利用主成分分析(PCA)简化数据
一.PCA基础
线性映射(或线性变换),简单的来说就是将高维空间数据投影到低维空间上,那么在数据分析上,我们是将数据的主成分(包含信息量大的维度)保留下来,忽略掉对数据描述不重要的成分。即将主成分维度组成的向量空间作为低维空间,将高维数据投影到这个空间上就完成了降维的工作。
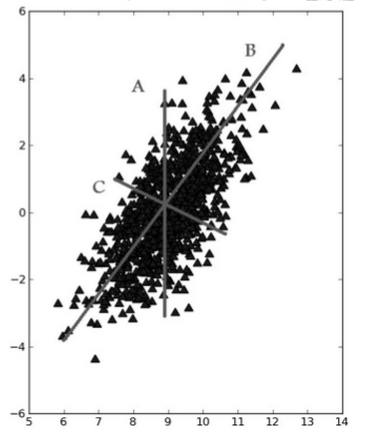
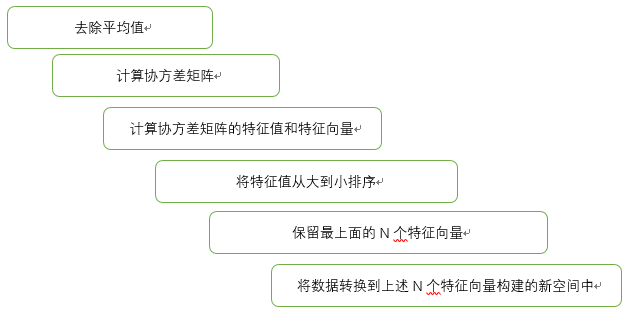
在 PCA中,数据从原来的坐标系转换到了新的坐标系,新坐标系的选择是由数据本身决定的。第一个新坐标轴选择的是原始数据中方差最大的方向,第二个新坐标轴的选择和第一个坐标轴正交且具有最大方差的方向。该过程一直重复,重复次数为原始数据中特征的数目。我们会发现,大部分方差都包含在最前面的几个新坐标轴中。因此,我们可以忽略余下的坐标轴,即对数据进行了降维处理。
工作原理:
①找出第一个主成分的方向,也就是数据 方差最大 的方向。
②找出第二个主成分的方向,也就是数据 方差次大 的方向,并且该方向与第一个主成分方向正交(果是二维空间就叫垂直)。
③通过这种方式计算出所有的主成分方向。
④通过数据集的协方差矩阵及其特征值分析,我们就可以得到这些主成分的值。
⑤一旦得到了协方差矩阵的特征值和特征向量,我们就可以保留最大的 N 个特征。这些特征向量也给出了 N 个最重要特征的真实结构,我们就可以通过将数据乘上这 N 个特征向量 从而将它转换到新的空间上。
二.PCA在NumPy中的实现
def loadDataSet(fileName, delim='\t') :
fr = open(fileName)
stringArr = [line.strip().split(delim) for line in fr.readlines()]
dataArr = [map(float, line) for line in stringArr]
return mat(dataArr) # dataMat: 用于进行PCA操作的数据集
# topNfeat: 可选参数,即应用的N个特征。
# 若不指定topNfeat的值,那么函数就会返回前9999999个特征,或者原始数据中的全部特征
def pca(dataMat, topNfeat=9999999) :
# 计算平均值
meanVals = mean(dataMat, axis=0)
# 减去原始数据的平均值
meanRemoved = dataMat - meanVals
# 计算协方差矩阵及其特征值
covMat = cov(meanRemoved, rowvar=0)
eigVals, eigVects = linalg.eig(mat(covMat))
# 利用argsort()函数对特征值进行从小到大的排序,根据特征值排序结果的逆序就可以得到
# topNfeat个最大的特征向量
eigValInd = argsort(eigVals)
eigValInd = eigValInd[:-(topNfeat+1):-1]
# 这些特征向量将构成后面对数据进行转换的矩阵,该矩阵则利用N个特征将原始数据转换到新空间中
redEigVects = eigVects[:, eigValInd]
lowDDataMat = meanRemoved * redEigVects
reconMat = (lowDDataMat * redEigVects.T) + meanVals
return lowDDataMat, reconMat
注意:与python2有点不同,python3要加list
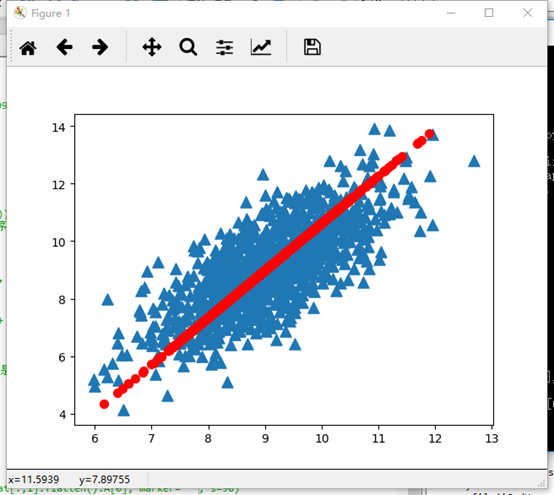
>>> dataMat = pca.loadDataSet('testSet.txt')
>>> lowDMat, reconMat = pca.pca(dataMat, 1)
>>> import numpy
>>> numpy.shape(lowDMat)
(1000, 1)
>>> import matplotlib
>>> import matplotlib.pyplot as plt
>>> fig = plt.figure()
>>> ax = fig.add_subplot(111)
>>> ax.scatter(dataMat[:,0].flatten().A[0], dataMat[:,1].flatten().A[0], marker='^', s=90)
<matplotlib.collections.PathCollection object at 0x000002449DCFA2B0>
>>> ax.scatter(reconMat[:,0].flatten().A[0], reconMat[:,1].flatten().A[0], marker='o', s=50, c='red')
<matplotlib.collections.PathCollection object at 0x000002449DCFABE0>
>>> plt.show()
得到如图
三.利用PCA对半导体制造数据降维
def replaceNaNWithMean():
#解析数据
datMat=loadDataSet('secom.data',' ')
#获取特征维度
numFeat=shape(datMat)[1]
#遍历数据集每一个维度
for i in range(numFeat):
#利用该维度所有非NaN特征求取均值
meanVal=mean(datMat[nonzero(~isnan(datMat[:,i].A))[0],i])
#将该维度中所有NaN特征全部用均值替换
datMat[nonzero(isnan(datMat[:,i].A))[0],i]=meanVal
return datMat dataMat=replaceNaNWithMean()
meanVals=mean(dataMat,axis=0)
meanRemoved=dataMat-meanVals
conMat=cov(meanRemoved,rowvar=0)
eigVals,eigVects=linalg.eig(mat(covMat))
eigVects
结果出现错误
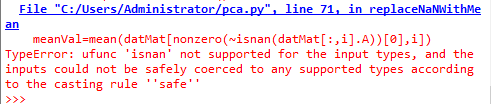
错误有待解决,也希望知道原因的小伙伴能告知一下,非常感谢
利用主成分分析(PCA)简化数据的更多相关文章
- 机器学习实战(Machine Learning in Action)学习笔记————09.利用PCA简化数据
机器学习实战(Machine Learning in Action)学习笔记————09.利用PCA简化数据 关键字:PCA.主成分分析.降维作者:米仓山下时间:2018-11-15机器学习实战(Ma ...
- 机器学习实战 - 读书笔记(13) - 利用PCA来简化数据
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习心得,这次是第13章 - 利用PCA来简化数据. 这里介绍,机器学习中的降维技术,可简化样品数据. ...
- 【机器学习实战】第13章 利用 PCA 来简化数据
第13章 利用 PCA 来简化数据 降维技术 场景 我们正通过电视观看体育比赛,在电视的显示器上有一个球. 显示器大概包含了100万像素点,而球则可能是由较少的像素点组成,例如说一千个像素点. 人们实 ...
- 《机器学习实战》学习笔记第十四章 —— 利用SVD简化数据
相关博客: 吴恩达机器学习笔记(八) —— 降维与主成分分析法(PCA) <机器学习实战>学习笔记第十三章 —— 利用PCA来简化数据 奇异值分解(SVD)原理与在降维中的应用 机器学习( ...
- 【机器学习实战】第14章 利用SVD简化数据
第14章 利用SVD简化数据 SVD 概述 奇异值分解(SVD, Singular Value Decomposition): 提取信息的一种方法,可以把 SVD 看成是从噪声数据中抽取相关特征.从生 ...
- 《机器学习实战》学习笔记——第14章 利用SVD简化数据
一. SVD 1. 基本概念: (1)定义:提取信息的方法:奇异值分解Singular Value Decomposition(SVD) (2)优点:简化数据, 去除噪声,提高算法的结果 (3)缺点: ...
- 机器学习实战 - 读书笔记(14) - 利用SVD简化数据
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习心得,这次是第14章 - 利用SVD简化数据. 这里介绍,机器学习中的降维技术,可简化样品数据. 基 ...
- 机器学习——利用SVD简化数据
奇异值分解(Singular Value Decompositon,SVD),可以实现用小得多的数据集来表示原始数据集. 优点:简化数据,取出噪声,提高算法的结果 缺点:数据的转换可能难以理解 适用数 ...
- SciKit-Learn 可视化数据:主成分分析(PCA)
## 保留版权所有,转帖注明出处 章节 SciKit-Learn 加载数据集 SciKit-Learn 数据集基本信息 SciKit-Learn 使用matplotlib可视化数据 SciKit-Le ...
随机推荐
- IntelliJ IDEA下"Cannot resolve symbol 'log'"的解决方法
转自:https://my.oschina.net/greatqing/blog/703989 最近接手了一个Maven项目,IDE使用的是IntelliJ IDEA,导入后可以编译运行.但是输出日志 ...
- dbms_stats应用相关
Q: DBMS_STATS.GATHER_SCHEMA_STATS ('schema_name'); 使用这个收集统计信息,estimate_percent使用默认值 ...
- June 25th 2017 Week 26th Sunday
There is always that one song that brings back old memories. 总有那么一首歌,让你想起那些旧的回忆. There are seveal so ...
- C# 解决组合优化问题
Google Optimization Tools介绍 Google Optimization Tools(OR-Tools)是一款专门快速而便携地解决组合优化问题的套件.它包含了: 约束编程求解器. ...
- [译] 怎样(以及为什么要)保持你的 Git 提交记录的整洁
最近在掘金翻译了一篇文章,主要讲的是 Git 提交记录的维护,确实很有用,感兴趣的同学可以去看一下.链接如下: [译] 怎样(以及为什么要)保持你的 Git 提交记录的整洁 截图:
- mysql中与 in 相反的语句 find_in_set('数据',字段名)
在 mysql 中,我们经常用 in 来查询众多数据中是否有数据表字段中的值: 如果我们在数据表的字段中添加了很多值,然后查询某个值是否是这个字段中众多值的一个时可以用 find_in_set('数据 ...
- Linux脚本开头#!/bin/bash和#!/bin/sh是什么意思以及区别
一.意思 #!/bin/sh是指此脚本使用/bin/sh来解释执行,#!是特殊的表示符,其后面根的是此解释此脚本的shell的路径. 其实第一句的#!是对脚本的解释器程序路径,脚本的内容是由解释器解释 ...
- PAT——1011. A+B和C
给定区间[-231, 231]内的3个整数A.B和C,请判断A+B是否大于C. 输入格式: 输入第1行给出正整数T(<=10),是测试用例的个数.随后给出T组测试用例,每组占一行,顺序给出A.B ...
- 利用SQL模糊匹配来验证字段是否是日期格式
最近需要验证数据仓库某个字段是否转化成某种日期格式,比如时间戳格式 ‘2016-05-03 23:21:35.0‘, 但是DB2不支持REGEXP_LIKE(匹配)函数,所以需要重新想其他办法. 最后 ...
- HDU 1009 FatMouse' Trade(简单贪心)
传送门: http://acm.hdu.edu.cn/showproblem.php?pid=1009 FatMouse' Trade Time Limit: 2000/1000 MS (Java/O ...