Storm容错和高可用
Daemon Fault Tolerance
Storm有一些不同的守护进程
- Nimbus负责调度workers
- supervisors负责运行和杀死workers
- log views负责访问日志
- UI负责显示集群的状态
What happens when a worker dies?
当一个worker死了以后,supervisor将会重启它。如果在启动过程中不断的失败,并且不能发送心跳给Nimbus,那么Nimbus将重新调度这个worker。
What happens when a node dies?
分配到这台机器上的任务会超时,然后Nimbus将这些任务分给其它机器来做。
What happens when Nimbus or Supervisor daemons die?
Nimbus和Supervisor守护进程被设计成快速失败的(当遇到不期望发生的情况时进程会自杀)并且是无状态的(所有状态都保持在zookeeper或者磁盘上)。
Nimbus和Supervisor必须运行在被监督的状态下(PS:必须对它们进行监控)。因此,如果Nimbus或者Supervisor守护进程死了以后,它们会被立即重启,就好像什么事都发生一样。
尤其是,Nimbus或者Supervisors的死亡对于worker进程没有任何影响(PS:如果它们死了,没有worker会受到影响)。这跟Hadoop不一样,Hadoop中如果JobTracker死了,所有job都会丢失。
Is Nimbus a single point of failure?
如果你失去了Nimbus节点,worker仍然会正常工作。另外,如果worker死了,supervisor会重启它。然而,如果没有Nimbus,在某些情况下wokers不能被重新分配到其它机器上(比如:运行worker的机器挂了)。
自从1.0.0版本以后,Storm的Nimbus是高可用的。
Highly Available Nimbus Design
Problem Statement:
目前Storm master又叫做nimbus,nimbus是一个运行在单个机器上的受监督的进程。大多数情况下,nimbus失败是短暂的,并且它会被supervisor重启。然而,有时候当磁盘或者网络失败发生的时候,nimbus就死了。在这种情况下topologies会正常运行,但是不能提交新的topologies了。为了解决这些问题,我们采用主备模式运行nimbus以此保证即使一个nimbus失败了备用的那个可以接替它。
Leader Election(选举):
nimbus服务器用下面的接口:
public interface ILeaderElector {
/**
* queue up for leadership lock. The call returns immediately and the caller
* must check isLeader() to perform any leadership action.
*/
void addToLeaderLockQueue();
/**
* Removes the caller from the leader lock queue. If the caller is leader
* also releases the lock.
*/
void removeFromLeaderLockQueue();
/**
*
* @return true if the caller currently has the leader lock.
*/
boolean isLeader();
/**
*
* @return the current leader's address , throws exception if noone has has lock.
*/
InetSocketAddress getLeaderAddress();
/**
*
* @return list of current nimbus addresses, includes leader.
*/
List<InetSocketAddress> getAllNimbusAddresses();
}
在启动的时候,nimbus检查它本地是否有所有激活的topologies的code。一旦它得到这个检查的状态之后,它将调用addToLeaderLockQueue()方法。当一个nimbus被通知成为一个leader的时候,它会在假设自己是leadership角色之前再检查它是不是有所有的code。如果它缺少任何一个激活的topology的code,那么这个节点无法成为leadership角色,于是它将释放这个lock,在它为了获取leader lock之前它必须等待直到它获得了所有的code。
第一个实现是基于zookeeper的。如果zookeeper连接丢失或者被重置,造成的结果就是失去lock,这种实现关心的是isLeader()的状态变化。如果一个不是leader的nimbus收到一个请求,将抛异常。
下面的步骤描述了一个nimbus故障转移方案:假设,有4个topologies正在运行,3个nimbus结点,code-replication-factor = 2。我们假设“The leader nimbus has code for all topologies locally”在开始之前一直是true。非leader结点“nonleader-1”和“nonleader-2”各有2个topologies的code。假设Leader nimbus死了,硬盘坏了以至于没有恢复的可能。这个时候nonleader-1收到了zookeeper的通知表示它现在是新的leader,于是在接受成为leadership角色之前它检查它手上是不是有4个topologies(这些topologies在/storm/storms/目录下)的code。它意识到它只有2个topologies的code以至于它必须放弃lock,并且查看/storm/code-distributor/topologyId目录以找到从哪儿可以下载到它缺失的topologies。它发现从leader nimbus和nonleader-2那儿都可以。它尝试从这两个地方下载。nonleader-2也意识到它还缺2个topologies,并且按照之前相同的方法下载它所缺失的topologies。最终,它们当中至少有一个会获得所有的code,于是那个nimber将接收leadership成为新的leader。
下面的时序图描述的是leader选举和故障转移是如何进行的:
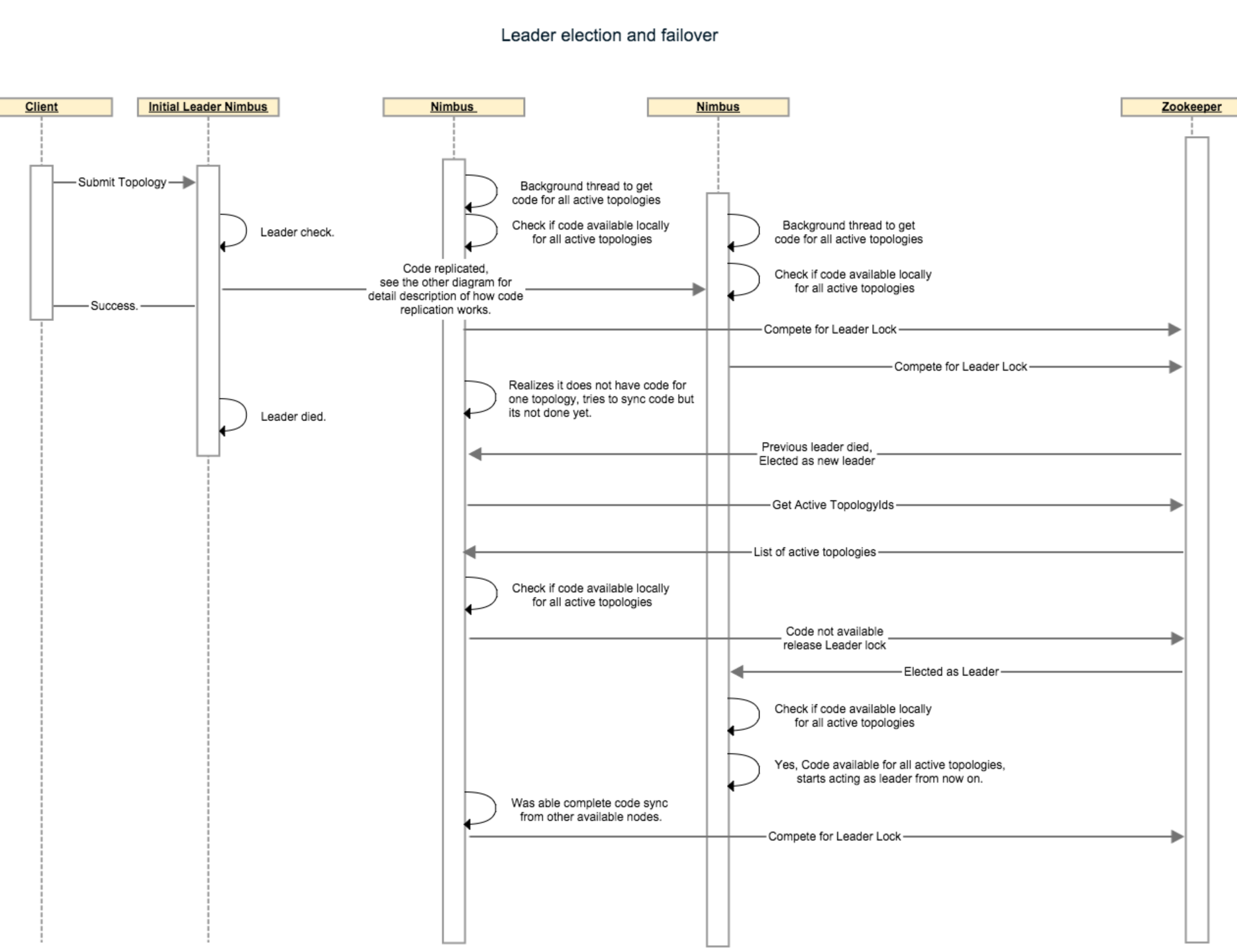
Nimbus state store:
目前,nimbus存储2种数据,一种是元数据(比如supervisor info、assignment info)被存储在zookeeper上,另一种是实际的topology配置和jars存储在nimbus所在的主机的本地磁盘上。
为了能够成功的故障转移从主切换到备,nimbus state/data需要被复制到所有的nimbus主机上或者需要被存储到一个分布式的存储设备上。正确的复制数据包含状态管理、一致性检查,并且即使不正确也很难测试出来。然而,许多storm用户不想额外的依赖像HDFS那种副本存储系统而且还想高可用。最终,我们想到用比特流协议来移动给定大小的代码分布,而且也是为了当supervisors数量很高的时候能获得更好的伸缩性。为了支持比特流和所有基于副本存储的文件系统,我们建议用下面的接口:
/**
* Interface responsible to distribute code in the cluster.
*/
public interface ICodeDistributor {
/**
* Prepare this code distributor.
* @param conf
*/
void prepare(Map conf); /**
* This API will perform the actual upload of the code to the distributed implementation.
* The API should return a Meta file which should have enough information for downloader
* so it can download the code e.g. for bittorrent it will be a torrent file, in case of something
* like HDFS or s3 it might have the actual directory or paths for files to be downloaded.
* @param dirPath local directory where all the code to be distributed exists.
* @param topologyId the topologyId for which the meta file needs to be created.
* @return metaFile
*/
File upload(Path dirPath, String topologyId); /**
* Given the topologyId and metafile, download the actual code and return the downloaded file's list.
* @param topologyid
* @param metafile
* @param destDirPath the folder where all the files will be downloaded.
* @return
*/
List<File> download(Path destDirPath, String topologyid, File metafile); /**
* Given the topologyId, returns number of hosts where the code has been replicated.
*/
int getReplicationCount(String topologyId); /**
* Performs the cleanup.
* @param topologyid
*/
void cleanup(String topologyid); /**
* Close this distributor.
* @param conf
*/
void close(Map conf);
}
为了支持复制,我们允许用户指定一个代码复制因子,这个复制因子表示在开始topologies之前代码必须被复制到多少个nimbus主机上。我们把zookeeper上维护的激活的topologies的列表作为我们的权力,表示这些topologies代码必须存在于nimbus主机上。任何一个没有在zookeeper上标记为active的所有的topologies代码的nimbus必须放弃它的lock,以至于其它的nimbus能够成为leader。在所有的nimbus主机上都有一个后台线程不断的尝试从其它的主机那里同步代码,所以只要还有一个种子主机上存在所有的active的topologies,那么最终至少有一个nimbus会变成leadership。
下面的步骤描述了对于一个topology在nimbus之间的代码复制过程:当客户端上传了一个jar文件,传就传了,什么也不会发生。而当客户端提交了一个topology的时候,leader nimbus调用code distributor(代码分发器)的upload函数,这将会在leader nimbus本地创建一个metafile文件。leader nimbus将在zookeeper上的/storm/code-distributor/topologyId目录下写一个新的入口,以此通知所有的非leader的nimbus它们应该下载这个新代码。在用户配置的超时时间内,客户端必须等待leader nimbus确保至少有N个非leader nimbus已经完成了代码复制。当一个非leader nimbus接收到关于这个新代码的通知的时候,它从leader nimbus那里下载这个meta file,并且通过调用代码分发器的download函数下载这个metafile所代表的真实的代码。一旦非leader nimbus完成了代码下载,这个非leader nimubs会向zk的 /storm/code-distributor/topologyId目录下写一个新的入口以此表明这是一个可以下载代码的metafile的位置,这样做是为了以防万一leader nimbus死了。然后leader nimbus继续做它该做的事情。
下面这个时序图描述了在代码分发过程中各个组件之间的通信:
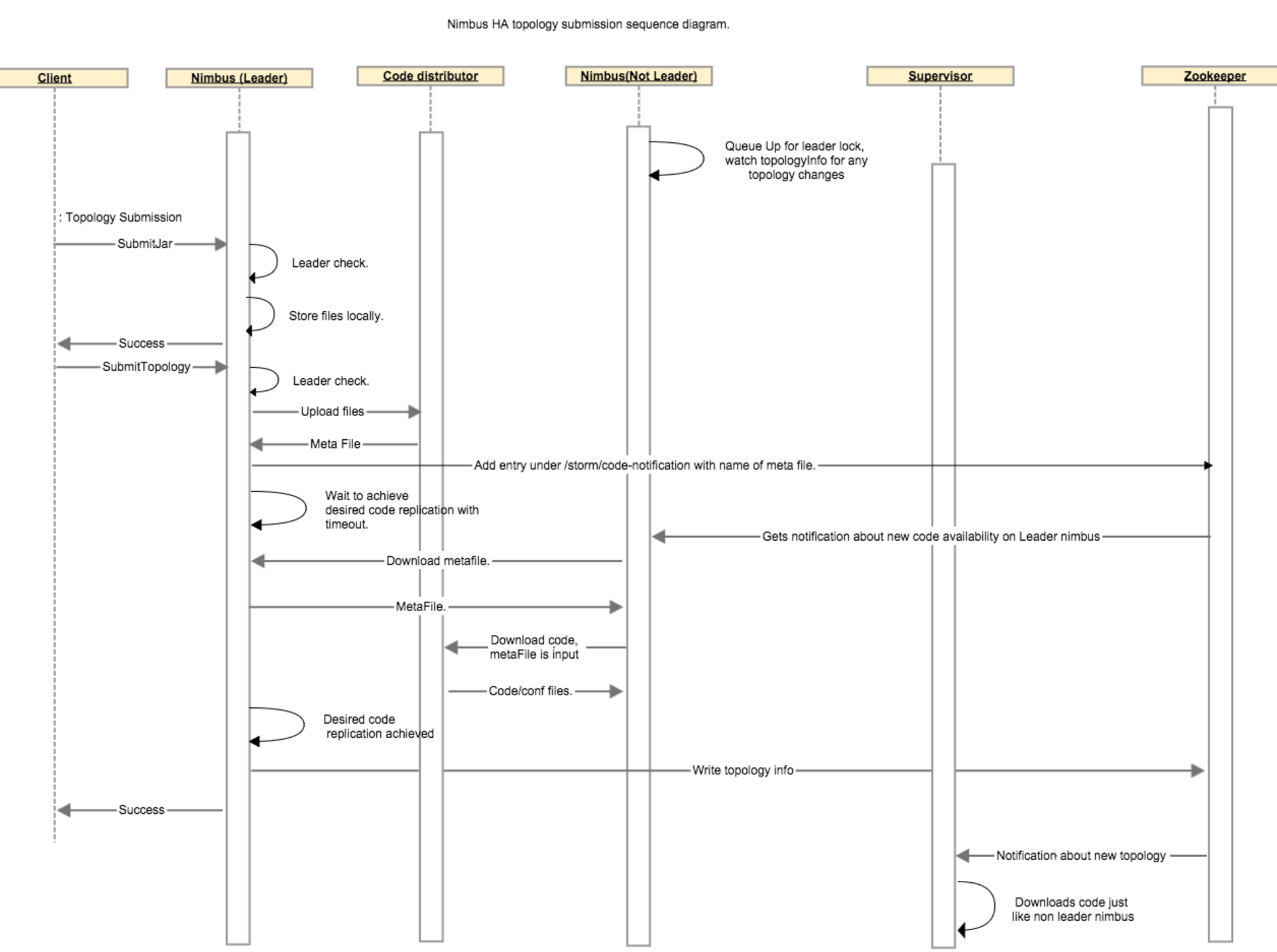
本节重点
守护进程容错
1、如果worker死了,那么supervisor会重启它,如果还是失败,则由nimbus重新指定机器运行它
2、如果worker所在的机器挂了,那么这台机器上的所有未完成的任务将分配给其它机器去执行
3、如果nimbus或者supervisor死了,它们会被快速重启,就好像什么都没发生一样
4、nimbus和supervisor必须有监控,它们必须运行在监督之下
5、nimbus或者supervisor死了对worker进程没有影响
高可用的Nimbus设计
1、Nimbus HA采用的是主备模式,主节点挂掉以后从节点会接替主节点
2、Nimbus存储两种类型的数据
- 元数据,包括supervisor info, assignment info(任务分配的信息)。这些信息保存在zookeeper中。
- 实际的topology配置和jars存储在nimbus主机的本地磁盘上
3、为了能够更好的故障转移,这些状态以及数据必须被复制到所有的nimbus上或者存到一个分布式的存储上。Storm内部使用的比特流协议来复制的。
4、用户自定义副本因子来决定代码必须被复制到多少个nimbus上
5、每个nimbus都有一个后台线程不断的尝试从其它主机那里同步代码
6、复制的流程如下:
(1)当leader nimbus收到一个客户端提交的topology时,它调用代码分发器的upload方法,这将在本地创建一个metafile来保存topology的元数据,紧接着zookeeper的/storm/code-distributor/topologyId目录下写一个新的数据,以此通知所有的nonleader nimbus它们应该下载这个新代码;
(2)客户端在提交这个topology以后一直处于等待状态,直到leader nimbus确保至少有N个non leader nimbus已经完成了代码复制,或者超时返回;
(3)当一个non leader nimbus收到这样一个通知以后,首先从leader nimbus那里下载metafile,然后下载真实的代码,这些都完成以后它会往/storm/code-distributor/topologyId再写一个入口以表明从它那里可以下载代码的metafile
7、leader选举是基于zookeeper实现的
8、选举的过程如下:
(1)nimbus在启动的时候检查自己本地是不是有所有的在zookeeper上标记为active状态的topologies的代码,如果没有则不能入队,有的话就调用addToLeaderLockQueue()函数以求获得leadership lock;
(2)当一个non leader nimbus被通知它可以成为新的leader的时候,这个nimbus会再次检查它本地是不是有所有的topologies的代码,如果是不是,那么它必须放弃lock,为了再次入队获得leadership lock它必须等待直到它收集到所有的代码;如果是的话,那么它将成为leader;
参考
http://storm.apache.org/releases/1.1.1/Daemon-Fault-Tolerance.html
http://storm.apache.org/releases/1.1.1/nimbus-ha-design.html
Storm容错和高可用的更多相关文章
- 使用Atlas进行元数据管理之容错和高可用
1. 介绍 Apache Atlas使用各种系统并与之交互,为数据管理员提供元数据管理和数据血缘信息.通过适当地选择和配置这些依赖关系,可以使用Atlas实现高度的服务可用性.本文档介绍了Atlas中 ...
- Storm集群开启HA高可用
Storm开启HA高可用,包括Nimbus和UI开启两个及以上的进程. 基于已经安装好的Storm集群,开启关键节点角色的HA高可用. Storm安装请参考Storm集群安装Version1.0.1 ...
- hadoop+yarn+hbase+storm+kafka+spark+zookeeper)高可用集群详细配置
配置 hadoop+yarn+hbase+storm+kafka+spark+zookeeper 高可用集群,同时安装相关组建:JDK,MySQL,Hive,Flume 文章目录 环境介绍 节点介绍 ...
- Zuul的容错与回退与Zuul的高可用
容错与回退 复制zuul项目,修改ArtifactId 如zuul-falllback 写Zuul的回退类 @Component public class ZuulFallBackProvider ...
- 【亲述】Uber容错设计与多机房容灾方案 - 高可用架构系列
此文是根据赵磊在[QCON高可用架构群]中的分享内容整理而成.转载请事先联系赵磊及相关编辑. 赵磊,Uber高级工程师,08年上海交通大学毕业,曾就职于微软,后加入Facebook主要负责Messen ...
- java亿级流量电商详情页系统的大型高并发与高可用缓存架构实战视频教程
亿级流量电商详情页系统的大型高并发与高可用缓存架构实战 完整高清含源码,需要课程的联系QQ:2608609000 1[免费观看]课程介绍以及高并发高可用复杂系统中的缓存架构有哪些东西2[免费观看]基于 ...
- RabbitMQ 高可用集群搭建及电商平台使用经验总结
面向EDA(事件驱动架构)的方式来设计你的消息 AMQP routing key的设计 RabbitMQ cluster搭建 Mirror queue policy设置 两个不错的RabbitMQ p ...
- 理解 OpenStack 高可用(HA)(2):Neutron L3 Agent HA 之 虚拟路由冗余协议(VRRP)
本系列会分析OpenStack 的高可用性(HA)概念和解决方案: (1)OpenStack 高可用方案概述 (2)Neutron L3 Agent HA - VRRP (虚拟路由冗余协议) (3)N ...
- Memcached集群/分布式/高可用 及 Magent缓存代理搭建过程 详解
当网站访问量达到一定时,如何做Memcached集群,又如何高可用,是接下来要讨论的问题. 有这么一段文字来描述“Memcached集群” Memcached如何处理容错的? 不处理!:) 在memc ...
随机推荐
- bridged(桥接模式)、NAT(网络地址转换模式)和host-only(主机模式)-VMware下三种网络配置方式
VMWare提供了三种工作模式,它们是bridged(桥接模式).NAT(网络地址转换模式)和host-only(主机模式).要想在网络管理和维护中合理应用它们,你就应该先了解一下这三种工作模式. 1 ...
- 如何处理导出的csv无法查看身份证后三位的情况?
如何处理导出的csv无法查看身份证后三位的情况? 原因:excel中如果是常规格式无法显示那么多位数,改成文本格式就可以. 简单步骤,导入数据------>选择数据来源------>选择编 ...
- meta标签有何作用?一起来学习一下
平日里总是沉迷于写页面写组件思考业务逻辑,解决冲突找出bug,猛的发现躲在head标签里的一大串标签时什么?这么多meta标签好多居然都不知其存在的意义.所以决定记录一下学习到的知识点. 先搞明白以上 ...
- ASP.NET Core 依赖注入
一.什么是依赖注入(Denpendency Injection) 这也是个老身常谈的问题,到底依赖注入是什么? 为什么要用它? 初学者特别容易对控制反转IOC(Iversion of Control) ...
- 51 NOD 1238 最小公倍数之和 V3
原题链接 最近被51NOD的数论题各种刷……(NOI快到了我在干什么啊! 然后发现这题在网上找不到题解……那么既然A了就来骗一波访问量吧…… (然而并不怎么会用什么公式编辑器,写得丑也凑合着看吧…… ...
- [bzoj4240] 有趣的家庭菜园
还是膜网上题解QAQ 从低到高考虑,这样就不会影响后挪的草了. 每次把草贪心地挪到代价较小的一边.位置为i的草,花费为min( 1..i-1中更高的草的数目,i+1..n中更高的草的数目 ) 因为更小 ...
- map映照容器的使用
map映照容器可以实现各种不同类型数据的对应关系,有着类似学号表的功能. 今天在做并查集的训练时,就用上了map映照容器. 题目就不上了,直接讲一下用法.顺便说一下,实现过程是在C++的条件下. #i ...
- NEFU_117素数个数的位数
题目传送门:点击打开链接 Problem : 117 Time Limit : 1000ms Memory Limit : 65536K description 小明是一个聪明的孩子,对数论有着很浓烈 ...
- linux 操作系统/xxx目录下都是什么文件?
/bin:存放最常用命令: /dev:设备文件: /etc:存放各种配置文件: /home:用户主目录: /lib:系统最基本的动态链接共享库: /mnt:一般是空的,用来临时挂载别的文件系统: /b ...
- [国嵌笔记][004][Linux快速体验]
Linux文件系统 bin目录:可执行的程序 boot目录:与Linux启动相关的文件 dev目录:设备以文件的方式存放 etc目录:配置文件 home目录:用户文件 lib目录:与库相关的文件 ro ...