zookeeper 入门系列-理论基础 – zab 协议
上一章讨论了paxos算法,把paxos推到一个很高的位置。但是,paxos有没有什么问题呢?实际上,paxos还是有其自身的缺点的:
1. 活锁问题。在base-paxos算法中,不存在leader这样的角色,于是存在这样一种情况,即P1提交了一个proposal n1并且通过了prepare阶段;此时P2提交了一个proposal n2(n2>n1)并且也通过了prepare阶段;P1在commit时因为已经通过了n2而被拒绝;于是P1继续提交一个proposal n3并且通过prepare阶段;巧的是此时P2开始commit了,由于n2<n3再次被拒绝……如此循环往复。这种情况被称为活锁。即整个系统都没死,但由于互相请求资源而被互相锁死。为了不发生活锁的情况,最简单的方式当然是缩减proposer到一个,这样就不会发生互相请求锁死的情况,也即退化。事实上很多后来的工业级协议,都是paxos协议的退化或者变种。
2. 复杂度问题。base-paxos协议中还存在这样那样的问题,于是各种变种paxos出现了,比如为了解决活锁问题,出现了multi-paxos;为了解决通信次数较多的问题,出现了fast-paxos;为了尽量减少冲突,出现了epaxos。可以看到,工业级实现需要考虑更多的方面,诸如性能,异常等等。这也是为啥许多分布式的一致性框架并非真正基于paxos来实现的原因。
3. 全序问题。对于paxos算法来说,不能保证两次提交最终的顺序,而zookeeper需要做到这点,可以参考文献1。
For high-performance, it is important that
ZooKeeper can handle multiple outstanding state changes requested by the client and
that a prefix of operations submitted concurrently are committed according to FIFO
order.
基于以上这些原因,zookeeper并没有用paxos作为自己实现的协议,取而代之采用了一种称为zab的协议,全称是zookeeper atomic broadcast。下面简单介绍一下zab协议。
上面说过了,paxos存在活锁问题,为了解决活锁问题,zab引入了leader,但是单leader就是赤裸裸的单点问题,如何解决这个单点呢?
paxos采用的方法是leader选举(没有采用主备,因为主备过于固定,不够分布式)。leader选举就必然出现状态不一致的情况,于是就有着同步这样的过程。
zab协议分为4个阶段,即阶段0为leader选举,阶段1为发现,阶段2为同步,阶段3为广播。而实际实现时将发现及同步阶段合并为一个恢复阶段。
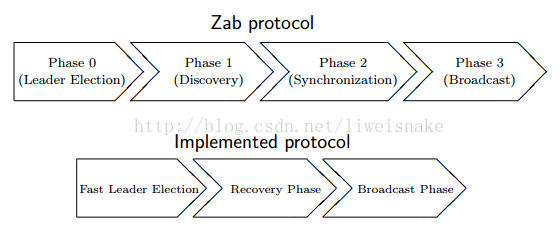
0. leader选举阶段。当集群中没有leader或者其他人感受不到leader时会进入这一阶段,这一阶段的主要目的是选出zxid最大的节点作为准leader。
1. recovery阶段。本阶段的主要目的是根据准leader的情况将数据同步到其他节点。同步完成后准leader变为leader。
2. broadcast阶段。本阶段的主要目的是leader收到请求,并将请求转为proposal,其他节点根据协议进行批准或通过。broadcast阶段事实上就是一个两阶段提交的简化版。其所有过程都跟两阶段提交一致,唯一不一致的是不能做事务的回滚。
广播的过程实际上类似于二阶段提交,但是如果实现完整的两阶段提交,那就解决了一致性问题,没必要发明新协议了,所以zab实际上抛弃了两阶段提交的事务回滚,于是一台follower只能回复ACK或者干脆就不回复了,leader只要收到过半的机器回复即通过proposal。但是这样的设计就存在很多问题,比如如果一个follower因为网络问题从头到尾一直没收到过leader的proposal,后续的询问刚好落到这台follower上该如何处理?比如leader第一阶段收到了所有follower的ACK后提交,然后通知其他follower提交,这时自己挂了该如何处理?于是诞生了崩溃恢复阶段,旨在对各种不一致情况做出恢复和处理。
对于选举和恢复阶段。zab算法需要确保两件事。
1. 已经处理过的proposal不能被丢弃。
发生场景:leader发送了proposal,follower1和follower2回复了ACK给leader,leader向所有follower发送commit请求并commit自身,此时leader挂了。leader已经提交,但是follower尚未提交,这会存在不一致的情况。
确保方式:
a. 重新选举leader时只挑选zxid最大的follower。因为至少半数的follower曾今回复ACK,意味着重新选举时zxid最大的follower应该是当初回复ACK但尚未提交的其中一台。
b. 该follower即准leader,将自身收到prepare但尚未提交的proposal提交
c. 在选举阶段准leader已经能拿到其余follower的所有事务集合,于是准leader根据各个follower的事务执行情况,分别建立队列,先发送prepare请求,再发送commit请求,让所有follower都同步到与leader一样的状态。
通过以上方式,能够确保提交过的proposal不会出现丢弃的情况。
2. 已经丢弃的proposal不能被重复处理。
发生场景:leader收到请求,包装为proposal,此时网络挂了或者leader挂了导致其他follower没收到请求,此时进入崩溃恢复阶段,此时其他follower选主并成功之后这个挂了 的leader以follower的身份加入,此时它有一个多余的proposal,与其他节点不一致。
确保方式:
通过zxid的大小能够直接确定。zxid的编码方式为高32位为epoch(即纪元,可以理解为代),低32位为每个proposal顺序递增的数字。每次变换一个leader,则epoch加一,可以理解为改朝换代了,这样,新朝代的zxid必然比旧朝代的zxid大,新代的leader可以要求将旧朝代的proposal清除。
可以考虑一下,如果leader在崩溃恢复阶段就满血复活了,此时集群的情况是什么样的。
参考文献:
- ZooKeeper’s atomic broadcast protocol:Theory and practice http://www.tcs.hut.fi/Studies/T-79.5001/reports/2012-deSouzaMedeiros.pdf
- Zab:Zookeeper 中的分布式一致性协议介绍 http://www.jianshu.com/p/fb527a64deee
- Zookeeper ZAB 协议分析 http://blog.xiaohansong.com/2016/08/25/zab/
- Zab协议 http://www.cnblogs.com/sunddenly/articles/4073157.html
- ZAB协议和Paxos算法 http://codingo.xyz/index.PHP/2016/12/27/zab_paxos/
- ZooKeeper之ZAB协议 http://www.solinx.co/archives/435
- Zab vs. Paxos https://cwiki.apache.org/confluence/display/ZooKeeper/Zab+vs.+Paxos
- ZooKeeper学习第七期–ZooKeeper一致性原理 http://www.cnblogs.com/sunddenly/p/4138580.html
- 分布式系统理论进阶 – Raft、Zab http://www.cnblogs.com/bangerlee/p/5991417.html
zookeeper 入门系列-理论基础 – zab 协议的更多相关文章
- Zookeeper概念学习系列之zab协议
不多说,直接上干货! 上一章讨论了paxos算法,把paxos推到一个很高的位置. Zookeeper概念学习系列之paxos协议 但是,paxos有没有什么问题呢?实际上,paxos还是有其自身的缺 ...
- zookeeper入门系列:paxos协议
上一章讨论了一种强一致性的情况,即需要分布式事务来解决,本章我们来讨论一种最终一致的算法,paxos算法. paxos算法是由大牛lamport发明的,关于paxos算法有很多趣事.比如lamport ...
- Zookeeper应用场景和ZAB协议
Zookeeper应用场景 数据发布/订阅(配置中心) 我们平常的开发过程中,经常会碰到这样的需求:系统中需要一些通用的配置信息,如一些运行时的开关.前端需要展示的通知信息.数据库配置信息等等.这些需 ...
- zookeeper入门系列:概述
zookeeper可谓是目前使用最广泛的分布式组件了.其功能和职责单一,但却非常重要. 在现今这个年代,介绍zookeeper的书和文章可谓多如牛毛,本人不才,试图通过自己的理解来介绍zookeepe ...
- zookeeper入门系列讲解
zookeeper可谓是目前使用最广泛的分布式组件了.其功能和职责单一,但却非常重要. 在现今这个年代,介绍zookeeper的书和文章可谓多如牛毛,本人不才,试图通过自己的理解来介绍zooke ...
- Zookeeper学习笔记之 Zab协议(Zookeeper Atomic Broadcast)
Zab协议(Zookeeper Atomic Broadcast): 广播模式: Leader将所有更新(称为proposal),顺序发送给Follower 当Leader收到半数以上的Followe ...
- zookeeper入门系列 : 分布式事务
上一章我们了解了zookeeper到底是什么,这一章重点来看zookeeper当初到底面临什么问题?而zookeeper又是如何解决这些问题的? 实际上zookeeper主要就是解决分布式环境下的一致 ...
- Zookeeper概念学习系列之paxos协议
不多说,直接上干货! 前言 一种最终一致的算法,paxos算法. paxos算法是由大牛lamport发明的,关于paxos算法有很多趣事.比如lamport论文最初由故事描述来引入算法,以至于那班习 ...
- ZooKeeper之ZAB协议
ZooKeeper为高可用的一致性协调框架,自然的ZooKeeper也有着一致性算法的实现,ZooKeeper使用的是ZAB协议作为数据一致性的算法,ZAB(ZooKeeper Atomic Broa ...
随机推荐
- [SCOI2010]连续攻击游戏 匈牙利算法
觉得题目水的离开 不会匈牙利的请离开 不知道二分图的请离开 不屑的大佬请离开 ……. 感谢您贡献的访问量 ————————————华丽的分割线———————————— 扯淡完了,先重温一下题目 [SC ...
- [BZOJ1385] [Baltic2000] Division expression (数学)
Description 除法表达式有如下的形式: X1/X2/X3.../Xk 其中Xi是正整数且Xi<=1000000000(1<=i<=k,K<=10000) 除法表达式应 ...
- 【Chrome控制台】获取元素上绑定的事件信息以及监控事件
需求场景 在前端开发中,偶尔需要验证下某个元素上到底绑定了哪些事件,以及监控某个元素上的事件触发情况. 解决方案 普通操作 之前面对这种情况,一般采取的措施就是在各个事件里写console.info, ...
- 超文本传输协议 - HTTP / 1.1(Hypertext Transfer Protocol -- HTTP/1.1)之方法定义(Method Definitions)
9方法定义 下面定义了HTTP / 1.1的一组常用方法.尽管可以扩展这个集合,但是另外的方法不能假定为单独扩展的客户端和服务器共享相同的语义. 主机请求头域(14.23节)必须伴随所有的HTTP / ...
- mysql执行计划简介
介绍 本篇主要通过汇总网上的大牛的知识,简单介绍一下如何使用mysql的执行计划,并根据执行计划判断如何优化和是否索引最优. 执行计划可显示估计查询语句执行计划,从中可以分析查询的执行情况是否最优,有 ...
- IIS前端页面不显示详细错误解决方法
要想解决这个问题,有三种方法可以考虑: 1.Internet信息服务(IIS)管理器 2.Web.config文件 3. 命令行 在IIS的"错误页"右边的"编辑功能设置 ...
- JavaIO 总结
另外参考文章:http://www.ibm.com/developerworks/cn/java/j-lo-javaio/ 一. File类 file.createNewFile();file.del ...
- MySQL多数据源笔记5-ShardingJDBC实战
Sharding-JDBC集分库分表.读写分离.分布式主键.柔性事务和数据治理与一身,提供一站式的解决分布式关系型数据库的解决方案. 从2.x版本开始,Sharding-JDBC正式将包名.Maven ...
- READ TABLE 的用法
SORT ITAB BY '你想比较的列'. " 排序以增加二分查找的速度 READ TABLE itab with key 'itab中某列' = ‘目标列' BINARY SEARCH. ...
- 简单的 Promise 实现 一
const Promise = function(fn){ let state = { pending: "pending", fulfilled: "fulfilled ...