#研发解决方案#分布式并行计算调度和管理系统Summoner
- 为什么要做“数据”并行计算调度?
- 他山之玉:azkaban2/oozie/mesos
- Summoner的特性
0x00,为什么要做“数据”并行计算调度?
- 涉及到商户、门店、交易、折扣、核销物料等等,数据量很大,至少每天都要算一次,要算得快,
- 激励政策和佣金计算公式随着竞争态势变化,一般一两个月变一次,
- 数据抽取尽可能少影响正常业务,
- 计算逻辑调整后要能快速部署和运行。
- 人员组织架构
- 大区、区域和城市的对照关系
- 合同以及合同拥有者
- 商户和门店
- 门店下的收单交易
- 佣金计算公式、规则以及各种权重因子
- ……
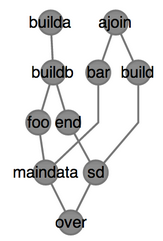

- 计算任务有步骤定义,输入输出都有灵活的定义,适合于数据收集、清洗、聚合、计算等各种常见计算场景;
- 步骤可以通过依赖关系来定义串行还是并行;
- 可以很直观地看到当前任务执行时跑到了哪一个步骤,或者哪些计算小任务;
- 如 oozie 的界面

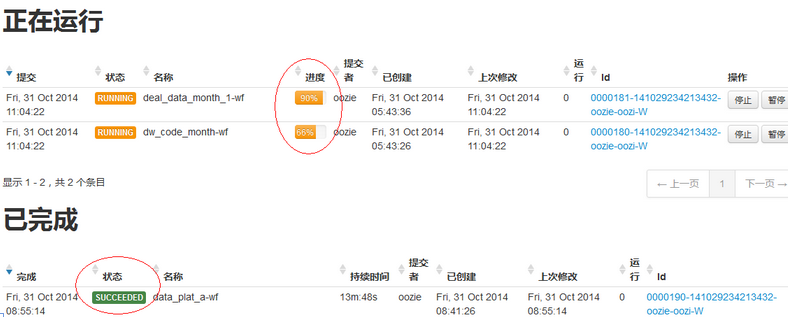
- 可以很直观地收集和展示当前任务里的输出流以及异常日志流;
- 可以很方便地暂停、终止、重启任务,无需担心遗留垃圾中间数据;
- 有报警机制,有一些简单指标展示;
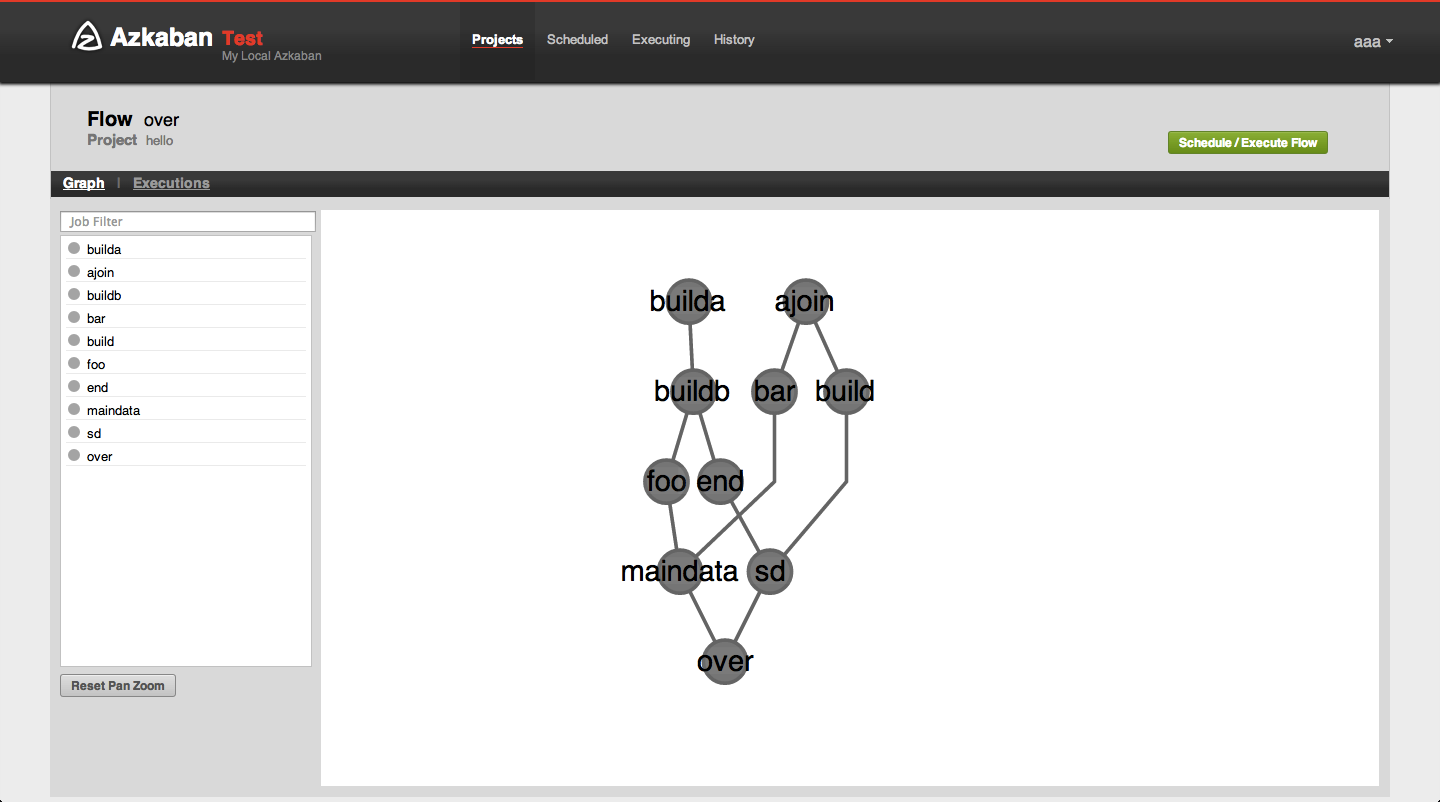
- 计算任务的步骤定义视觉化
- 如 azkaban2 的界面

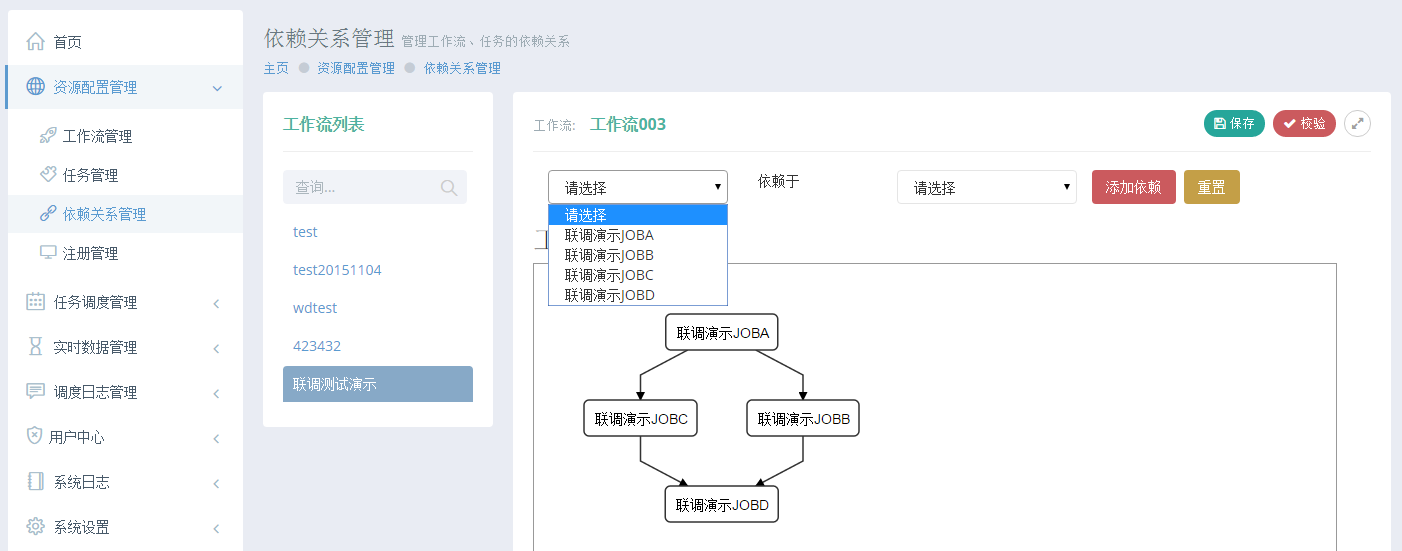
- 资源配置管理
- 工作流管理
- 任务管理
- 依赖关系管理
- 注册管理(客户端注册和服务器端注册)
- 任务调度管理
- 调度管理
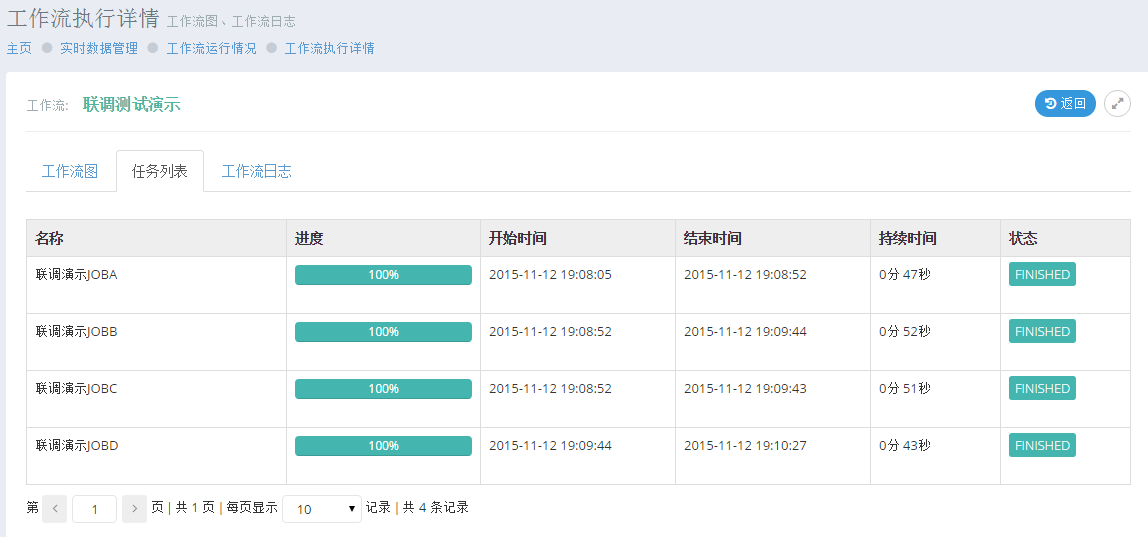
- 实时数据管理
- 工作流执行情况
- 调度日志管理
- 调度日志














- 内部Hybrid App经验解读
- iDB是如何运转的 一
- #研发解决方案#iDB-数据库自动化运维平台
- 容器私有云和持续发布都要解决哪些基础问题 第二集
- 容器私有云和持续发布都要解决哪些基础问题 第一集

#研发解决方案#分布式并行计算调度和管理系统Summoner的更多相关文章
- #研发解决方案介绍#Tracing(鹰眼)
郑昀 最后更新于2014/11/12 关键词:GoogleDapper.分布式跟踪.鹰眼.Tracing.HBase.HDFS. 本文档适用人员:研发 分布式系统为什么需要 Tracing? ...
- #研发解决方案介绍#IdCenter(内部统一认证系统)
郑昀 基于朱传志的设计文档 最后更新于2014/11/13 关键词:LDAP.认证.权限分配.IdCenter. 本文档适用人员:研发 曾经一个IT内部系统配一套帐号体系和授权 线上生产环境里 ...
- #研发解决方案介绍#基于StatsD+Graphite的智能监控解决方案
郑昀 基于李丹和刘奎的文档 创建于2014/12/5 关键词:监控.dashboard.PHP.graphite.statsd.whisper.carbon.grafana.influxdb.Pyth ...
- #研发解决方案介绍#基于ES的搜索+筛选+排序解决方案
郑昀 基于胡耀华和王超的设计文档 最后更新于2014/12/3 关键词:ElasticSearch.Lucene.solr.搜索.facet.高可用.可伸缩.mongodb.SearchHub.商品中 ...
- #研发解决方案介绍#Recsys-Evaluate(推荐评测)
郑昀 基于刘金鑫文档 最后更新于2014/12/1 关键词:recsys.推荐评测.Evaluation of Recommender System.piwik.flume.kafka.storm.r ...
- 利用 MessageRPC 和 ShareMemory 来实现 分布式并行计算
可以利用 MessageRPC + ShareMemory 来实现 分布式并行计算 . MessageRPC : https://www.cnblogs.com/KSongKing/p/945541 ...
- 分布式开源调度框架TBSchedule原理与应用
主要内容: 第一部分 TBSchedule基本概念及原理 1. 概念介绍 2. 工作原理 3. 源代码分析 4. 与其它开源调度框架对照 第二部分 TBSchedule分布式调度演示样例 1. TBS ...
- JAVA系统架构高并发解决方案 分布式缓存 分布式事务解决方案
JAVA系统架构高并发解决方案 分布式缓存 分布式事务解决方案
- #研发解决方案#discache-分布式缓存查询与管理系统
郑昀 基于马海元和闫小波的文档 关键词:memcached.redis.分布式缓存.控制台.反序列化.Java 本文档适用人员:研发和运维员工 提纲: 如何查看缓存里的序列化数据? 批量删除来一个 监 ...
随机推荐
- 将本地项目提交到coding上托管
1: 注册coding并新建项目test2:在终端 cd 到要提交的项目 使用git init创建.git文件夹3:使用git pull <项目地址>https的那个4:git a ...
- CRUD查询
简单查询: 1.最简单的查询 select*form 表名; *查所有的列select*form info 2.查询指定列 select code,name form info 3.修改结果集的列名 ...
- Android二维码的生成,解析以及扫描功能
<1> 布局只有2个按钮,实现生成二维码和解析二维码 <Button android:layout_width="wrap_content" android:la ...
- C++11智能指针读书笔记;
智能指针是一个类对象,而非一个指针对象. 原始指针:通过new建立的*指针 智能指针:通过智能指针关键字(unique_ptr, shared_ptr ,weak_ptr)建立的指针 它的一种通用实现 ...
- mongoDB index introduction
索引为mongoDB的查询提供了有效的解决方案,如果没有索引,mongodb必须的扫描文档集中所有记录来match查询条件的记录.然而这些扫描是没有必要,而且每一次操作mongod进程会处理大量的数据 ...
- mysql 基础使用
mysql服务器本地root用户默认没有密码,使用 "mysql -u root -p" 即可登陆.linux本地用户可以以任意用户名登陆mysql,但是没有任何权限,没有意义.m ...
- 在win7环境下批量修改文件权限
在附件->命令提示符->右键->以管理员身份运行 进入你需要修改的文件位置,然后输入下面两条命令 takeown /f * /A /R icacls * /t /grant:r ev ...
- android 对话框 setMultiChoiceItems 设置 初始化勾选
只需要 设定第二个参数 boolean[] 值就好了
- [图像]判断图片是PNG还是JPG格式
typedef NS_ENUM(NSInteger, NSPUIImageType) { NSPUIImageType_JPEG, NSPUIImageType_PNG, NSPUIImageType ...
- 浅谈我对C#中抽象类与接口的理解
C#中的抽象类与接口有些相似,初学者很容易混淆,今天就让我来谈谈对二者的理解. 首先我们得明确二者的含义,分述如下: 如果一个类不与具体的事物相联系,而只是表达一种抽象的概念,仅仅是作为其派生类的一个 ...