深入浅出Java分布式系统通信
对java分布式系统通信的理解:
1.集群模式,将相同应用模块部署多份
2.业务拆分模式,将业务拆分成多个模块,并分别部署
3.存储分布式
由于分布式概念太大,我们可以缩小下讨论的范围。
以下分布式的狭义定义为:
业务拆分,但不限于水平拆分,而是拆分出底层模块,功能模块,上层模块等等。
一个系统功能繁多,且有层次依赖,那么我们需要将其分为很多模块,并分别部署 。
举例:
比如我们现在开发一个类似于钱包的系统,那么它会有如下功能模块:用户模块(用户数据),
应用模块(如手机充值等),业务模块(处理核心业务),交易模块(与银行发生交易),
前置模块(与客户端通信) 等等
我们会得到一个系统架构图:
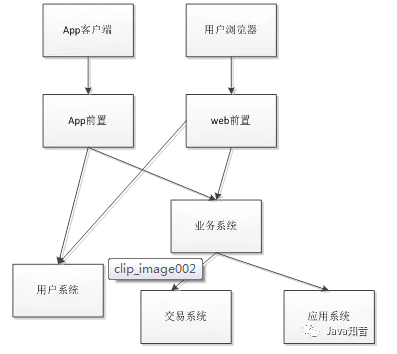
为什么要分布式
1) 将系统功能模块化,且部署在不同的地方,对于底层模块,只要保持接口不变,
上层系统调用底层模块将不关心其具体实现,且底层模块做内部逻辑变更,上层系统
都不需要再做发布,可以极大限度的解耦合
2) 解耦合之后,可以复用共同的功能,且业务扩展更为方便,加快开发和发布的速度
3) 系统分开部署,充分利用硬件,可以提高系统性能
4) 减少数据库连接资源的消耗
分布式通信方案
场景:服务端与服务端的通信
方案1:基于socket短连接
方案2:基于socket长连接同步通信
方案3:基于socket长连接异步通信
tcp短连接通信方案
短连接:http短连接,或者socket短连接,是指每次客户端和服务端通信的时候,都要新建立一个socket连接,本次通信完毕后,立即关闭该连接,也就是说每次通信都需要开启一个新的连接 。
传输图如下:

io通信用mina实现
客户端示例代码:
NioSocketConnector connector = new NioSocketConnector();
connector.setConnectTimeoutMillis(CONNECT_TIMEOUT);
//设置读缓冲,传输的内容必须小于此缓冲
connector.getSessionConfig().setReadBufferSize(2048*2048);
//设置编码解码器
connector.getFilterChain().addLast("codec",
new ProtocolCodecFilter(new ObjectSerializationCodecFactory()));
//设置日志过滤器
connector.getFilterChain().addLast("logger", new LoggingFilter());
//设置Handler
connector.setHandler(new MyClientHandler());
//获取连接,该方法为异步执行
ConnectFuture future = connector.connect(new InetSocketAddress(
HOSTNAME, PORT));
//等待连接建立
future.awaitUninterruptibly();
//获取session
IoSession session = future.getSession();
//等待session关闭
session.getCloseFuture().awaitUninterruptibly();
//释放connector
connector.dispose();下面我们进行性能测试:
测试场景:
每个请求的业务处理时间110ms
100个线程并发测试,每个线程循环请求服务端
测试环境:
客户端服务器:
Cpu为4线程 2400mhz
服务端cpu: 4线程 3000Mhz
测试结果:
在经过10分钟测试之后,稳定情况下的tps
Tps:554左右
客户端Cpu:30%
服务端cpu:230%
该方案的优点:
程序实现起来简单
该方案的缺点:
1. Socket发送消息时,需要先发送至socket缓冲区,因此系统为每个socket分配缓冲区
当缓冲不足时,就达到了最大连接数的限制
2. 连接数大,也就意味着系统内核调用的越多,socket的accept和close调用
3.每次通信都重新开启新的tcp连接,握手协议耗时间,tcp是三次握手
4.tcp是慢启动,TCP 数据传输的性能还取决于 TCP 连接的使用期(age)。TCP 连接会随着时间进行自我“调谐”,起初会限制连接的最大速度,如果数据成功传输,会随着时间的推移提高传输的速度。这种调谐被称为 TCP 慢启动(slow start),用于防止因特网的突然过载和拥塞 。
tcp长连接同步通信
长连接同步的传输图

一个socket连接在同一时间只能传递一个请求的信息只有等到response之后,第二个请求才能开始使用这个通道。
为了提高并发性能,可以提供多个连接,建立一个连接池,连接被使用的时候标志为正在使用,使用完放回连接池,标识为空闲,这和jdbc连接池是一样的。
假设后端服务器,tps是1000,即每秒处理业务数是1000。现在内网传输耗时是5毫秒,业务处理一次请求的时间为150毫秒,那么一次请求从客户端发起请求到得到服务端的响应,总共耗时150毫秒+5毫秒*2=160毫秒。
如果只有一个连接通信,那么1秒内只能完成2次业务处理,即tps为2。如果要使tps达到1000,那么理论上需要500个连接,但是当连接数上升的时候,其性能却在下降,因此该方案将会降低网站的吞吐量。
实现挑战:
mina的session.write()和receive消息都是异步的,那么需要在主线程上阻塞以等待响应的到达。
连接池代码:
/**
* 空闲连接池
*/
private static BlockingQueue<Connection> idlePool = new LinkedBlockingQueue<Connection>();
/**
* 使用中的连接池
*/
public static BlockingQueue<Connection> activePool = new LinkedBlockingQueue<Connection>();
public static Connection getConn() throws InterruptedException{
long time1 = System.currentTimeMillis();
Connection connection = null;
connection = idlePool.take();
activePool.add(connection);
long time2 = System.currentTimeMillis();
//log.info("获取连接耗时:"+(time2-time1));
return connection;
}
客户端代码:
public TransInfo send(TransInfo info) throws InterruptedException {
Result result = new Result();
//获取tcp连接
Connection connection = ConnectFutureFactory.getConnection(result);
ConnectFuture connectFuture = connection.getConnection();
IoSession session = connectFuture.getSession();
session.setAttribute("result", result);
//发送信息
session.write(info);
//同步阻塞获取响应
TransInfo synGetInfo = result.synGetInfo();
//此处并不是真正关闭连接,而是将连接放回连接池
ConnectFutureFactory.close(connection,result);
return synGetInfo;
}
阻塞获取服务端响应代码:
public synchronized TransInfo synGetInfo() {
//等待消息返回
//必须要在同步的情况下执行
if (!done) {
try {
wait();
} catch (InterruptedException e) {
log.error(e.getMessage(), e);
}
}
return info;
}
public synchronized void synSetInfo(TransInfo info) {
this.info = info;
this.done = true;
notify();
}
测试场景:
每个请求的业务处理时间110ms
300个线程300个连接并发测试,每个线程循环请求服务端
测试环境:
客户端服务器:
Cpu为4线程 2400mhz
服务端cpu: 4线程 3000Mhz
测试结果:
在经过10分钟测试之后,稳定情况下的tps
Tps:2332左右
客户端Cpu:90%
服务端cpu:250%
从测试结果可以看出,当连接数足够大的时候,系统性能会降低,开启的tcp连接数越多,那么系统开销将会越大。
tcp长连接异步通信
通信图:
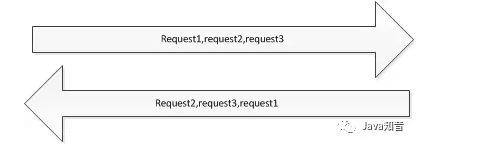
一个socket连接在同一时间内传输多次请求的信息,输入通道接收多条响应消息,消息是连续发出,连续收回的。
业务处理和发消息是异步的,一个业务线程告诉通道发送消息后,不再占用通道,而是等待响应到达,而此时其它业务线程也可以往该连接通道发信息,这样可以充分利用通道来进行通信。
实现挑战
该方案使编码变得复杂,如上图,请求request1,request2,request3顺序发出,但是服务端处理请求并不是排队的,而是并行处理的,有可能request3先于request1响应给客户端,那么一个request将无法找到他的response,这时候我们需要在request和response报文中添加唯一标识,如通信序列号,在一个通信通道里面保持唯一,那么可以根据序列号去获取对应的响应报文。
我的方案是:
1.客户端获取一个tcp连接
2.调用session.write()发送信息,并将消息的唯一序列号存入一个Result对象
result对象存入一个map
3.同步阻塞获取结果,线程在result对象进行同步阻塞
4.接收消息,并通过唯一序列号从map里面获取result对象,并唤醒阻塞在result对象上的线程。
客户端发送消息示例代码:
public TransInfo send(TransInfo info) throws InterruptedException {
Result result = new Result();
result.setInfo(info);
//获取socket连接
ConnectFuture connectFuture = ConnectFutureFactory
.getConnection(result);
IoSession session = connectFuture.getSession();
//将result放入ConcurrentHashMap
ConcurrentHashMap<Long, Result> resultMap = (ConcurrentHashMap<Long, Result>)session.getAttribute("resultMap");
resultMap.put(info.getId(), result);
//发送消息
session.write(info);
//同步阻塞获取结果
return result.synGetInfo();
}
同步阻塞和唤醒方法:
public synchronized TransInfo synGetInfo() {
//等待消息返回
//必须要在同步的情况下执行
while (!done) {
try {
wait();
} catch (InterruptedException e) {
log.error(e.getMessage(), e);
}
}
return info;
}
public synchronized void synSetInfo(TransInfo info) {
this.info = info;
this.done = true;
notify();
}
接收消息示例代码:
public void messageReceived(IoSession session, Object message)
throws Exception {
TransInfo info = (TransInfo) message;
//根据唯一序列号从resultMap中获取result
ConcurrentHashMap<Long, Result> resultMap = (ConcurrentHashMap<Long, Result>)session.getAttribute("resultMap");
//移除result
Result result = resultMap.remove(info.getId());
//唤醒阻塞线程
result.synSetInfo(info);
}
测试场景:
每个请求的业务处理时间110ms
300个线程10个连接并发测试,每个线程循环请求服务端
测试环境:
客户端服务器:
Cpu为4线程 2400mhz
服务端cpu: 4线程 3000Mhz
测试结果:
在经过10分钟测试之后,稳定情况下的tps
Tps:2600左右
客户端Cpu:25%
服务端cpu:250%
经测试发现,异步通信可以用更少的tcp连接实现同样高效的通信,极大的减少了系统性能开销。
深入浅出Java分布式系统通信的更多相关文章
- Java分布式开发
分布式概念的引入是基于性能的提升,应用的可靠性而提出的.所谓Java分布式,即是在使用Java语言进行企业级应用开发的过程中,采用分布式技术解决业务逻辑的高并发.高可用性的一些架构设计方案. 1. R ...
- 5个强大的Java分布式缓存框架推荐
在开发中大型Java软件项目时,很多Java架构师都会遇到数据库读写瓶颈,如果你在系统架构时并没有将缓存策略考虑进去,或者并没有选择更优的 缓存策略,那么到时候重构起来将会是一个噩梦.本文主要是分享了 ...
- 深入浅出Java并发包—锁机制(三)
接上文<深入浅出Java并发包—锁机制(二)> 由锁衍生的下一个对象是条件变量,这个对象的存在很大程度上是为了解决Object.wait/notify/notifyAll难以使用的问题. ...
- 深入浅出Java并发包—锁机制(二)
接上文<深入浅出Java并发包—锁机制(一) > 2.Sync.FairSync.TryAcquire(公平锁) 我们直接来看代码 protected final boolean tr ...
- Java分布式处理技术(RMI,JDNI)
http://hedaoyuan.blog.51cto.com/4639772/813702 1.1 RMI的基本概念 1.1.1 什么是RMI RMI(Remote Method Invocatio ...
- Java分布式缓存框架
http://developer.51cto.com/art/201411/457423.htm 在开发中大型Java软件项目时,很多Java架构师都会遇到数据库读写瓶颈,如果你在系统架构时并没有将缓 ...
- 深入浅出Java 重定向和请求转发的区别
深入浅出Java 重定向和请求转发的区别 <span style="font-family:FangSong_GB2312;font-size:18px;">impor ...
- 深入浅出Java动态代理
文章首发于[博客园-陈树义],点击跳转到原文深入浅出Java动态代理 代理模式是设计模式中非常重要的一种类型,而设计模式又是编程中非常重要的知识点,特别是在业务系统的重构中,更是有举足轻重的地位.代理 ...
- Java分布式锁之数据库实现
之前的文章<Java分布式锁实现>中列举了分布式锁的3种实现方式,分别是基于数据库实现,基于缓存实现和基于zookeeper实现.三种实现方式各有可取之处,本篇文章就详细讲解一下Java分 ...
随机推荐
- WeakHashMap回收时机结合JVM 虚拟机GC的一些理解
一直很想知道WeakHashMap的使用场景,想来想去只能用在高速缓存中,而且缓存的数据还不是特别重要,因为key(key不存在被引用的时候)随时会被回收 所以研究了一下WeakHashMap的回收时 ...
- 叼叼叼,HTML5日期(Date)类型和文本(Text)类型互相转换
<input placeholder="From" class="form-control" type="text" onfocus= ...
- 浅谈JavaScript位操作符
因为ECMAscript中所有数值都是以IEEE-75464格式存储,所以才会诞生了位操作符的概念. 位操作符作用于最基本的层次上,因为数值按位存储,所以位操作符的作用也就是操作数值的位.不过位操作符 ...
- UART知识总结
一.定义 通用异步收发传输器(Universal Asynchronous Receiver/Transmitter),通常称作UART. 二.时序 上图是uart协议传输一个"A" ...
- web工程导入新环境的注意事项
问题一:The type java.lang.Object cannot be resolved. 解决办法: 当你在Eclipse引用不同版本JDK工程时会发生该问题.由于你开发环境中应用了多个版本 ...
- 为你的APK进行数字签名
摘要: 我们需要为 APK进行数字签名,这样才能发布到 Google Play商店.解决方法很简单,使用 Java的keytool命令创建证书并在 Gradle构建文件的 signingConfigs ...
- R︱高效数据操作——data.table包(实战心得、dplyr对比、key灵活用法、数据合并)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 由于业务中接触的数据量很大,于是不得不转战开始 ...
- ffmpeg结构体以及函数介绍(一)
本文对在使用ffmpeg进行音视频编解码时使用到的一些函数做一个简单介绍,我当前使用的ffmpeg版本为:0.8.5,因为本人发现在不同的版本中,有些函数名称会有点小改动,所以在此有必要说明下ffmp ...
- discuz 更换域名 导致qq登录不能用的问题
今天论坛换了域名,导致qq登录不能用.于是各种百度,终于找到了解决方案,特此记录一下 解决方法:1,首先清空你站点的id和key,并且设置为未注册云平台: 2,找一个新域名(未开过云平台的就可),如果 ...
- javascript 获取随机数
javascript 获取随机数 var rand=Math.floor(Math.random()*(n+1)) floor 向下取整 random 获得0-1之间的随机数