【week2】 词频统计第一次更新
词频统计:
对每个功能预计时间:
| 功能 | 预计(min) | 实际(min) |
| 数据流读入 | 20 | 40 |
| 正则规范字符串 | 15 | 20 |
| 排序 | 30 | 45 |
| 输出 | 20 | 30 |
| 其他 | 25 |
词频统计psp
| 日期 | 类型 | 任务 | 开始时间 | 结束时间 | 被打断时间 | 实际 | 计划 |
| 9.11 | 分析需求 | 看词频统计spec | 10:30 | 10:50 | 5 | 15 | 10 |
| 9.12 | 具体设计 |
设计词频分析流程包括 (读入文件流、去掉文章中非单词、按词频value降序排列、输出) |
10:00 | 11:00 | 10 | 50 | 40 |
| 9.12 | 具体编码 |
阅读上次代码,加入排序以及测试 (当前完成从控制台输入文件名称) |
15:00 | 18:00 | 20 | 160 | 120 |
| 9.12 | 代码复审 | 写博客,边写边看 分段上传 | 22:40 | 23:17 | 7 | 30 | 40 |
对比分析原因:首先以前对代码的练习不够,不能熟练编码。
对于数据流部分,多出来的时间是浪费在类型转换上,string类型与文件流之间的转换花费了很长时间。
对于正则表达式不熟悉,这样的东西总是记不住,浪费了时间。
sort方法是后学习的,原来只会用c++来理解,转换成Java花费了时间。
功能1:小文件输入键盘在控制台下输入命令。
在控制台输入文件名:使用scanner获取控制台数据
System.out.println("请输入要统计的文件路径");
Scanner sc = new Scanner(System.in);
String road = sc.nextLine();
FileInputStream fis = new FileInputStream(road);// 要读的文件路径
InputStreamReader isr = new InputStreamReader(fis);// 字符流
BufferedReader infile = new BufferedReader(isr); // 缓冲
从读取的txt文件中获取单词,使用正则,将非单词的部分转换成空格
String words[];
file = file.toLowerCase();
//正则将非字母,符号等用空格代替
file = file.replaceAll("[^A-Za-z]", " ");
file = file.replaceAll("\\s+", " ");
words = file.split("\\s+");
将获取的键值对存入hashmap
for (int i = 0; i < words.length; i++) {
String key = words[i];
if (map.get(key) != null) {
int value = ((Integer) map.get(key)).intValue();
value++;
map.put(key, new Integer(value));
} else {
map.put(key, new Integer(1));
}
}
对单词按词频(即键值对的value)进行降序排列。重写Collection类中的sort方法,完成降序。
List<Map.Entry<String,Integer>> list =new ArrayList<Map.Entry<String,Integer>(map.entrySet());
Collections.sort(list,new Comparator<Map.Entry<String,Integer>>(){
@Override
public int compare(Entry<String, Integer> arg0, Entry<String, Integer> arg1) {
// TODO Auto-generated method stub
return arg1.getValue().compareTo(arg0.getValue());
}
});
对完成排序的键值对进行输出。使用util.Map包下的Entry对hashMap进行遍历输出
for(Map.Entry<String, Integer>mapping:list){
System.out.println(mapping.getKey()+","+mapping.getValue());
}
运行结果:


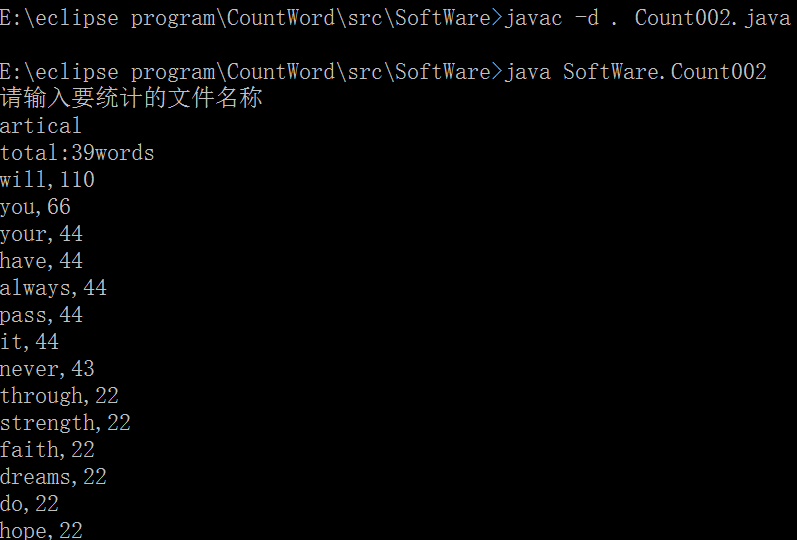
功能2. 支持命令行输入英文作品的文件名
>wf gone_with_the_wand
total 1234567 words
部分代码如下:
System.out.println("请输入要统计的文件名称");
Scanner sc = new Scanner(System.in);
String road = "E:\\artical\\";
road+=sc.nextLine();
road+=".txt";
将文件位置在代码中进行拼接,运行结果如下

功能3. 支持命令行输入存储有英文作品文件的目录名,批量统计。
读入目录名,循环遍历每个txt文件,部分代码如下
System.out.println("请输入要批量统计的文件集合路径");
Scanner sc = new Scanner(System.in);
String road = sc.nextLine();
//批量文件
File f= new File(road);
File lis[]=f.listFiles();
for(int w=0;w<lis.length;w++){
String fileName=lis[w].getName();
System.out.println(fileName);
}
System.out.println("************");
for(int w=0;w<lis.length;w++){
String fileName=lis[w].getName();
System.out.println(fileName);
FileInputStream fis = new FileInputStream(lis[w]);
运行结果部分截图如下:

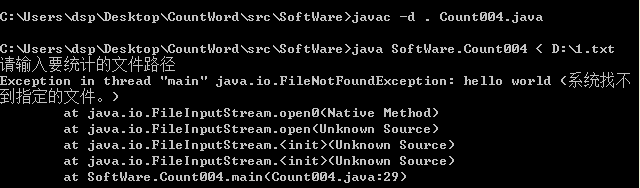
功能4. 从控制台读入英文单篇作品
在控制台可以输入英文文章名字或者文章内容
if(args.length==0){
Scanner in= new Scanner(System.in);
FileWriter fr = new FileWriter(new File("E:\\artical\\restlt.txt"));
while(in.hasNext()){
fr.write(in.nextLine()+"\r\n");
}
fr.close();
in.close();
}
以上代码将要识别的txt文件先写到result.txt文件中。< 为重定向对标准输入的控制
git:git://git.coding.net/yumiaomiao/WordCount.git
http:https://git.coding.net/yumiaomiao/WordCount.git
ssh:git@git.coding.net:yumiaomiao/WordCount.git
【week2】 词频统计第一次更新的更多相关文章
- HW—词频统计
第一次个人作业——词频统计 第一次做这种大作业,明显感觉陌生,各种规范和技能也是第一次使用,希望自己好运. 目录:一.基本要求 二.需求分析及时间估计 三.实现思路及过程 四.测试用例.时间性能分析及 ...
- 软件工程第一次个人项目——词频统计by11061153柴泽华
一.预计工程设计时间 明确要求: 15min: 查阅资料: 1h: 学习C++基础知识与特性: 4-5h: 主函数编写及输入输出部分: 0.5h: 文件的遍历: 1h: 编写两种模式的词频统计函数: ...
- 词频统计的java实现方法——第一次改进
需求概要 原需求 1.读取文件,文件内包可含英文字符,及常见标点,空格级换行符. 2.统计英文单词在本文件的出现次数 3.将统计结果排序 4.显示排序结果 新需求: 1.小文件输入. 为表明程序能跑 ...
- C# 词频统计 东北师范大学 软件项目管理 第一次作业
一.作为杨老师的学生第一次听杨老师讲课,印象最深的就是:工程中所有步骤之间是乘法,如果任何一步为0,工程就做不出来了.以前所有老师讲到的都是不要太在乎结果,努力的过程很重要,但是这在软件工程中不合适了 ...
- 2nd 词频统计更新
词频统计更新 实现功能:从控制台输入文件路径,并统计单词总数及不重复的单词数,并输出所有单词词频,同时排序. 头文件 #include <stdio.h> #include <std ...
- USTC《现代软件工程》春季学期——第一次个人作业:词频统计
截止日期 2018年3月29日23:59 要求 1. 对源文件(*.txt,*.cpp,*.h,*.cs,*.html,*.js,*.java,*.py,*.php等,文件夹内的所有文件)统计字符数. ...
- 效能分析——词频统计的java实现方法的第一次改进
java效能分析可以使用JProfiler 词频统计处理的文件为WarAndPeace,大小3282KB约3.3MB,输出结果到文件 在程序本身内开始和结束分别加入时间戳,差值平均为480-490ms ...
- 作业3-个人项目<词频统计>
上了一天的课,现在终于可以静下来更新我的博客了. 越来越发现,写博客是一种享受.来看看这次小林老师的“作战任务”. 词频统计 单词: 包含有4个或4个以上的字 ...
- 使用HDFS完成wordcount词频统计
任务需求 统计HDFS上文件的wordcount,并将统计结果输出到HDFS 功能拆解 读取HDFS文件 业务处理(词频统计) 缓存处理结果 将结果输出到HDFS 数据准备 事先往HDFS上传需要进行 ...
随机推荐
- idea配置SpringBoot热部署之自动Build
一.pom.xml文件导入所需依赖文件 SpringBoot热部署插件 <dependency> <groupId>org.springframework.boot</g ...
- QP总体结构
QP是一个基于事件驱动的嵌入式系统软件框架,其总体结构如下图. AO活动对象由事件队列和层次状态机两部分组成,每个AO占有一个优先级: QF量子框架由五个数据结构及操作组成,其数据结构采用了uCOS- ...
- Lambda实战(多练习)
import org.junit.Test; import java.math.BigDecimal; import java.time.LocalDate; import java.util.*; ...
- golang 正则表达式 匹配局域网
做一个微服务,需要对http头域里的remoteip做访问限制:所有局域网都要鉴权,其中一些特殊ip,如网关地址,直接拒绝,防止公网访问.正则表达式很好的解决了这个,直接贴代码,读者拿来直接改改就能用 ...
- express with bower in websotrm
0. To install bower , run the following command in webstorm terminal(alt+f12) npm install bower bowe ...
- Apache Tomcat 8.5 安全配置与高并发优化
通常我们在生产环境中,Tomcat的默认配置显然不能满足我们的产品需求,所以很多时候都需要对Tomcat的配置进行调优,以下综合我自己的经验来配置 Tomcat 安全与优化情况,如果你有更好的方案,请 ...
- .NET : 开发ActiveX控件(转载)
我估计有些朋友不清楚ActiveX控件,但这篇博客不是来解释这些概念的.如果你对ActiveX的概念不清楚,请参考这里: http://baike.baidu.com/view/28141.htm 这 ...
- 北京Uber优步司机奖励政策(1月22日
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- 佛山Uber优步司机奖励政策(1月11日~1月17日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- 长沙Uber优步司机奖励政策(1月11日~1月17日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...