10分钟入门spark
Spark是硅谷各大公司都在使用的当红炸子鸡,而且有愈来愈热的趋势,所以大家很有必要了解学习这门技术。本文其实是笔者深入浅出hadoop系列的第三篇,标题里把hadoop去掉了因为spark可以不依赖于Hadoop。Spark可以运行在多种持久化系统之上,比如HDFS, Amazon S3, Azure Storage, Cassandra, Kafka。把深入浅出去掉了是因为Spark功能实在太强大(Spark SQL, Spark Streaming, Spark GraphX, Spark MLlib),本文只能抛砖引玉帮大家节省时间入个门,打算以后分专题深入总结一下sql, graph, streaming和machine learning方面的应用。
Spark History
- 2009 project started at UC berkeley's AMP lab
- 2012 first release (0.5)
- 2014 became top level apache project
- 2014 1.0
- 2015 1.5
- 2016 2.0
Spark 起源
map reduce以及之前系统存在的问题
- cluster memory 没有被有效运用
- map reduce重复冗余使用disk I/O,比如前一个job的output存在硬盘中,然后作为下一个job的input,这部分disk I/O如果都在内存中是可以被节省下来的。这一点在ad hoc query上尤为突出,会产生大量的中间文件,而且completion time比中间文件的durability要更为重要。
- map reduce的job要不停重复的做join,算法写起来要不停的tuning很蛋疼。
- 没有一个一站式解决方案,往往需要好几个系统比如mapreduce用来做batch processing,storm用来做stream processing,elastic search用来做交互式exploration。这就造成了冗余的data copy。
- interactive query和stream processing的需求越来越大,比如需要ad hoc analytics和快速的decision-making
- machine learning的需求越来越多
spark的破解方案
- RDD abstraction with rich API
- 充分使用内存
- 一站式提供Spark SQL, Spark Streaming, Spark GraphX, Spark MLlib
spark 架构
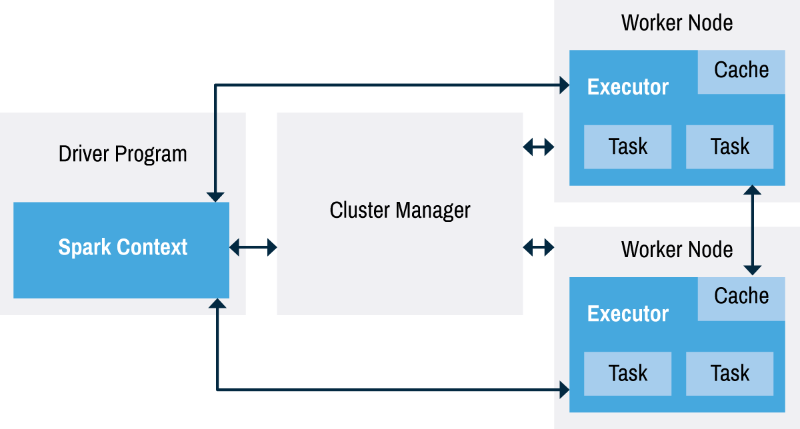
cluster manager: manage to execute tasks could be spark's standalone cluster manager, YARN(参见我之前讲mapreduce的文章) or Mesos。可以用来track当前可用的资源。
Spark applications包括driver process和若干executor processes。driver process是整个spark app的核心,运行main() function, 维护spark application的信息,响应用户输入,分析,distribute并且schedule work across executors。executors用来执行driver分配给它们的task,并把computation state report back to driver。
pyspark 安装
最简单的方式就是在如下地址下载tar包:
https://spark.apache.org/downloads.html
命令行运行:
$ export PYSPARK_PYTHON=python3
$ ./bin/pyspark
Python 3.6.4 (default, Jan 6 2018, 11:51:15)
[GCC 4.2.1 Compatible Apple LLVM 9.0.0 (clang-900.0.39.2)] on darwin
。。。
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.2.1
/_/ Using Python version 3.6.4 (default, Jan 6 2018 11:51:15)
SparkSession available as 'spark'.
setup:
python setup.py install
导入
from pyspark import SparkConf, SparkContext
RDDs (Resilient Distributed Datasets)
- Resilient: able to withstand failures
- Distributed: spanning across multiple machines
- read-only, partitioned collection of records
RDD 在最新的spark2.x中有逐渐被淡化的趋势,是曾经的主角,现在算作low level API,基本不太可能在生产实践中用到,但是有助于理解spark。新型的RDD需要实现如下接口
- partitions()
- iterator(p: Partition)
- dependencies()
- optional: partitioner for key-value RDD (E.g. RDD is hash-partitioned)
从local collection中创建RDD
>>> mycollection = "Spark Qing Ge Guide : Big Data Processing Made Simple".split(" ")
>>> words = spark.sparkContext.parallelize(mycollection, 2)
>>> words.setName("myWords")
myWords ParallelCollectionRDD[35] at parallelize at PythonRDD.scala:489
>>> words.name()
'myWords'
transformations
distinct:
>>> words.distinct().count()
[Stage 23:> (0 + 0) / 2]
10
filter:
>>> words.filter(lambda word: startsWithS(word)).collect()
['Spark', 'Simple']
map:
>>> words2 = words.map(lambda word: (word, word[0], word.startswith("S")))
>>> words2.filter(lambda record: record[2]).take(5)
[('Spark', 'S', True), ('Simple', 'S', True)]
flatmap:
>>> words.flatMap(lambda word: list(word)).take(5)
['S', 'p', 'a', 'r', 'k']
sort:
>>> words.sortBy(lambda word: len(word) * -1).take(5)
['Processing', 'Simple', 'Spark', 'Guide', 'Qing']
Actions
reduce:
>>> spark.sparkContext.parallelize(range(1,21)).reduce(lambda x, y : x+y)
210
count:
>>> words.count()
10
first:
>>> words.first()
'Spark'
max and min:
>>> spark.sparkContext.parallelize(range(1,21)).max()
20
>>> spark.sparkContext.parallelize(range(1,21)).min()
1
take:
>>> words.take(5)
['Spark', 'Qing', 'Ge', 'Guide', ':']
注意:spark uses lazy transformation, 上文提到的所有transformation都只有在action时才会被调用。
Saving files
>>> words.saveAsTextFile("file:/tmp/words")
$ ls /tmp/words/
_SUCCESS part-00000 part-00001
$ cat /tmp/words/part-00000
Spark
Qing
Ge
Guide
:
$ cat /tmp/words/part-00001
Big
Data
Processing
Made
Simple
Caching
>>> words.cache()
myWords ParallelCollectionRDD[35] at parallelize at PythonRDD.scala:489
options include: memory only(default), disk only, both
CoGroups
>>> import random
>>> distinctChars = words.flatMap(lambda word: word.lower()).distinct()
>>> charRDD = distinctChars.map(lambda c: (c, random.random()))
>>> charRDD2 = distinctChars.map(lambda c: (c, random.random()))
>>> charRDD.cogroup(charRDD2).take(5)
[('s', (<pyspark.resultiterable.ResultIterable object at 0x10ab49c88>, <pyspark.resultiterable.ResultIterable object at 0x10ab49080>)), ('p', (<pyspark.resultiterable.ResultIterable object at 0x10ab49438>, <pyspark.resultiterable.ResultIterable object at 0x10ab49048>)), ('r', (<pyspark.resultiterable.ResultIterable object at 0x10ab494a8>, <pyspark.resultiterable.ResultIterable object at 0x10ab495c0>)), ('i', (<pyspark.resultiterable.ResultIterable object at 0x10ab49588>, <pyspark.resultiterable.ResultIterable object at 0x10ab49ef0>)), ('g', (<pyspark.resultiterable.ResultIterable object at 0x10ab49ac8>, <pyspark.resultiterable.ResultIterable object at 0x10ab49da0>))]
Inner Join
>>> keyedChars = distinctChars.map(lambda c: (c, random.random()))
>>> outputPartitions = 10
>>> chars = words.flatMap(lambda word: word.lower())
>>> KVcharacters = chars.map(lambda letter: (letter, 1))
>>> KVcharacters.join(keyedChars).count()
44
>>> KVcharacters.join(keyedChars, outputPartitions).count()
44
Aggregations
from functools import reduce
>>> def addFunc(left, right):
... return left + right
...
KVcharacters.groupByKey().map(lambda row: (row[0], reduce(addFunc, row[1]))).collect()
[('s', 4), ('p', 3), ('r', 2), ('i', 5), ('g', 5), ('d', 3), ('b', 1), ('c', 1), ('l', 1), ('a', 4), ('k', 1), ('q', 1), ('n', 2), ('e', 5), ('u', 1), (':', 1), ('t', 1), ('o', 1), ('m', 2)]
Spark 执行和调度
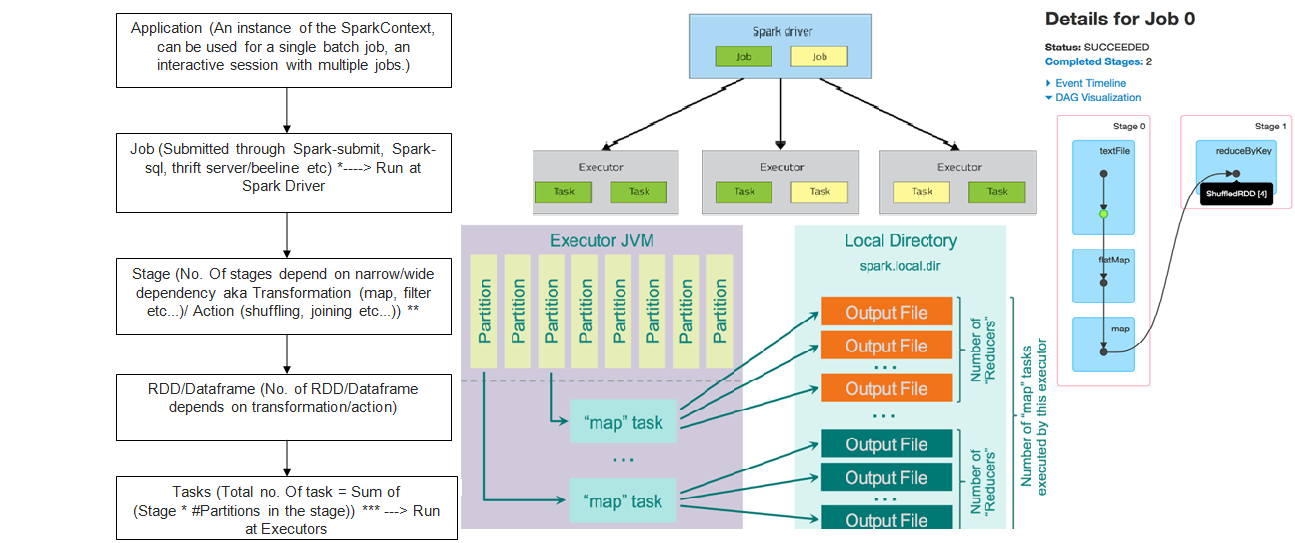
具体来说就是
- invoke an action...
- ...spawns the job...
- ...that gets divided into the stages by the job scheduler...
- ...and tasks are created for every job stage
其中,stage和task的区别在于:stage是RDD level,不会被立即执行,而task会被立即执行。
Broadcast variables
- read-only shared variables with effective sharing mechanism
- useful to share dictionaries and models
今天就先到这,更多内容以后有机会再聊
10分钟入门spark的更多相关文章
- Apache Shiro系列三,概述 —— 10分钟入门
一.介绍 看完这个10分钟入门之后,你就知道如何在你的应用程序中引入和使用Shiro.以后你再在自己的应用程序中使用Shiro,也应该可以在10分钟内搞定. 二.概述 关于Shiro的废话就不多说了 ...
- JavaScript 10分钟入门
JavaScript 10分钟入门 随着公司内部技术分享(JS进阶)投票的失利,先译一篇不错的JS入门博文,方便不太了解JS的童鞋快速学习和掌握这门神奇的语言. 以下为译文,原文地址:http://w ...
- kafka原理和实践(一)原理:10分钟入门
系列目录 kafka原理和实践(一)原理:10分钟入门 kafka原理和实践(二)spring-kafka简单实践 kafka原理和实践(三)spring-kafka生产者源码 kafka原理和实践( ...
- Markdown - Typora 10分钟入门 - 精简归纳
Markdown - Typora 10分钟入门 - 精简归纳 JERRY_Z. ~ 2020 / 8 / 22 转载请注明出处! 目录 Markdown - Typora 10分钟入门 - 精简归纳 ...
- [入门到吐槽系列] Webix 10分钟入门 一 管理后台制作
前言 本人是服务端程序员,同时需要兼职前端开发.常用的就是原生态的HTML.Javascript,也用过ExtJS.Layui.可是ExtJS变公司后非常难用.Layui上手还行,用过一段时间,会觉得 ...
- [入门到吐槽系列] Webix 10分钟入门 二 表单Form的使用
前言 继续接着上一篇的webix入门:https://www.cnblogs.com/zc22/p/15912342.html.今天完成剩下两个最重要的控件,表单和表格的使用.掌握了这两个,整个Web ...
- Webpack 10分钟入门
可以说现在但凡开发Single page application,webpack是一个不可或缺的工具. WebPack可以看做是一个模块加工器,如上图所示.它做的事情是,接受一些输入,经过加工产生一些 ...
- 「从零单排canal 01」 canal 10分钟入门(基于1.1.4版本)
1.简介 canal [kə'næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据 订阅 和 消费.应该是阿里云DTS(Data Transfer Servi ...
- python 10分钟入门pandas
本文是对pandas官方网站上<10 Minutes to pandas>的一个简单的翻译,原文在这里.这篇文章是对pandas的一个简单的介绍,详细的介绍请参考:Cookbook .习惯 ...
随机推荐
- 用CSS写气泡
新学到的一个小效果 用CSS实现如下图效果,其中demo结构为:<div id="square"></div> 实现这个效果需要用到两个知识点: 1.用bo ...
- PHP面试题超强总结(PHP中文网)
PHP面试基础题目 1.双引号和单引号的区别 双引号解释变量,单引号不解释变量 双引号里插入单引号,其中单引号里如果有变量的话,变量解释 双引号的变量名后面必须要有一个非数字.字母.下划线的特殊字符, ...
- zabbix邮件发送3.2.4
使用邮件服务发送,一般linux有两种发送方式 mail跟sendmail两款软件,我试验的时候总是会发生发送不了邮件的问题 简而便之,我两款软件都安装了,只要安装其中之一就ok了 #yum -y i ...
- 【转】12 TOP Command Examples in Linux
12个top命令 1. # top 2. # top,后输入shift+O,在“Current Sort Field:”中选左边的field对应的字母进行排序. 3. # top -u tecmint ...
- scala 小结(一)
Scala 是什么?(What is scala?) 引用百度百科对于scala的定义: Scala是一门多范式的编程语言,一种类似java的编程语言,设计初衷是实现可伸缩的语言.并集成面向对象编 ...
- Round trip 流程图
更多原创测试技术文章同步更新到微信公众号 :三国测,敬请扫码关注个人的微信号,感谢!
- iOS设备唯一标识的前世今生
设备唯一标识 估计很多开发都有被要求过获取一下设备的唯一标识,获取设备的唯一标识经常使用在我们做统计或者是在保证一台设备登录亦或者是做IM的时候可能会考虑去使用它,这一次在自己的需求当中就有一个&qu ...
- Linux tail,cat,head命令
tail命令用于将文件的最后部分输出到标准设备,通常是终端,也可以支持更新操作,当文档内容发生变化时,tail会自己主动刷新,确保你看到最新的档案内容. 1.tail -f filename 监视fi ...
- 洛谷 P3674 小清新人渣的本愿 [莫队 bitset]
传送门 题意: 给你一个序列a,长度为n,有Q次操作,每次询问一个区间是否可以选出两个数它们的差为x,或者询问一个区间是否可以选出两个数它们的和为x,或者询问一个区间是否可以选出两个数它们的乘积为x ...
- C语言实现数据结构中的堆创建,堆排序
#include "stdio.h"#include "stdlib.h"void swap(int *a,int *b)//交换两个数{int t;t=*a; ...