Solr入门之(8)中文分词器配置
Solr中虽然提供了一个中文分词器,但是效果很差,可以使用IKAnalyzer或Mmseg4j 或其他中文分词器。
一、IKAnalyzer分词器配置:
1、下载IKAnalyzer(IKAnalyzer2012_u6)包,当前使用版本IKAnalyzer2012_u6.jar
2、将IKAnalyzer2012_u6包下的IKAnalyzer.cfg.xml和stopword.dic复制到solr应用/WEB-INF/classes下。
3、在${solr_home}/[core路径下]/conf/schema.xml中增加一个自定义fieldType:
<!-- 中文IK分词 -->
<fieldType name="text_ik_analyzer" positionIncrementGap="100" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.solr.IKTokenizerFactory"/>
<filter class="solr.StopFilterFactory" enablePositionIncrements="true" words="stopwords.txt" ignoreCase="true"/>
<filter class="solr.WordDelimiterFilterFactory" splitOnCaseChange="1" catenateAll="0" catenateNumbers="1" catenateWords="1" generateNumberParts="1" generateWordParts="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EnglishPorterFilterFactory" protected="protwords.txt"/>
<filter class="solr.RemoveDuplicatesTokenFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.solr.IKTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory" ignoreCase="true" expand="true" synonyms="synonyms.txt"/>
<filter class="solr.StopFilterFactory" words="stopwords.txt" ignoreCase="true"/>
<filter class="solr.WordDelimiterFilterFactory" splitOnCaseChange="1" catenateAll="0" catenateNumbers="0" catenateWords="0" generateNumberParts="1" generateWordParts="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EnglishPorterFilterFactory" protected="protwords.txt"/>
<filter class="solr.RemoveDuplicatesTokenFilterFactory"/>
</analyzer>
</fieldType>
4、在schema.xml中增加一个字段:
<field name="test_ik_field" type="text_ik_analyzer" indexed="true" stored="true" termVectors="true" termPositions="true" termOffsets="true" />
5、启动solr应用,即可在客户端界面查看分词效果。
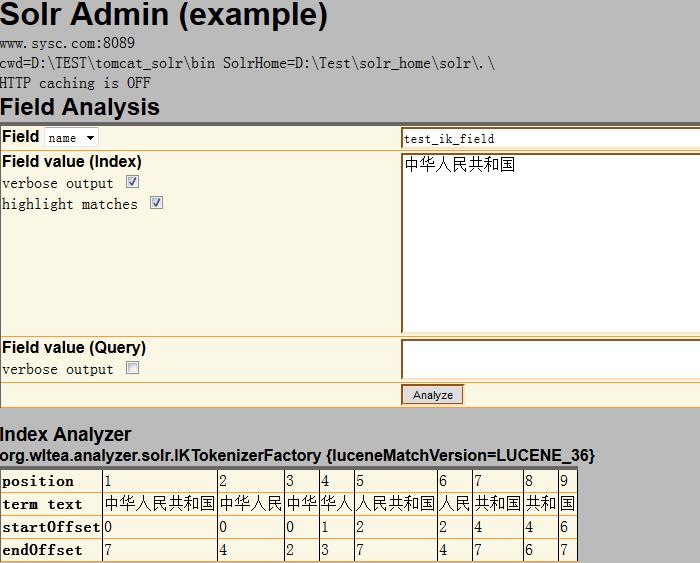
二、Mmseg4j分词器:
配置方式与上面类似,暂时未定义。
Solr入门之(8)中文分词器配置的更多相关文章
- 真分布式SolrCloud+Zookeeper+tomcat搭建、索引Mysql数据库、IK中文分词器配置以及web项目中solr的应用(1)
版权声明:本文为博主原创文章,转载请注明本文地址.http://www.cnblogs.com/o0Iris0o/p/5813856.html 内容介绍: 真分布式SolrCloud+Zookeepe ...
- 2.IKAnalyzer 中文分词器配置和使用
一.配置 IKAnalyzer 中文分词器配置,简单,超简单. IKAnalyzer 中文分词器下载,注意版本问题,貌似出现向下不兼容的问题,solr的客户端界面Logging会提示错误. 给出我配置 ...
- Solr6.5.0配置中文分词器配置
准备工作: solr6.5.0安装成功 1.去官网https://github.com/wks/ik-analyzer下载IK分词器 2.Solr集成IK a)将ik-analyzer-solr6.x ...
- Es学习第五课, 分词器介绍和中文分词器配置
上课我们介绍了倒排索引,在里面提到了分词的概念,分词器就是用来分词的. 分词器是ES中专门处理分词的组件,英文为Analyzer,定义为:从一串文本中切分出一个一个的词条,并对每个词条进行标准化.它由 ...
- 对本地Solr服务器添加IK中文分词器实现全文检索功能
在上一篇随笔中我们提到schema.xml中<field/>元素标签的配置,该标签中有四个属性,分别是name.type.indexed与stored,这篇随笔将讲述通过设置type属性的 ...
- Windows下面安装和配置Solr 4.9(三)支持中文分词器
首先将下载解压后的solr-4.9.0的目录里面F:\tools\开发工具\Lucene\solr-4.9.0\contrib\analysis-extras\lucene-libs找到lucene- ...
- Solr学习笔记之2、集成IK中文分词器
Solr学习笔记之2.集成IK中文分词器 一.下载IK中文分词器 IK中文分词器 此文IK版本:IK Analyer 2012-FF hotfix 1 完整分发包 二.在Solr中集成IK中文分词器 ...
- windows 上配置solr5.2.1+solr4.3+中文分词器
搭建5.2.1 1.下载 Tomcat解压后的目录为 D:\Program Files\Apache Software Foundation\apache-tomcat-8.0.22 solr解压后的 ...
- Solr6.5配置中文分词器
Solr作为搜索应用服务器,我们在使用过程中,不可避免的要使用中文搜索.以下介绍solr自带的中文分词器和第三方分词器IKAnalyzer. 注:下面操作在Linux下执行,所添加的配置在windo ...
随机推荐
- 微博地址url(id)与mid的相互转换 Java版
原理: 新浪微博的URL都是如:http://weibo.com/2480531040/z8ElgBLeQ这样三部分. 第一部分(绿色部分)为新浪微博的域名,第二部分(红色部分)为博主Uid,第三部分 ...
- Apache shutdown unexpectedly启动错误解决方法
这个问题比较常见, 通常是80.443端口被占用 cmd 通过运行apache/bin/httpd.exe 打印如下log: (OS 10048)通常每个套接字地址(协议/网络地址/端口)只允许使用一 ...
- VB中 ByRef与ByVal区别
函数调用的参数传递有"值传递"和"引用传递"两种传递方式.如果采用"值传递",在函数内部改变了参数的值,主调程序的对应变量的值不会改变:如果 ...
- mysql导入导出数据库命令
1.导出数据库:mysqldump -u 用户名 -p 数据库名 > 导出的文件名 如我输入的命令行: mysqldump -u root -p news > /home/jason/sq ...
- Jenkins安装部署
官方文档:https://wiki.jenkins-ci.org/display/JENKINS/Installing+Jenkins+on+Red+Hat+distributions#Install ...
- pydev导入eclipse
编辑器:Python 自带的 IDLE 简单快捷, 学习Python或者编写小型软件的时候.非常有用. 编辑器: Eclipse + pydev插件 1. Eclipse是写JAVA的IDE, 这样就 ...
- Divide and Conquer:Cable Master(POJ 1064)
缆绳大师 题目大意,把若干线段分成K份,求最大能分多长 二分法模型,C(x)就是题干的意思,在while那里做下文章就可以了,因为这个题目没有要求长度是整数,所以我们要不断二分才行,一般50-100次 ...
- jquery.dataTable分页
jsp页面,引入几个js <link type="text/css" rel="stylesheet" href="/library/css/b ...
- Struts2应用流程注解
当Web容器收到请求(HttpServletReques t)它将请求传递给一个标准的的过滤链包括(ActionContextCleanUp)过滤器. 经过Other filters(SiteMe ...
- struts2.0整合json
框架:struts2.0+hibernate2+spring 今天写代码时,需要用到json,我就直接加了两个jar包:json-lib-2.1-jdk15.jar,struts2-json-plug ...