select * 为什么不好? limit 1 为什么好? --mysql SQL语句优化
问题一:
Select * from student; 这种语句不好
我的理解:根据Innode存储引擎以及网上的各种资料所说的innodb的B+树索引结构可以分析出,当在非聚集索引列上搜索若用select * 会发生索引覆盖的问题。下面请看演示:
首先我们的表中的数据是:
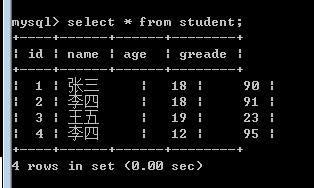
表的结构是:
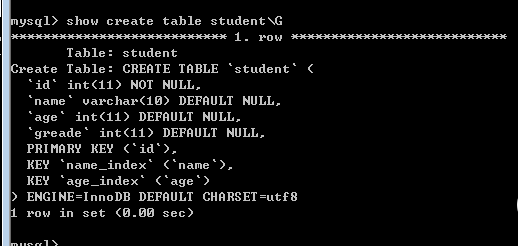
我们可以看到:表里有三个索引,primary 索引,name列的name_index索引,以及age列的age_index索引。
然后我们进行搜索:
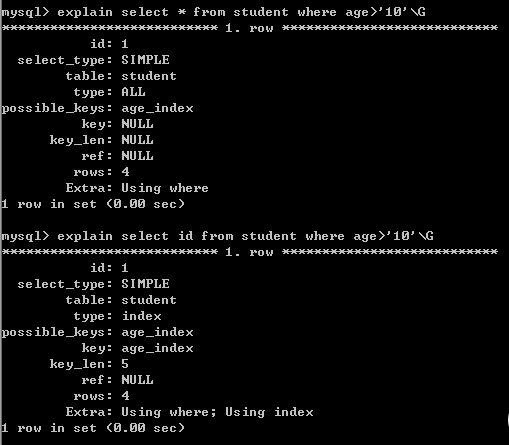

我们发现分别搜索*,id,age三个列进行了搜索,我们预计的结果是*不使用索引,id和age会使用age_index索引,但是呈现的是三个都使用了索引。然后我们在以name作为where的判定条件进行select * 搜索。我们预计的是也不使用name_index,但explain现实的依旧是使用索引,如下:

这是由于我们的表中的数据量太小,当表中的数据量较小时,存储引擎的优化器依旧会使用非聚集索引然后再进行一次书签查找。
索引我们给表中在增加几条数据,如下:
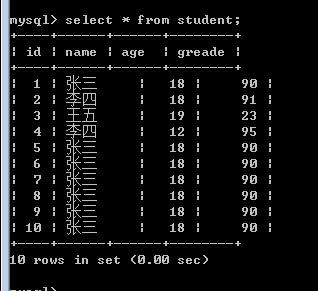
然后再进行刚才的以name为判定条件进行select*查找。
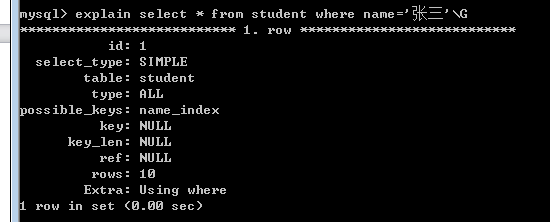

我们发现此时,select * 是没有使用非聚集索引name_index,而id是使用到了索引的。
所以,以上理论成立!
总结如下:

问题二:limit 1 为什么效率高
网上有一篇文章说的比较清楚:http://www.linuxidc.com/Linux/2013-03/81974.htm
大概意思是因为加上LIMIT 1,只要找到了对应的一条记录,就不会继续向下扫描了,效率会大大提高。
由于mysql自带的explain和profiles 并不能检测搜索了多少条语句,所以并不能直观的验证,可通过cpu使用率间接分析,但完整的测试需要用到大量非重复数据,所以没有直观的截图来验证。这里来引用mysql官方文档来作为例证:
Mysql官方文档对于limit的定义:
7.3.1.10 LIMIT Optimization
In some cases, MySQL handles a query differently when you are using LIMIT row_count and not using HAVING:
If you are selecting only a few rows with LIMIT, MySQL uses indexes in some cases when normally it would prefer to do a full table scan.
If you use LIMIT row_count with ORDER BY, MySQL ends the sorting as soon as it has found the firstrow_count rows of the sorted result, rather than sorting the entire result. If ordering is done by using an index, this is very fast. If a filesort must be done, all rows that match the query without the LIMIT clause must be selected, and most or all of them must be sorted, before it can be ascertained that the first row_count rows have been found. In either case, after the initial rows have been found, there is no need to sort any remainder of the result set, and MySQL does not do so.
When combining LIMIT row_count with DISTINCT, MySQL stops as soon as it finds row_count unique rows.
In some cases, a GROUP BY can be resolved by reading the key in order (or doing a sort on the key) and then calculating summaries until the key value changes. In this case, LIMIT row_count does not calculate any unnecessary GROUP BY values.
As soon as MySQL has sent the required number of rows to the client, it aborts the query unless you are usingSQL_CALC_FOUND_ROWS.
LIMIT 0 quickly returns an empty set. This can be useful for checking the validity of a query. When using one of the MySQL APIs, it can also be employed for obtaining the types of the result columns. (This trick does not work in the MySQL Monitor (the mysql program), which merely displays Empty set in such cases; you should instead use SHOW COLUMNS or DESCRIBE for this purpose.)
When the server uses temporary tables to resolve the query, it uses the LIMIT row_count clause to calculate how much space is required.
从上面加大的字体可以看出,mysql官方文档又说到:
When combining MySQL stops as soon as it finds
所以,例证成
select * 为什么不好? limit 1 为什么好? --mysql SQL语句优化的更多相关文章
- MYSQL SQL语句优化
1.EXPLAIN 做MySQL优化,我们要善用EXPLAIN查看SQL执行计划. 下面来个简单的示例,标注(1.2.3.4.5)我们要重点关注的数据: type列,连接类型.一个好的SQL语句至少要 ...
- 自制小工具大大加速MySQL SQL语句优化(附源码)
引言 优化SQL,是DBA常见的工作之一.如何高效.快速地优化一条语句,是每个DBA经常要面对的一个问题.在日常的优化工作中,我发现有很多操作是在优化过程中必不可少的步骤.然而这些步骤重复性的执行,又 ...
- MySQL - SQL语句优化方法
1.使用 show status 了解各种 SQL 的执行频率 mysql> show status like 'Com%'; 该命令可以查询 sql 命令的执行次数. 2.定位执行效率较低的 ...
- 重新学习MySQL数据库12:从实践sql语句优化开始
版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/a724888/article/details/79394168 本文不堆叠网上海量的sql优化技巧或 ...
- MYSQL查询语句优化
mysql的性能优化包罗甚广: 索引优化,查询优化,查询缓存,服务器设置优化,操作系统和硬件优化,应用层面优化(web服务器,缓存)等等.这里的记录的优化技巧更适用于开发人员,都是从网络上收集和自己整 ...
- mysql sql语句大全(转载)
1.说明:创建数据库 CREATE DATABASE database-name 2.说明:删除数据库 drop database dbname 3.说明:备份sql server --- 创建 ...
- MYSQL SQL语句技巧初探(一)
MYSQL SQL语句技巧初探(一) 本文是我最近了解到的sql某些方法()组合实现一些功能的总结以后还会更新: rand与rand(n)实现提取随机行及order by原理的探讨. Bit_and, ...
- MySQL常用SQL语句优化
推荐阅读这篇博文,索引说的非常详细到位:http://blog.linezing.com/?p=798#nav-3-2 在数据库日常维护中,最常做的事情就是SQL语句优化,因为这个才是影响性能的最主要 ...
- MySQL基础操作&&常用的SQL技巧&&SQL语句优化
基础操作 一:MySQL基础操作 1:MySQL表复制 复制表结构 + 复制表数据 create table t3 like t ...
随机推荐
- python学习之split()
定义: Python split()通过指定分隔符对字符串进行切片,如果参数num 有指定值,则仅分隔 num 个子字符串 语法: str.split(str="", num=st ...
- IntelliJ IDEA Mybatis Plugin 破解安装
破解文件和截图全部在附件中,亲自破解,在使用中,感觉很棒: https://files.cnblogs.com/files/icenter/carck.zip
- Apache: You don't have permission to access / on this server
当我们需要使用Apache配置虚拟主机时,有可能会出现这个问题:Apache: You don't have permission to access / on this server # 同IP不同 ...
- Linux命令之rename
一.引言 今天才知道Linux下的rename有两个版本,util-linux工具集的rename和Perl版本的rename,而两者的用法是明显不一样的,Perl版rename相对比较强大 二.对比 ...
- linux学习笔记10---命令nl
nl命令在linux系统中用来计算文件中行号.nl 可以将输出的文件内容自动的加上行号! nl命令读取 file 参数(缺省情况下标准输入),计算输入中的行号,将计算过的行号写入标准输出.在输出中,n ...
- git patch生成方法
先把改动commit掉,然后生产改动patch给提交代码的同事,详细操作过程例如以下: 改动代码的同事: git format-patch al821_xxx origin/al821_xxx 会生成 ...
- 数据泵导出oracle 10g数据库
首先连接sqlplus: sqlplus /nolog conn system/manager (或者连接其他用户) 1.创建whboa目录,用于存放导出的dmp文件(需要提前手动创建目录“E:\or ...
- 【vijos】1543 极值问题(数论+fib数)
https://vijos.org/p/1543 好神奇的一题.. 首先我竟然忘记n可以求根求出来,sad. 然后我打了表也发现n和m是fib数.. 严格证明(鬼知道为什么这样就能对啊,能代换怎么就能 ...
- javaEE面试重点
Hibernate工作原理及为什么要用? 原理: 1. 读取并解析配置文件 2. 读取并解析映射信息.创建SessionFactory 3. 打开Sesssion 4. 创建事务Transation ...
- Sql server不同数据类型间拼接(+)
)+'m' 输出 4m 若 +'m' 输出:在将 varchar 值 'm' 转换成数据类型 int 时失败.