Hadoop入门学习笔记---part3
2015年元旦,好好学习,天天向上。良好的开端是成功的一半,任何学习都不能中断,只有坚持才会出结果。继续学习Hadoop。冰冻三尺,非一日之寒!
经过Hadoop的伪分布集群环境的搭建,基本对Hadoop有了一个基础的了解。但是还是有一些理论性的东西需要重复理解,这样才能彻底的记住它们。个人认为重复是记忆之母。精简一下:
NameNode:管理集群,并且记录DataNode文件信息;
SecondaryNameNode:可以做冷备份,对一定范围内的数据作快照性备份;
DataNode:存储数据;
JobTracker:管理任务,并将任务分配给taskTracker;
TaskTracker:任务的执行方。
HDFS现在都知道是Hadoop分布式文件系统,但是关于它的其它方面比如说它的体系结构就不知道了。因此,还得在此基础上理解Hadoop分布式文件系统的体系结构以及相关基本概念。《Hadoop入门学习笔记---part3》的重点内容就是分布式文件系统和HDFS;HDFS的shell操作,NameNode体系结构;DataNode的体系结构。
- 分布式文件系统和HDFS:
DFS(分布式文件系统)是一种允许文件通过网路在多台主机上分享的文件系统。可以让多台机器上的多用户分享文件和存储空间。
HDFS仅仅是DFS中的一种,适用于一次写入多次查询的情况,不支持并发写的情况,同时也不适合于小文件。
下面就可以在已经搭建好的hadoop伪分布环境下进行操作了。首先查看hadoop的进程是否已经启动。如果没有启动,需要启动后再进行下面的操作。
#jps
#start-all.sh (如果没有启动)
2. HDFS的shell操作:
实际上HDFS的shell操作和Linux上的操作基本上是类似的。只是列举一些很是常用的命令,给一个抛砖引玉的作用。能够知道是怎么回事,怎么用就行。
#hadoop fs –ls / 查看根目录下的内容
#hadoop fs –lsr / 递归查看根目录下的内容
#hadoop fs –mkdir /hello 在HDFS的根目录下新建一个hello的文件夹
#hadoop fs –put /root/test /hello 将linux中root目录下的test文件上传到HDFS的hello目录下,当只有源路径而没有目标路径时,默认表示文件名称,不是文件夹,为上传后的名称
#hadoop fs –get /hello/test . 将HDFS上的文件下载到本地。注意在命令的最后面是一个点,而这个点就是表示本地路径,即为linux的路径,可以将点改为任何路径
#hadoop fs –text /hello/test 直接在HDFS上查看hello目录下的test文件
#hadoop fs –rm /hello/test 删除hello目录下的test文件,只针对文件
#hadoop fs –rmr /hello 递归地删除HDFS上的hello目录,包含文件和文件夹 **#hadoop fs –help +命令 查看帮助文档
**#hadoop fs –ls / 实际上是命令#hadoop fs –ls hdfs://hadoop:9000/ 是一样的效果,就是简写。注意里面的hadoop是我机器的主机名,应根据你自己的实际来选择
因为这样的命令太多,我就不一一列举了。只要会使用linux命令的,基本上很容易上手。类推就行!
3. NameNode的体系结构:
HDFS的两大核心就是NameNode和DataNode。是整个文件系统的管理节点,维护整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表,接收用户的操作请求。本人仅概括性的总结,详细的介绍还请参看官方文档。
文件包括:
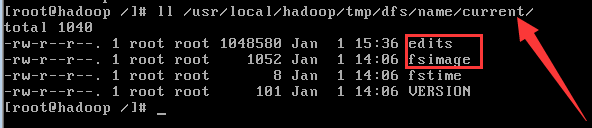
(1) fsimage:文件系统镜像,元数据镜像文件,存储某一时段NameNode内存元数据信息;
(2) edits: 操作日志文件,事务文件;
(3) fstime: 保存最近一次checkpoint的时间。
以上这些文件是保存在Linux上。
SecondaryNameNode:
从NameNode上下载元数据信息(fsimage和edits),然后把二者合并,生成新的fsimage,在本地保存,并将其推送到NameNode,同时重置NameNode的edits。实际上就是冷备份。
在linux中的路径如下如下,你可以看到以上介绍的文件。
4. DataNode的体系结构:
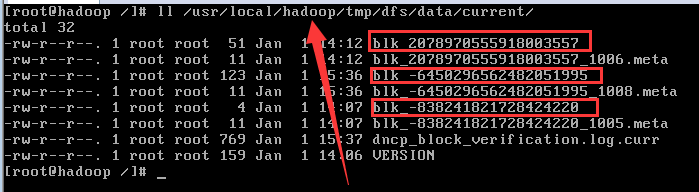
提供真实文件数据的存储服务;还得明白一个关键术语:数据块(block),最基本的存储单位;对于文件内存而言,一个文件的长度大小问size。那么从文件的0偏移开始,按照固定的大小,顺序对文件进行划分并编号,划分好的每一个块称为一个block。
HDFS默认的Block大小是64MB,以一个256MB的文件为例,256MB/64MB=4个Block。
与普通文件系统不同的是,HDFS中,如果文件小于一个数据块的大小,并不占用整个数据块存储空间。即:HDFS的DataNode在存储数据时,如果原始文件大小大于64MB,按照64MB大小划分,如果小于64MB,就按实际大小保存。
Repication:多副本,默认为3个,存放在不同的机器上。
在linux中的实际存储为下图所示。同时可以看到存储数据的元信息。
在《Hadoop入门学习笔记---part4》中将利用java操作HDFS,看看如何利用java实现的应用程序进行操作。
作者:itRed
邮箱:it_red@sina.com
博客:http://www.cnblogs.com/itred 个人网站:http://wangxingyu.jd-app.com
***版权声明:本文版权归作者和博客园共有,欢迎转载,但请在文章显眼位置标明文章出处。未经本人书面同意,将其作为他用,本人保留追究责任的所有权利。
Hadoop入门学习笔记---part3的更多相关文章
- Hadoop入门学习笔记---part4
紧接着<Hadoop入门学习笔记---part3>中的继续了解如何用java在程序中操作HDFS. 众所周知,对文件的操作无非是创建,查看,下载,删除.下面我们就开始应用java程序进行操 ...
- Hadoop入门学习笔记---part2
在<Hadoop入门学习笔记---part1>中感觉自己虽然总结的比较详细,但是始终感觉有点凌乱.不够系统化,不够简洁.经过自己的推敲和总结,现在在此处概括性的总结一下,认为在准备搭建ha ...
- Hadoop入门学习笔记---part1
随着毕业设计的进行,大学四年正式进入尾声.任你玩四年的大学的最后一次作业最后在激烈的选题中尘埃落定.无论选择了怎样的选题,无论最后的结果是怎样的,对于大学里面的这最后一份作业,也希望自己能够尽心尽力, ...
- Hadoop入门学习笔记(一)
Week2 学习笔记 Hadoop核心组件 Hadoop HDFS(分布式文件存储系统):解决海量数据存储 Hadoop YARN(集群资源管理和任务调度框架):解决资源任务调度 Hadoop Map ...
- Hadoop入门学习笔记总结系列文章导航
一.为何要学习Hadoop? 这是一个信息爆炸的时代.经过数十年的积累,很多企业都聚集了大量的数据.这些数据也是企业的核心财富之一,怎样从累积的数据里寻找价值,变废为宝炼数成金成为当务之急.但数据增长 ...
- Hadoop入门学习笔记之一
http://hadoop.apache.org/docs/r1.2.1/api/index.html 适当的利用 null 在map中可以实现对文件的简单处理,如排序,和分集合输出等. 需要关心的内 ...
- Hadoop入门学习笔记(二)
Yarn学习 YARN简介 YARN是一个通用资源管理系统和调度平台,可为上层应用提供统一的资源管理和调度 YARN功能说明 资源管理系统:集群的硬件资源,和程序运行相关,比如内存.CPU等. 调度平 ...
- Hadoop入门学习笔记-第一天 (HDFS:分布式存储系统简单集群)
准备工作: 1.安装VMware Workstation Pro 2.新建三个虚拟机,安装centOS7.0 版本不限 配置工作: 1.准备三台服务器(nameNode10.dataNode20.da ...
- Hadoop入门学习笔记-第二天 (HDFS:NodeName高可用集群配置)
说明:hdfs:nn单点故障,压力过大,内存受限,扩展受阻.hdfs ha :主备切换方式解决单点故障hdfs Federation联邦:解决鸭梨过大.支持水平扩展,每个nn分管一部分目录,所有nn共 ...
随机推荐
- css3中perspective
perspective 属性定义 3D 元素距视图的距离,以像素计.该属性允许改变 3D 元素查看 3D 元素的视图.当为元素定义 perspective 属性时,其子元素会获得透视效果,而不是元素本 ...
- Android线程管理之ThreadLocal理解及应用场景
前言: 最近在学习总结Android的动画效果,当学到Android属性动画的时候大致看了下源代码,里面的AnimationHandler存取使用了ThreadLocal,激起了我很大的好奇心以及兴趣 ...
- Node.js:OS模块
os模块,可以用来获取操作系统相关的信息和机器物理信息,例如操作系统平台,内核,cpu架构,内存,cpu,网卡等信息. 使用如下所示: const os = require('os'); var de ...
- OpenGL超级宝典笔记----框架搭建
自从工作后,总是或多或少的会接触到客户端3d图形渲染,正好自己对于3d图形的渲染也很感兴趣,所以最近打算从学习OpenGL的图形API出发,进而了解3d图形的渲染技术.到网上查了一些资料,OpenGL ...
- 一个表缺失索引发的CPU资源瓶颈案例
背景 近几日,公司的应用团队反应业务系统突然变慢了,之前是一直比较正常.后与业务部门沟通了解详情,得知最近生意比较好,同时也在做大的促销活动,使得业务数据处理的量出现较大的增长,最终系统在处理时出现瓶 ...
- MAC下 mysql不能插入中文和中文乱码的问题总结
MAC下 mysql不能插入中文和中文乱码的问题总结 前言 本文中所提到的问题解决方案,都是基于mac环境下的,但其他环境,比如windows应该也适用. 问题描述 本文解决下边两个问题: 往mysq ...
- 界面设计技法之css布局
css布局之于页面就如同ECMAScript之于JS一般,细想一番,html就如同语文,css就如同数学,js呢,就是物理,有些扯远,这里就先不展开了. 回到主题,从最开始的css到如今的sass(l ...
- Angular (SPA) WebPack模块化打包、按需加载解决方案完整实现
文艺小说-?2F,言情小说-?3F,武侠小说-?9F long long ago time-1-1:A 使用工具,long long A ago time-1-2:A 使用分类工具,long long ...
- CSS3自定义滚动条样式 -webkit-scrollbar(转)
有没有觉得浏览器自带的原始滚动条很不美观,同时也有看到很多网站的自定义滚动条显得高端,就连chrome32.0开发板都抛弃了原始的滚动条,美观多了.那webkit浏览器是如何自定义滚动条的呢? 前言 ...
- Crystal Clear Applied: The Seven Properties of Running an Agile Project (转载)
作者Alistair Cockburn, Crystal Clear的7个成功要素,写得挺好. 敏捷方法的关注点,大家可以参考,太激动所以转载了. 原文:http://www.informit.com ...