Lifetime-Based Memory Management for Distributed Data Processing Systems
Lifetime-Based Memory Management for Distributed Data Processing Systems
(Deca:Decompose and Analyze)
一、分布式数据处理系统像Spark、FLink中的优缺点:
1、优点:
in-memory中可以通过缓存中间数据以及在shuffle buffer中组合和聚合数据最小化重复 计算和I/O花销来提升多阶段和迭代计算性能。
2、缺点:
(1)会在堆中产生大量的长期生存的对象,因而产生很多GC,尤其是当处理大数据集 时,会对系统的伸缩性产生很大影响。
(2)这些框架都是用一些高级语言实现并且在托管运行时平台上(例如JVM等)运行, 这些都是自动内存管理,会带来重大的CPU和内存开销。
二、解决方案:提出了Lifetime-Based Memory Management:Deca
1、简介:
(1)它是在Spark之上实现,是Spark的自动优化器,能够高效的回收内存空间。
(2)它能够基于对象的lifetime而不是传统的GC跟踪来进行分配和释放内存。
(3)它能够自动的分析在Spark中不同容器中(UDF变量、cache block和shuffle buffer)的数据对象的lifetime,然后透明的将大量具有类似lifetime的对象 进行分解和存储到一些数量的byte array里。通过这种方 式,大量的对象本质上 可以绕开GC的连续跟踪和通过销毁byte array来进行空间的释放。
(4)它能够通过转换用户程序来使得新的内存布局对于用户是透明的。
2、举例说明:(以下是Spark中的逻辑回归代码)

在采用Deca后,内存格局的变化如下:

三、如何进行内存管理
1、在Deca中,对象被存储在三种不同的容器中:UDF变量、cache block和shuff buffer中。在每种容器中,Deca都分配了一定数量固定长度的字节数组,将UDT对象 与相应的容器进行map,UDT对象在被消除了没有必要的对象头 和引用后存储在字节 数组中,这种紧凑的内存布局不仅可以最小化内存消耗,而且可以显著减少GC开销, 因为GC进行跟踪的是byte array而不是大量的UDT对象。
2、因为像Spark这种数据框架容器的lifetime是可以预先明确知道的(比如缓存 RDD,当显示的调用cache()和unpersist()后,容器lifetime将会 end)Deca将 具有相同或者是相似对象放在相同的容器中,然后将对象与容器相对应,当容器的 lifetime 结束时,我们将简单的释放掉所有在容器中 的byte array的引用,然后GC 将回收所有被大量对象所占用的内存空间。
3、byte array的size如何确定?
(1)规定了data-size:对象的静态引用图中所有原始类型的数据大小的总和。
(2)对于一些原始类型的数据,data-size是固定的,但是对于一些非原始类型的 数据,需要通过代码分析知道对象的data-type和data-size的变化模式。
(3)进行UDT CLASSIFICATION ANALYSIS:只有满足安全性的UDT对象,才会被分解。
a、Deca会创建data dependent graph,如下:

b、满足条件的data-type:
SFST(Static Fixed Size Type):所有的UDT对象实例的data-size是相同的, 并且在运行期间不会改变。
RFST(Runtime Fixed Size Type)所有的UDT对象的实例在运行期间 data-size不会发生改变。
c、其他类型:
RDT(Recursively-Defined Type)指的是在data dependent graph中有cycle 的。
VST(Variable-Sized Type)除了以上三种之外所有的其他数据类型属于这种。
d、级别:
SFST < RFST < VST
e、分析算法:
Local Classification Analysis:

Global Classification Analysis:

1)Init-only field:对于非原始类型T来说,如果每个对象的域在程序在执 行的时候仅仅被执行一次。
2)Fixed-length array types:对于数组类型的T来说,如果在一个良好的 范围内所有分配给f的A的对象具有相同长度的值如:

Phased Refinement:
在Spark中可以将一个task分为多个的阶段,那么每个阶段都有可 能对 data-size进行改变,所以需要每阶段的细化分析。
4、内存管理:
(1)Spark中不同容器的lifetime:
a、UDF variables.:
包括函数对象和局部变量。因为在task结束后,函数对象也会结束,而当方 法调用结束后,局部变量将结束。所以所有的数据对象将和局部变量一样,都 是短期存在的临时对象。
b、cache block:
cache block的lifetime是被显示调用cache()和unpersist()决定的,当 调用unpersist时,所有的缓存块将被迅速回收。
c、Shuff buffer:
一个shuffle buffer被两个阶段所访问:创建buffer和读取里边的数据。 当第二个阶段所完成后,这个buffer的lifetime就结束了。
(2)Deca将数据对象和容器相对应,数据确认在数据被创建的阶段或者是前一阶段(如 果是读取的上一阶段的数据)。
(3)Deca对容器提出以下的规则:
a、cache block和Shuffle buffer具有比UDF variables更高的级别。
b、当同时被高级的容器所拥有时,将会把第一次执行时创建的容器作为拥有者。
(4)数据可以被多个容器进行赋值,Deca会将拥有的容器分为primary container 和secondary containers(除了primary container容器之外所有的容器)。
(5)数据的组织和管理:
a、Deca用统一具有固定长度的byte array作为逻辑memory page来存储被分解 的数据对象。逻辑page可以被分成字节端,并且page的size选择要恰当来 确保GC的开销是微乎其微的。(太大的话会造成大量的无用空间,太小的话 会造成空间内存不足以存放分解对象)
b、Deca用page info结构来维护page的原数据:Page info:
Pages:一个page array来存储所有这个page group中分配的page引用。 endOffset:一个整数来存储这个page中没有用的空间开 始位置。
curPage and curOffset:两个整数来表示进程访问扫描的page 和这个page group中的offset)。
(6)primary container中数据对象的存储依赖于容器的类别。
a、UDF variables:
对于UDF变量来说,Deca不会分解这些对象,因为这些对象被短lifetime的局部变量所引用,他们属于年轻代,而年轻代仅仅引发微型的GC,不会造成大的GC开销。被函数对象引用的会到老年代、但是这些对象总数相对于输入的大数据集来说,相对很小。
b、Cache blocks:
1)Deca总是分解SFST和RFST对象和存储他们在page group的缓存块上, 同时保留完整的VST对象。如下图表示包含分解对象的缓存RDD 在缓存快上 的结构:
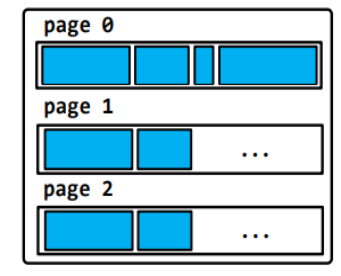
2)一个task可以读取分解的缓存快数据,有可能会改变这些对象的data-szie, 如果这样的话,Deca将重新构建这些对象并释放掉之前所有的page group,但是Deca不会重新分解这个对象。
c、Shuffle buffer :
和缓存块类似,Deca将SFST和RSFT的对象分解到shuffle Buffer的page group 中,但是不像缓存的RDD(数据访问是顺序的),数据在shuffle buffer中将 会被随机访问来执行基于hash和sorting的操作。如下图所示,我们用array 来存储指向一个page group中key和value的指针。(当在基于hash的key和 value都是原始类型或者是SFST时,指针数组可以被省略,因为可以推断出具 体的数据offset)。当在进行基于hash shuffle buffer的groupbykey计算时,这 个生成对象会反复更改,频繁的GC将会不可避免,但是如果对于值是SFST 时,Deca将重用之前的page group,分解新的对象到里边来替代旧的对象, 这样将会减少不必要对于生成临时Value对象的频繁GC。
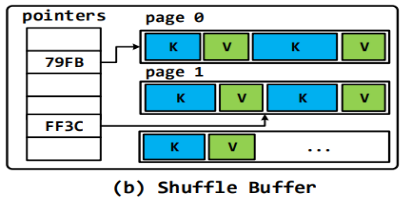
(7)第二容器中的数据的存储方式:
a、UDF变量:
将会被赋值一个指向primary container中page group的page端指 针。
b、其他所有变量:根据以下两种情况:
1)Fully decomposable:在所有的容器中,数据对象都是可以安全分解的。 那么仅仅存储一个指向每个对象primary containe中page group的指 针,如下图:

2)Partially decomposable:在一些容器中可以安全的分解,但是在一些容 器中不可以被分解。可以不能够分解对象到公共的容器中供所有的容器共 享。然而,如果一些数据对象是不可变的或者说一个容器中对象的改 变不会影响到另外一个容器,那么我们就可以分解一些容器的对象,然后 存储在不可分解的容器中(这将对于可分解容器中具有long-live的对象 是非常有益的)。如下图所示:
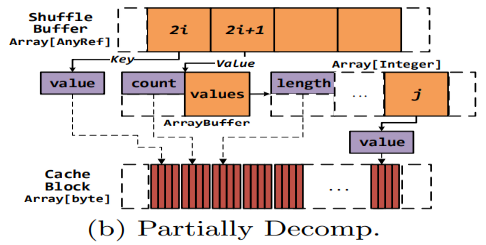
四、评估:(用了真实和综合的数据集,相比较于Spark)
1、减少GC时间高达99.9%。
2、在没有数据溢出的情况下,执行速度加快了22.7倍,在数据溢出情况下,执行速度 加快了41.6倍。
3、消耗内存减少高达46.6%。
4、案例比较如下:






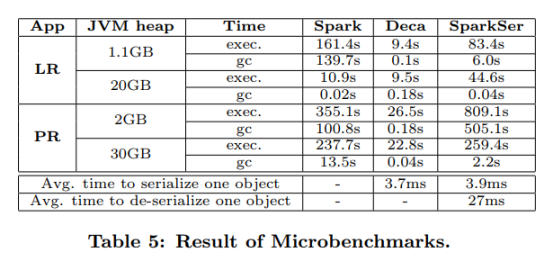
Lifetime-Based Memory Management for Distributed Data Processing Systems的更多相关文章
- These interactions can be expressed as complicated, large scale graphs. Mining data requires a distributed data processing engine
https://databricks.com/blog/2014/08/14/mining-graph-data-with-spark-at-alibaba-taobao.html
- In-Stream Big Data Processing
http://highlyscalable.wordpress.com/2013/08/20/in-stream-big-data-processing/ Overview In recent y ...
- Operating system management of address-translation-related data structures and hardware lookasides
An approach is provided in a hypervised computer system where a page table request is at an operatin ...
- Java (JVM) Memory Model – Memory Management in Java
原文地址:http://www.journaldev.com/2856/java-jvm-memory-model-memory-management-in-java Understanding JV ...
- Linux command line exercises for NGS data processing
by Umer Zeeshan Ijaz The purpose of this tutorial is to introduce students to the frequently used to ...
- Android内存管理(1)WRANGLING DALVIK: MEMORY MANAGEMENT IN ANDROID PART 1
from : http://www.raizlabs.com/dev/2014/03/wrangling-dalvik-memory-management-in-android-part-1-of-2 ...
- 再谈.net的堆和栈---.NET Memory Management Basics
.NET Memory Management Basics .NET memory management is designed so that the programmer is freed fro ...
- FreeRTOS Memory Management ( IAR )
http://www.freertos.org/a00111.html The RTOS kernel allocates RAM each time a task, queue, mutex, so ...
- Open-sourcing LogDevice, a distributed data store for sequential data
https://logdevice.io/blog/2018/09/12/open-sourcing-announcement.html September 12, 2018 We are exc ...
随机推荐
- 查看指定java进程的jvm参数配置命令之jinfo
一.查看所有的参数 jinfo -flags PS:3739为JAVA进程ID Attaching to process ID , please wait... Debugger attached s ...
- robotframework + appium 获取android toast
android toast 获取主要方式是在出现toast的时候查找元素:xpath=//*[contains(@text,'记同步')] ,该xpath 表示为toast信息含有 "记 ...
- extjs4学习-01-准备工作
想学习这个,在这里做个笔记. 创建了svn管理,路径http://ip:端口/repos/doc_jnfwz/liuzhenming/extjs4/extjs4 eclipse 中安装插件,支持在js ...
- Java实现打印功能
用java实现打印,java.awt中提供了一些打印的API,要实现打印,首先要获得打印对象,然后继承Printable实现接口方法print,以便打印机进行打印,最后用Graphics2D直接输出直 ...
- WPF 控件事件的一个小坑…
最近想判断一下 Slider 是由鼠标点击而改变值,还是由程序内部代码改变的值,发现鼠标的各种事件比如 MouseDown.MouseUp.MouseLeftButtonDown 什么的,都没有任何反 ...
- 深入理解Linux内核-I/O体系结构和设备驱动程序
系统总线:1.链接CPU.RAM.I/O设备之间的数据流动.例如:PCI.ISA.EISA.MCA.SCSI.USB2.任何I\O设备有且仅能链接一条总线. I\O端口:1.每个连接到I\O总线上的设 ...
- npm WARN build `npm build` called with no arguments. Did you mean to `npm run-script build`?
跑npm build结果如下: npm WARN build `npm build` called with no arguments. Did you mean to `npm run-script ...
- 每日英语:Political Gridlock, Beijing Style
To admirers outside the country, China's political system stands far above the dysfunctional democra ...
- mysql 配置路径
1)关于配置文件路径 有时候,我发现虽然尝试修改了配置文件的一些变量,但是并没有生效.后来才发现原来是因为修改的文件并非MySQL服务器读取的配置文件. 如果不清楚MySQL当前使用的配置文件路径,可 ...
- http post multipart/mixed的文件.
依赖. <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>ht ...