【Python学习笔记】Pandas库之DataFrame
1 简介
DataFrame是Python中Pandas库中的一种数据结构,它类似excel,是一种二维表。
或许说它可能有点像matlab的矩阵,但是matlab的矩阵只能放数值型值(当然matlab也可以用cell存放多类型数据),DataFrame的单元格可以存放数值、字符串等,这和excel表很像。
同时DataFrame可以设置列名columns与行名index,可以通过像matlab一样通过位置获取数据也可以通过列名和行名定位,具体方法在后面细说。
2 创建DataFrame
首先声明一下,以下都是使用的Python 3.6.5版本为例,Python2应该也差不多吧(大概
在所有操作之前当然要先import必要的pandas库,因为pandas常与numpy一起配合使用,所以也一起import吧。
import pandas as pd
import numpy as np
如果还没安装直接在cmd里pip安装吧,如果有版本选择问题,参看之前的帖子。
pip install pandas
pip install numpy
2.1 直接创建
可以直接使用pandas的DataFrame函数创建,比如接下来我们随机创建一个4*4的DataFrame。
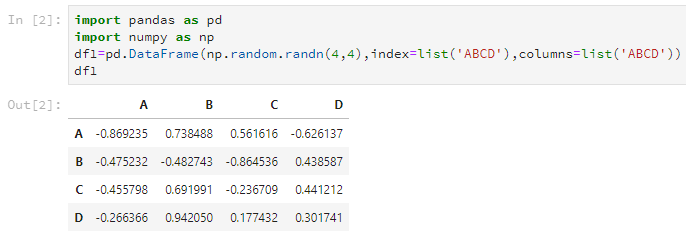
df1=pd.DataFrame(np.random.randn(4,4),index=list('ABCD'),columns=list('ABCD'))
其中第一个参数是存放在DataFrame里的数据,第二个参数index就是之前说的行名(或者应该叫索引?),第三个参数columns是之前说的列名。
后两个参数可以使用list输入,但是注意,这个list的长度要和DataFrame的大小匹配,不然会报错。当然,这两个参数是可选的,你可以选择不设置。
而且发现,这两个list是可以一样的,但是每行每列的名字在index或columns里要是唯一的。
使用python自己的shell展示创建的结果是这样的:

或者在jupyter里面更酷点的样子,接下来都使用jupyter输出展示吧。
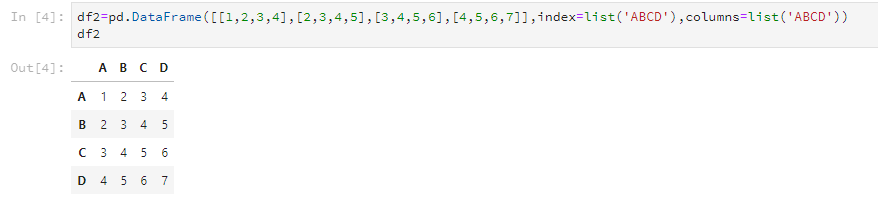
当然,如果你的数据量贼小,也可以自己输入创建,类似这样。
df2=pd.DataFrame([[1,2,3,4],[2,3,4,5],
[3,4,5,6],[4,5,6,7]],
index=list('ABCD'),columns=list('ABCD'))
这样也可以得到这样子的DataFrame:
2.2 使用字典创建
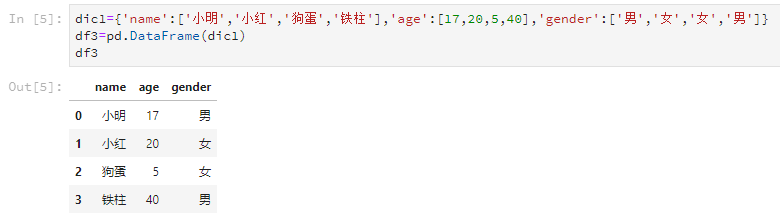
仍然是使用DataFrame这个函数,但是字典的每个key的value代表一列,而key是这一列的列名。比如这样。
dic1={'name':['小明','小红','狗蛋','铁柱'],'age':[17,20,5,40],'gender':['男','女','女','男']}
df3=pd.DataFrame(dic1)
输出结果是这样的
3 查看与筛选数据
python没有matlab的工作区直接查看变量与内容,这大概是python科学计算的一个缺点。所以需要格外的代码来查看,最基本的直接写变量名与print就不说了。
3.1 查看列的数据类型
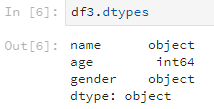
使用dtypes方法可以查看各列的数据类型,比如说刚刚的df3。
df3.dtypes
输出的结果是这样:
3.2 查看DataFrame的头尾
使用head可以查看前几行的数据,默认的是前5行,不过也可以自己设置。
使用tail可以查看后几行的数据,默认也是5行,参数可以自己设置。
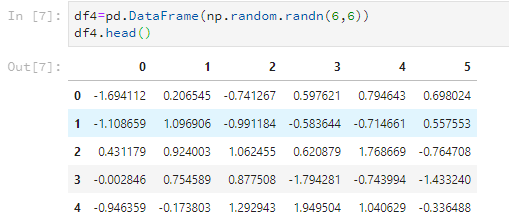
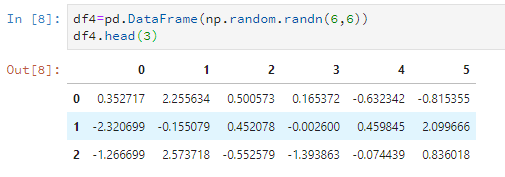
比如随意设置一个6*6的数据,只看前5行。
df4=pd.DataFrame(np.random.randn(6,6))
df4.head()
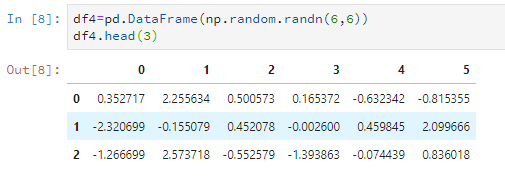
比如只看前3行。
df4.head(3)
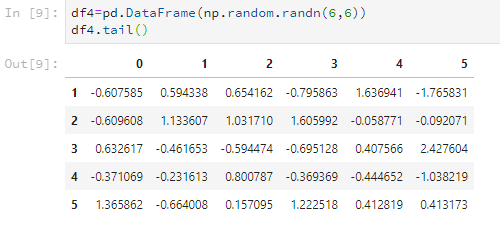
比如看后5行。
df4.tail()
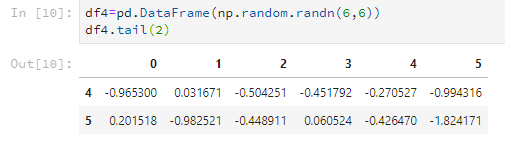
比如只看后2行。
df4.tail(2)
3.3 查看行名与列名
使用index查看行名,columns查看列名。具体由例子感受吧。
查看行名。
df1.index

查看列名。
df3.columns

3.4 查看数据值
使用values可以查看DataFrame里的数据值,返回的是一个数组。
比如说查看所有的数据值。
df3.values
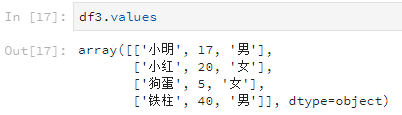
比如说查看某一列所有的数据值。
df3['name'].values

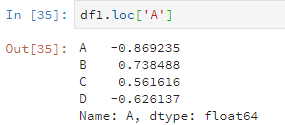
还有另一种操作,使用loc或者iloc查看数据值(但是好像只能根据行来查看?)。区别是loc是根据行名,iloc是根据数字索引(也就是行号)。
比如说这样。
df1.loc['A']
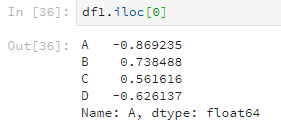
或者这样。
df1.iloc[0]
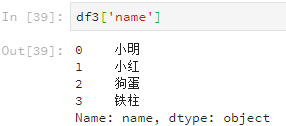
按列进行索引查看数据还能直接使用列名,但这种方法对行索引不适用。
df3['name']
3.5 查看行列数
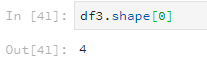
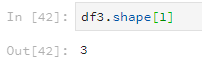
使用shape查看行列数,参数为0表示查看行数,参数为1表示查看列数。
df3.shape[0]
df3.shape[1]
4 基本操作
DataFrame有些方法可以直接进行数据统计,矩阵计算之类的基本操作。
4.1 转置
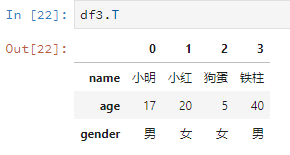
直接字母T,线性代数上线。
比如说把之前的df2转置一下。
df3.T
4.2 描述性统计
使用describe可以对数据根据列进行描述性统计。
比如说对df1进行描述性统计。
df1.describe()
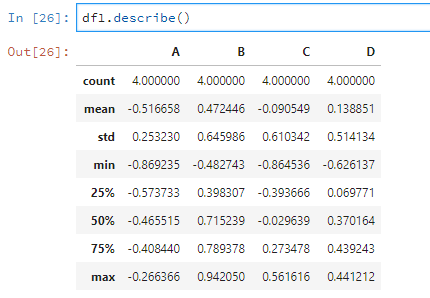
如果有的列是非数值型的,那么就不会进行统计。
如果想对行进行描述性统计,请参看4.1(转置后进行describe呀!)
4.3 计算
使用sum默认对每列求和,sum(1)为对每行求和。比如
df3.sum()
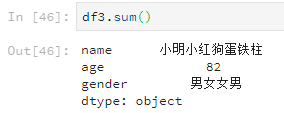
可以发现就算元素是字符串,使用sum也会加起来。
df3.sum(1)
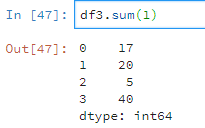
而一行中,有字符串有数值则只计算数值。
数乘运算使用apply,比如。
df2.apply(lambda x:x*2)
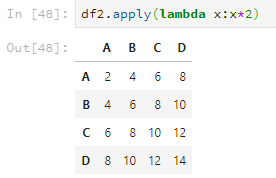
如果元素是字符串,则会把字符串再重复一遍。
乘方运算跟matlab类似,直接使用两个*,比如。
df2**2
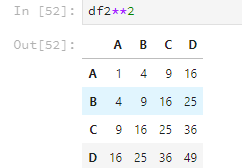
乘方运算如果有元素是字符串的话,就会报错。
4.4 新增
扩充列可以直接像字典一样,列名对应一个list,但是注意list的长度要跟index的长度一致。
df2['E']=['999','999','999','999']
df2
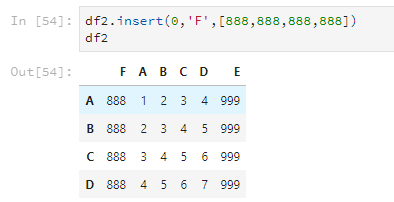
还可以使用insert,使用这个方法可以指定把列插入到第几列,其他的列顺延。
df2.insert(0,'F',[888,888,888,888])
df2
4.5 合并
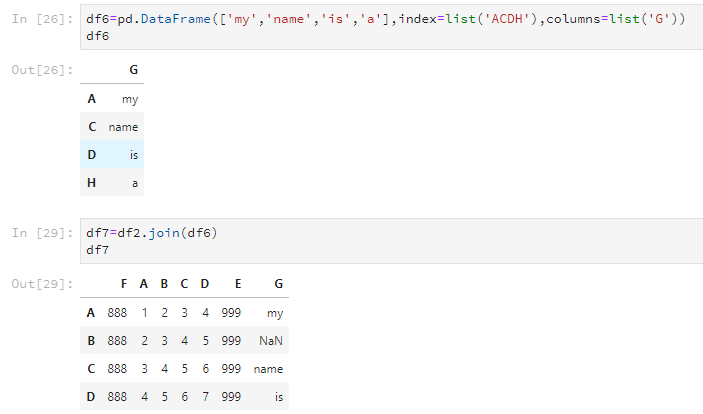
使用join可以将两个DataFrame合并,但只根据行列名合并,并且以作用的那个DataFrame的为基准。如下所示,新的df7是以df2的行号index为基准的。
df6=pd.DataFrame(['my','name','is','a'],index=list('ACDH'),columns=list('G'))
df6
df7=df2.join(df6)
df7
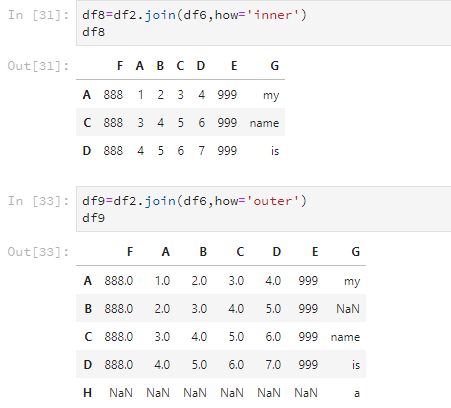
但是,join这个方法还有how这个参数可以设置,合并两个DataFrame的交集或并集。参数为'inner'表示交集,'outer'表示并集。
df8=df2.join(df6,how='inner')
df8
df9=df2.join(df6,how='outer')
df9
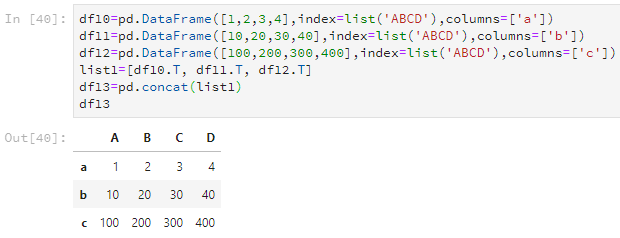
如果要合并多个Dataframe,可以用list把几个Dataframe装起来,然后使用concat转化为一个新的Dataframe。
df10=pd.DataFrame([1,2,3,4],index=list('ABCD'),columns=['a'])
df11=pd.DataFrame([10,20,30,40],index=list('ABCD'),columns=['b'])
df12=pd.DataFrame([100,200,300,400],index=list('ABCD'),columns=['c'])
list1=[df10.T, df11.T, df12.T]
df13=pd.concat(list1)
df13
【Python学习笔记】Pandas库之DataFrame的更多相关文章
- python数据分析之pandas库的DataFrame应用二
本节介绍Series和DataFrame中的数据的基本手段 重新索引 pandas对象的一个重要方法就是reindex,作用是创建一个适应新索引的新对象 ''' Created on 2016-8-1 ...
- python数据分析之pandas库的DataFrame应用一
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值,字符串,布尔型).DateFrame既有行索引也有列索引,可以被看作为由Series组成的字典. 构建Dat ...
- python学习笔记——urllib库中的parse
1 urllib.parse urllib 库中包含有如下内容 Package contents error parse request response robotparser 其中urllib.p ...
- Python学习笔记-PuLP库(3)线性规划实例
本节以一个实际数学建模案例,讲解 PuLP 求解线性规划问题的建模与编程. 1.问题描述 某厂生产甲乙两种饮料,每百箱甲饮料需用原料6千克.工人10名,获利10万元:每百箱乙饮料需用原料5千克.工人2 ...
- [Python学习笔记] turtle库的基本使用
turtle库常用函数 引入turtle模块 import turtle turtle的绘图窗体 #setup()设置窗口大小及位置#setup()可省略turtle.setup(width,heig ...
- Python学习笔记——Matplot库
https://www.cnblogs.com/laoniubile/p/5893286.html 一.基本指令 import matplotlib.pyplot as plt plt.figure ...
- Python学习笔记之基础篇(-)python介绍与安装
Python学习笔记之基础篇(-)初识python Python的理念:崇尚优美.清晰.简单,是一个优秀并广泛使用的语言. python的历史: 1989年,为了打发圣诞节假期,作者Guido开始写P ...
- OpenCV之Python学习笔记
OpenCV之Python学习笔记 直都在用Python+OpenCV做一些算法的原型.本来想留下发布一些文章的,可是整理一下就有点无奈了,都是写零散不成系统的小片段.现在看 到一本国外的新书< ...
- Python学习笔记(十一)
Python学习笔记(十一): 生成器,迭代器回顾 模块 作业-计算器 1. 生成器,迭代器回顾 1. 列表生成式:[x for x in range(10)] 2. 生成器 (generator o ...
- Python学习笔记(六)
Python学习笔记(六) Ubuntu重置root密码 Ubuntu 16.4 目录结构 Ubuntu 命令讲解 1. Ubuntu重置root密码 启动系统,显示GRUB选择菜单(如果默认系统启动 ...
随机推荐
- 【python】如何查看已经安装的python软件包和版本
pip 是一个安装和管理 Python 包的工具 , 是 easy_install 的一个替换品. pip freeze可以查看已经安装的python软件包和版本 pip list 也可以
- poj 1469 COURSES (二分匹配)
COURSES Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 16877 Accepted: 6627 Descript ...
- CentOS 文本操作命令
1.cat 用于查看纯文本文件,显示行号,加-n参数,适合内容较少的情况 2.more 用于查看纯文本文件,适合内容较多的情况 3.less 用于查看纯文本文件,可以上下翻页 4.head 用于查看纯 ...
- 【题解】Atcoder ARC#97 F-Monochrome Cat
好zz啊我……(:д:) 首先我们可以删掉所有只有黑色节点的子树(一定不会遍历到), 且注意到每一个点你一定只会经过一遍.然后又考虑如果起点和终点相同,那么总次数实际上已经固定了:就是遍历整棵树(每一 ...
- 洛谷 P2024 [NOI2001]食物链 解题报告
P2024 [NOI2001]食物链 题目描述 动物王国中有三类动物 A,B,C,这三类动物的食物链构成了有趣的环形.A 吃 B,B 吃 C,C 吃 A. 现有 N 个动物,以 1 - N 编号.每个 ...
- CodeForces.158A Next Round (水模拟)
CodeForces.158A Next Round (水模拟) 题意分析 校赛水题的英文版,坑点就是要求为正数. 代码总览 #include <iostream> #include &l ...
- MySQL基础原创笔记(二)
表索引关键字:PRI primary key 表示主键,唯一 写法: id bigint(20) unsigned primary key not null ,uni UNIQUE 表示唯一 id b ...
- [codeforces/edu31]总结
链接:http://codeforces.com/contest/884 A题: 求86400-ai的前缀和,找到第一个大于等于给定t的即可. B题: 任意相邻两段之间必然有一个0,然后算一下至少的长 ...
- SQL Server作业没有执行的解决方法
SQL Server作业没有执行的解决方法 确保SQL Agent服务启动,并设置为自动启动,否则你的作业不会被执行 设置方法: 我的电脑--控制面板--管理工具--服务--右键 SQLSE ...
- Linux修改用户密码
1. root修改自己 # passwd 2. root修改别人 # passwd oracle //修改oracle的密码