R语言-广义线性模型
使用场景:结果变量是类别型,二值变量和多分类变量,不满足正态分布
结果变量是计数型,并且他们的均值和方差都是相关的
解决方法:使用广义线性模型,它包含费正太因变量的分析
1.Logistics回归(因变量为类别型)
案例:匹配出发生婚外情的模型
1.查看数据集的统计信息
library(AER)
data(Affairs,package = 'AER')
summary(Affairs)
table(Affairs$affairs)
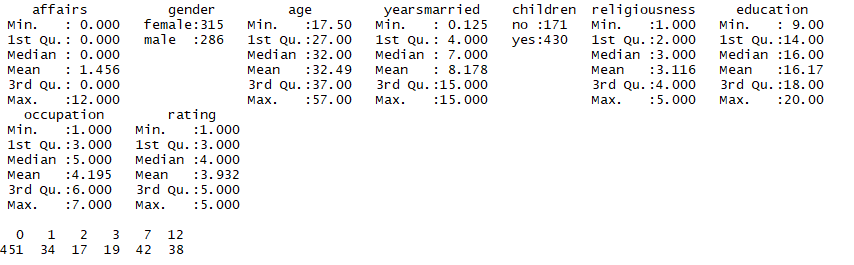
结果:该数据从601位参与者收集了,婚外情次数,性别,年龄,结婚年限,是否有孩子,宗教信仰,教育背景,职业,婚姻的自我评价这9个变量
结果变量是婚外情发生的次数72%的夫妻没有婚外情,最多的是一年中每月都有婚外情占6%
2.将结果值转换为二值型因子
Affairs$ynaffair[Affairs$affairs > 0] <- 1
Affairs$ynaffair[Affairs$affairs == 0] <- 0
Affairs$ynaffair <- factor(Affairs$ynaffair,
levels=c(0,1),
labels=c("No","Yes"))
table(Affairs$ynaffair)
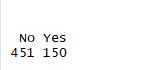
3.将该因子作为二值型变量的结果变量
fit.full <- glm(ynaffair ~ gender + age + yearsmarried + children +
religiousness + education + occupation +rating,
data=Affairs,family=binomial())
summary(fit.full)
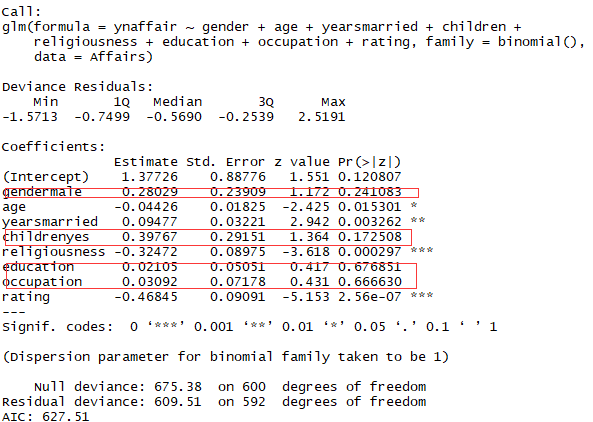
结果:性别,是否有孩子,学历和职业对模型不显著,去除后进行分析
fit.reduced <- glm(ynaffair ~ age + yearsmarried + religiousness +
rating, data=Affairs, family=binomial())
summary(fit.reduced)
3.使用卡方检验来判断比较
anova(fit.reduced,fit.full,test = 'Chisq')

结果:p=0.21,表示新模型的拟合更好
4.解释模型参数
coef(fit.reduced)
exp(coef(fit.reduced))

结果:婚龄每增加1岁,婚外情发生的可能性将乘以1.106,相反年龄增加1岁,婚外情发生的可能性乘以0.9652
5.评价婚姻评分对婚外情的影响
# 1.手动生成数据集
# 2.使用predict函数来进行预测
testdata <- data.frame(rating=c(1,2,3,4,5),age=mean(Affairs$age),
yearsmarried=mean(Affairs$yearsmarried),
religiousness=mean(Affairs$religiousness))
testdata
testdata$prob <- predict(fit.reduced,newdata = testdata,type='response')
testdata

结果:当婚姻评分从1(很不幸)变成5(很幸福)的时候,婚外情发生的概率从0.53降低到0.15
6.评价年龄对婚外情的影响
testdata <- data.frame(rating=mean(Affairs$rating),
age=seq(17,57,10),
yearsmarried=mean(Affairs$yearsmarried),
religiousness=mean(Affairs$religiousness))
testdata$prob <- predict(fit.reduced,newdata = testdata,type='response')
testdata

结果:当其他变量不变时,年龄从17到57岁,婚外情的概率从0.34降低到0.11
7.判断是否过度离势
过度离势会导致标准误检验和不精确的显著性检验,此时任然可以使用gml()拟合拟合Logistics回归,但是把二项分布改为类二项分布
# 如果结果接近1,表示没有过度离势
deviance(fit.reduced)/df.residual(fit.reduced)
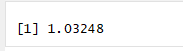
结果:没有过度离势
2.泊松回归(因变量为计数型)
使用场景:通过一系列连续型或类别型预测变量来预测计数型结果变量时采用泊松分布
案例:药物治疗是否能减小癫痫的发病数
1.查看数据集
data(breslow.dat,package = 'robust')
names(breslow.dat)
summary(breslow.dat[c(6,7,8,10)])
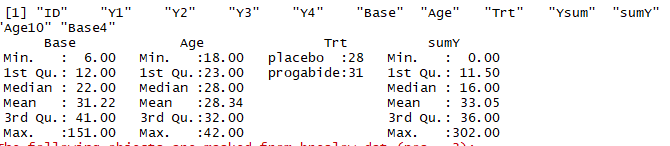
结果:我们分析年龄,治疗条件,前八周的发病次数和随机化后八周内的发病次数的关系,所以只采用4个变量
2.图形
opar <- par(no.readonly = T)
par(mfrow=c(1,2))
attach(breslow.dat)
hist(sumY,breaks = 20,xlab = 'Seizure Count',main = 'Distribution of Sizeture')
boxplot(sumY~Trt,xlab='Treatment',main='Group Comparisons')
par(opar)
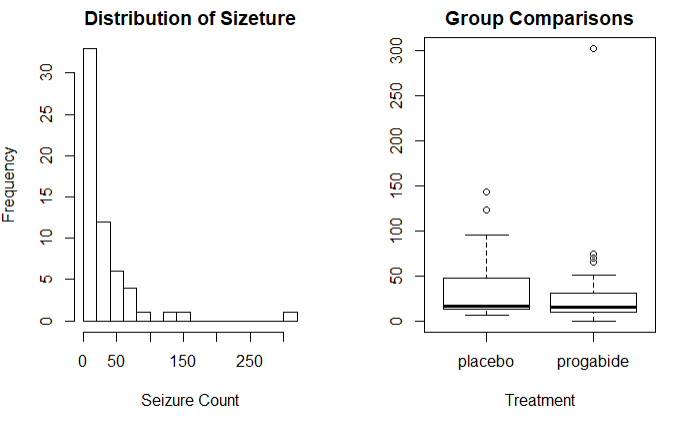
结果:可以看出使用药物的组,癫痫的发病率有所减少
3.拟合泊松回归
fit <- glm(sumY~Base+Age+Trt,data = breslow.dat,family = poisson())
summary(fit)
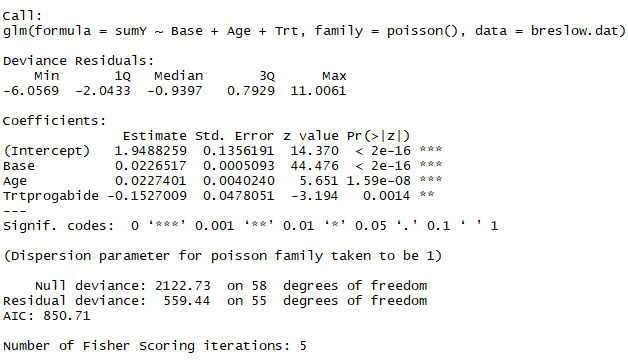
结果:偏差,回归参数,标准误差和参数为0的检验
4.解释模型参数
coef(fit)
exp(coef(fit))

结果:年龄每增加1岁,癫痫的发病数将乘以1.023,如果从安慰剂组调到药物组,则发病率会减少14%
5.判断是否过度离势
deviance(fit)/df.residual(fit)
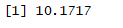
结果:大于1,存在过度离势
6.调整模型
fit.new <- glm(sumY~Base+Age+Trt,data = breslow.dat,family = quasipoisson())
summary(fit.new)
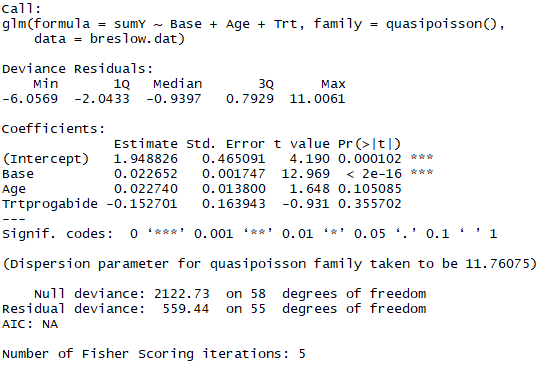
结果:标准误差和第一次模型相比,大了许多,同时标准误差越大会导致Trt的p值大于0.05,所以并没有充分的证据表明药物治疗相对于使用安慰剂能够降低癫痫的发病次数
R语言-广义线性模型的更多相关文章
- R语言实战(八)广义线性模型
本文对应<R语言实战>第13章:广义线性模型 广义线性模型扩展了线性模型的框架,包含了非正态因变量的分析. 两种流行模型:Logistic回归(因变量为类别型)和泊松回归(因变量为计数型) ...
- [读书笔记] R语言实战 (十三) 广义线性模型
广义线性模型扩展了线性模型的框架,它包含了非正态的因变量分析 广义线性模型拟合形式: $$g(\mu_\lambda) = \beta_0 + \sum_{j=1}^m\beta_jX_j$$ $g( ...
- R语言实现 广义加性模型 Generalized Additive Models(GAM) 入门
转载请说明. R语言官网:http://www.r-project.org/ R语言软件下载:http://ftp.ctex.org/mirrors/CRAN/ 注:下载时点击 ins ...
- 如何在R语言中使用Logistic回归模型
在日常学习或工作中经常会使用线性回归模型对某一事物进行预测,例如预测房价.身高.GDP.学生成绩等,发现这些被预测的变量都属于连续型变量.然而有些情况下,被预测变量可能是二元变量,即成功或失败.流失或 ...
- R语言 常见模型
转自 雪晴网 [R]如何确定最适合数据集的机器学习算法 抽查(Spot checking)机器学习算法是指如何找出最适合于给定数据集的算法模型.本文中我将介绍八个常用于抽查的机器学习算法,文中还包括各 ...
- R语言实战
教材目录 第一部分 入门 第一章 R语言介绍 第二章 创建数据集 第三章 图形初阶 第四章 基本数据管理 第五章 高级数据管理 第二部分 基本方法 第六章 基本图形 第七章 基本统计方法 第三部分 中 ...
- 数据分析与R语言
数据结构 创建向量和矩阵 函数c(), length(), mode(), rbind(), cbind() 求平均值,和,连乘,最值,方差,标准差 函数mean(), sum(), min(), m ...
- R语言实战(四)回归
本文对应<R语言实战>第8章:回归 回归是一个广义的概念,通指那些用一个或多个预测变量(也称自变量或解释变量)来预测响应变量(也称因变量.效标变量或结果变量)的方法.通常,回归分析可以用来 ...
- R语言实战(五)方差分析与功效分析
本文对应<R语言实战>第9章:方差分析:第10章:功效分析 ================================================================ ...
随机推荐
- Java客户端API
添加依赖 <dependency> <groupId>org.apache.zookeeper</groupId> <artifactId>zookee ...
- CGI,FAST-CGI,PHP-FPM的区别
http://blog.csdn.net/xsgnzb/article/details/52875331 CGI全称Common Gateway Interface即公共网关接口,它遵循cgi规范,定 ...
- 实现LNMP
实现LNMP 环境: linux系统机器 A:一台N:nginx,ip:192.168.213.251 B:一台P:php-fpm,php-mysql ,ip:192.168.213.253 C:一台 ...
- NSDate的常用用法
1. 创建或初始化可用以下方法 用于创建NSDate实例的类方法有 + (id)date; 返回当前时间 + (id)dateWithTimeIntervalSinceNow:(NSTimeInter ...
- C# WinForm程序退出的方法比较
1.this.Close(); 只是关闭当前窗口,若不是主窗体的话,是无法退出程序的,另外若有托管线程(非主线程),也无法干净地退出: 2.Application.Exit(); 强制所有消息中 ...
- java利用poi生成/读取excel表格
1.引入jar包依赖 <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi< ...
- Java并发系列[1]----AbstractQueuedSynchronizer源码分析之概要分析
学习Java并发编程不得不去了解一下java.util.concurrent这个包,这个包下面有许多我们经常用到的并发工具类,例如:ReentrantLock, CountDownLatch, Cyc ...
- 豹哥嵌入式讲堂:ARM知识概要杂辑(1)- 内核架构编年史
众所周知,ARM公司是一家微处理器行业的知名企业,ARM公司本身并不靠自有的设计来制造或出售CPU,而是将处理器架构授权给有兴趣的厂家.这些厂家基本涵盖了全球领先的知名半导体企业.软件和OEM厂商:T ...
- 【转】Linux Oracle服务启动&停止脚本与开机自启动
在CentOS 6.3下安装完Oracle 10g R2,重开机之后,你会发现Oracle没有自行启动,这是正常的,因为在Linux下安装Oracle的确不会自行启动,必须要自行设置相关参数,首先先介 ...
- 解析js中作用域、闭包——从一道经典的面试题开始
如何理解js中的作用域,闭包,私有变量,this对象概念呢? 就从一道经典的面试题开始吧! 题目:创建10个<a>标签,点击时候弹出相应的序号 先思考一下,再打开看看 //先思考一下你会怎 ...