毫秒
* @param pattern format时间格式
* @param timeZone 时区
* @return 如:2019-12-30T16:32:07.616+0800
*/
public static String timeZoneConvert(Long date,String pattern,String timeZone){
SimpleDateFormat simpleDateFormat=new SimpleDateFormat(pattern);
simpleDateFormat.setTimeZone(TimeZone.getTimeZone(timeZone));
return simpleDateFormat.format(date);
}
- 为什么?因为java有些api是带时区的。如new Date().getTime()默认是东八区,System.currentTimeMillis() 依赖于当前时区来计算毫秒值。
- 虽然上述例子依赖了这个api,但是这里只是想说明java程序所处的环境的时区同样有影响,特别是这个程序很可能是容器化的,那么可能又和系统镜像的时区有关了。
如果是logstash写入es怎么解决时区问题?
- 建议input的时间源数据就是带上时区的字符串,否则就要进行转换。
mutate{
gsub => [
"time", "[+]", "T"
]
}
mutate{
replace => ["time","%{time}+08:00"]
}
或是:
date {
match => ["timestamp", "yyyy-MM-dd HH:mm:ss"]
target => "my_timestamp"
timezone => "+08:00"
}
如果是语句聚合es数据怎么解决时区问题?
- 指定time_zone配置
"aggs": {
"by_day": {
"date_histogram": {
"field": "date",
"interval": "day",
"time_zone": "Asia/Shanghai"
}
}
}
kibana显示怎么解决时区问题?
- Management>>Advanced Settings设置时区。

原理&试验
Es中和时间相关的数据类型
- 一般在写入es的时候,会以json的方式写入,由于json中没有日期数据类型,所以日期如何存储显示,是由es决定的,也就是说es会进行隐式的类型转换。
- es中的日期可以是:
- 格式化日期的字符串,例如"2019-12-30"或"2019/12/30 12:10:30"。
- 毫秒值。
- 秒值。
试验
- 这里以不同的时间api准备了一些数据写入es,让我们来看看会发生什么。
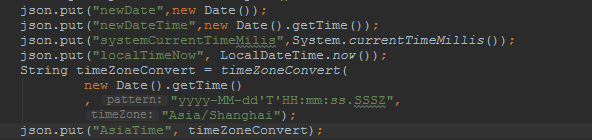
- 数据打印出来如下:
{
"AsiaTime":"2019-12-30T16:32:07.616+0800",
"newDateTime":1577694727581,
"localTimeNow":"2019-12-30T16:32:07.615",
"systemCurrentTimeMilis":1577694727581,
"newDate":1577694727581
}
默认不设置索引模板的情况,写入es后,我们发现带 时区‘T’的数据类型为date。
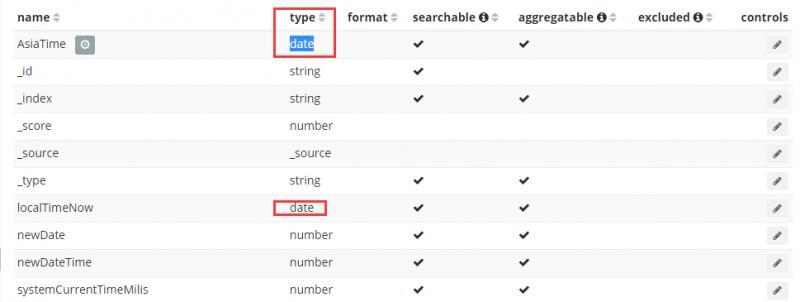
接下来,我们将轮流设置这两个字段为kibana的时间搜索字段,看看会发生什么。
两个实验对时区的思考
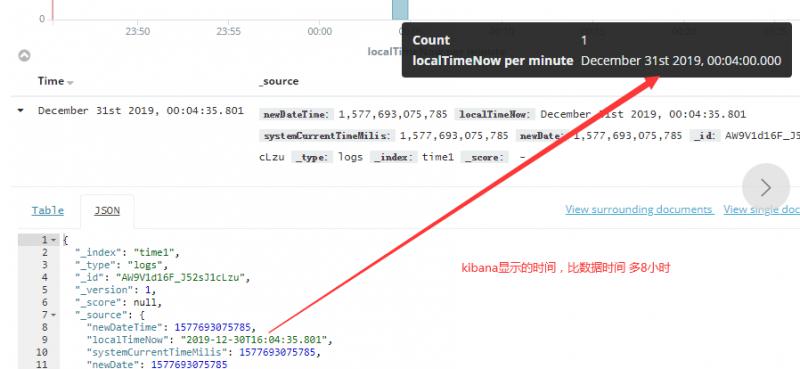
实验一:以localTimeNow做时间搜索字段,显示比数据时间晚了8小时。
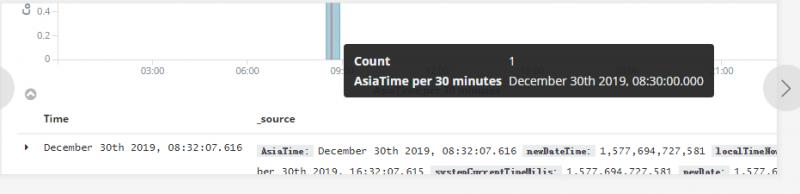
实验二:以AsiaTime做时间搜索字段,显示比数据时间早了8小时。
如何解释?当然是由于时区影响。记住这几个点,就很好理解了:
- es内部,时间会转换成UTC格式,实际按照数值型存储。可以理解为毫秒数。
- kibana会通过获取时区配置显示时间到界面。
首先来说实验一,为什么kibana上显示的时比数据时间多8个小时呢?明明是30号的数据,愣是跑到31号去了?
这条数据 "localTimeNow":"2019-12-30T16:32:07.615"。带时区T,默认是UTC时区,
而kibana获取的时区配置是Asia/Shanghai,为东8区,相当于在原来的时间上加上8个小时显示,所以跑到31号去了。
用大腿想一下,你肯定知道,这种情况下如果把kibana时区设置为UTC,当然数据就显示正常啦。再来说实验二, "AsiaTime":"2019-12-30T16:32:07.616+0800,由于上面设置了当前kibana时区为UTC,数据带东八区的时区,所以晚了8小时。同理将kibana时区改为东八区后显示正常。
总结
- 时区问题,万变不离其宗,搞清楚原理后,任意数据怎么变化,我们都能够有方法应对,希望这篇文章对你有所帮助。
欢迎来公众号【侠梦的开发笔记】 一起交流进步
【elasticsearch】数据早8小时Or晚8小时,你知道为什么吗,附解决方案的更多相关文章
- elasticsearch数据组织结构
elasticsearch数据组织结构 1. mapping 1.1. 简介 mapping:意为映射关系,特别是指组织结构.在此语境中可理解为数据结构,包括表结构,表约束,数据类型等 ...
- myeclipse中控制台日志比实际晚8小时解决方法及java日志处理
今天终于忍不住要解决myeclipse控制台中日志显示比实际晚8小时的问题,开始以为myeclipse编辑器时间问题,后来想想不对,myeclipse控制台打印的是tomcat的日志,随后以为是log ...
- win7和ubuntu双系统,win7时间晚8小时解决办法。
装了Win7和Ubuntu双系统后发现,使用Ubuntu后再登陆win7时系统显示时间不准确,比实际时间晚了8小时. 搜索后发现原来Linux和Windows的系统时间管理是不同的.Linux是以主板 ...
- 【原创】大叔经验分享(26)hive通过外部表读写elasticsearch数据
hive通过外部表读写elasticsearch数据,和读写hbase数据差不多,差别是需要下载elasticsearch-hadoop-hive-6.6.2.jar,然后使用其中的EsStorage ...
- Oracle和Elasticsearch数据同步
Python编写Oracle和Elasticsearch数据同步脚本 标签: elasticsearchoraclecx_Oraclepython数据同步 Python知识库 一.版本 Pyth ...
- elasticsearch数据备份还原
elasticsearch数据备份还原 1.在浏览器中运行http://XXX.XXX.XXX.XXX:9200/_flush,确保索引数据能保存到硬盘中. 2.原数据的备份.主要是elasticse ...
- 18-10-15 服务器删除数据的方法【Elasticsearch 数据删除 (delete_by_query 插件安装使用)】方法二没有成功
rpa 都是5.xx ueba 分为2.0 或者5.0 上海吴工删除数据的方法 在许多项目中,用户提供的数据存储盘大小有限,在运行一段时间后,大小不够就需要删除历史的 Elasticsearch 数 ...
- [转] [Elasticsearch] 数据建模 - 处理关联关系(1)
[Elasticsearch] 数据建模 - 处理关联关系(1) 标签: 建模elasticsearch搜索搜索引擎 2015-08-16 23:55 6958人阅读 评论(0) 收藏 举报 分类: ...
- 服务追踪数据使用 RabbitMQ 进行采集 + 数据存储使用 Elasticsearch + 数据展示使用 Kibana
服务追踪数据使用 RabbitMQ 进行采集 + 数据存储使用 Elasticsearch + 数据展示使用 Kibana https://www.cnblogs.com/xishuai/p/elk- ...
随机推荐
- 实现ios后台缩略图模糊的一种方法
http://blog.sina.com.cn/s/blog_64cfe8f00102ux5t.html 今天玩手机(Iphone)发现应用切换支付宝会变模糊,不禁感叹,细节处理的太到位了. 怎么 ...
- 《C语言深度解剖》学习笔记之函数
第6章 函数 1.编码风格 [规则6-1]每一个函数都必须有注释 [规则6-2]每个函数定义之后以及每个文件结束之后都要加若干个空行 [规则6-3]在一个函数体内,变量定义与函数语句之间要加空行 [规 ...
- iOS学习--详解UIView的 contentStretch属性
通过实例和图片理解UIView的contentStretch属性 方法 通过一个图片建立一个简单的UIImageView 设置它的contentStretch属性 修改它的frame属性 观察 测试用 ...
- Linux 运算符
布尔运算符 下表列出了常用的布尔运算符,假定变量a为10 变量b为20: 运算符 说明 举例 ! 非运算 , 表达式为true 则返回false 否则返回true [!false] 返回true. ...
- 如何使用jmeter调用soap协议
- poj 2689 Prime Distance (素数二次筛法)
2689 -- Prime Distance 没怎么研究过数论,还是今天才知道有素数二次筛法这样的东西. 题意是,要求求出给定区间内相邻两个素数的最大和最小差. 二次筛法的意思其实就是先将1~sqrt ...
- hdu 1286 找新朋友 (容斥原理 || 欧拉函数)
Problem - 1286 用容斥原理做的代码: #include <cstdio> #include <iostream> #include <algorithm&g ...
- 【CSS3 + 原生JS】上升的方块动态背景
GIF图有点大,网速慢的或将稍等片刻或可浏览本人的制作的demo. Demo : 点击查看 HTML: <!DOCTYPE html> <html lang="en&quo ...
- html手机端全屏显示和溢出问题
<meta name="viewport" content="width=1200, initial-scale=0.3"> initial-sca ...
- Python--day61--Django ORM单表操作之展示用户列表
user_list.html views.py 项目的urls.py文件