基于Python的数据分析(2):字符串编码
在上一篇文章《基于Python的数据分析(1):配置安装环境》中的第四个步骤中我们在python的启动步骤中强制要求加载sitecustomize.py文件并设置其默认编码为“utf-8”。本篇文章会介绍为什么要增加这个文件以及如何处理python的字符串编码的问题。
字符串变量和unicode值
字符串变量是所有编程语言里面定义多字符的一种变量类型。
在python中我们必须区分清楚字符串变量和unicode值这两个的区别。在其他的语言或者在python3.0以上的版本中,定义字符串的时候就是定义的该字符串的unicode的值(有特别设定的除外)。但是在python2.7(或者低于2.7的版本)中,字符串str的定义的是8位文本和二进制数据,这意味着什么呢,如果你编码定义字符串的平台默认是以GBK编码的话,那么所定义的字符串也就是GBK编码,我们可以验证一下是否如此:在下图中,在python shell里面定义一个字符创”abc中文“,我们发现,只有用gbk编码去解码decode才能正常识别该字符串,那么我们就可以说我使用的这个python shell默认的是gbk编码字符,因为字符串变量s是被gbk编码了。
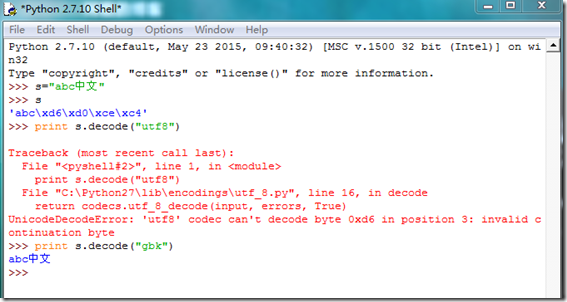
大家可以会说,用gbk编码也没什么问题啊,反正可以正常读写。事实上,这样理解是片面的,在涉及到python处理文本、数据库、网络流的数据的过程中时候,有其他平台的字符串要交互的时候就会报错,例如我输出gbk编码的字符串到以utf8编码存储的数据库的时候,在数据库中该字符串是以乱码存在的,这个逻辑类似于于一个法国人跟我一个只会讲中文和英文的中国人来说法文的时候,我接受到的都是无效信息(事实上我根本不知道他在说什么)。
这时候就需要一个转义的机制存在,同样以上面这个法国人和中国人聊天的例子为例,如果他们都是以各自国家的方言进行聊天的话,肯定是鸡同鸭讲,但是如果以英语作为公共语言交流就不会出现问题。在python2.7中我们同样需要做一下这个操作,就是把所有的编码都转成一个统一的编码,一个普遍的解决方案就是采用字符串的unicode。字符的unicode是业界的一种标准,它可以使电脑得以呈现世界上数十种文字的系统。 在计算机技术全球化发展的阶段,程序猿们纷纷觉得太多编码导致世界变得过于复杂了,让人脑袋疼,于是大家坐在一起拍脑袋想出来一个方法:所有语言的字符都用同一种字符集来表示,这就是Unicode。
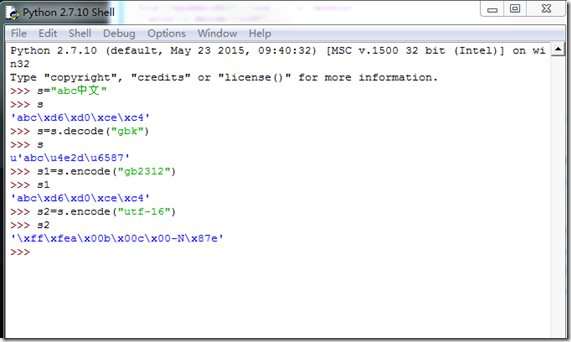
转义的操作分两个encode和decode两个操作。decode就是把编码字符按照其设定的编码格式解码成unicode,encode就是把unicode按照特定的编码格式编码成某种编码字符,例如:在下图操作中,我们把s.decode(“gbk”)后获得s的unicode值存储在s中,并对s进行两种编码分别得到s1和s2。
为了加深大家的理解,我画了下图:
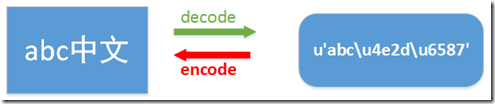
字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码decode的作用是将其他编码的字符串转换成unicode编码,如str1.decode('gb2312'),表示将gb2312编码的字符串str1转换成unicode编码。 encode的作用是将unicode编码转换成其他编码的字符串,如str2.encode('gb2312'),表示将unicode编码的字符串str2转换成gb2312编码。因此,转码的时候一定要先搞明白,字符串str是什么编码,然后decode成unicode,然后再encode成其他编码。代码中字符串的默认编码与代码文件本身的编码一致
如何解决编码问题
好的。现在我们在python2.7中怎样解决编码问题了:
1.加入sitecustomize.py,告诉python你启动以后就用utf-8编码来解决编码的问题。就是告诉python默认奖unicode值编码成为utf-8,除非我明确设定了。
sitecustomize.py is a special script; Python will try to import it on startup, so any code in it will be run automatically. As the comment mentions, it can go anywhere (as long as import can find it), but it usually goes in the site-packages directory within your Python lib directory.
setdefaultencoding function sets, well, the default encoding. This is the encoding scheme that Python will try to use whenever it needs to auto-coerce a unicode string into a regular string.
大家可以自己做一下测试,import sys这个包,然后打印sys.path,会有下面的输出:
['D:\\Workspace\\Code\\hekejun', 'D:\\Workspace\\Code', 'C:\\Windows\\system32\\python27.zip', 'C:\\Python27\\DLLs', 'C:\\Python27\\lib', 'C:\\Python27\\lib\\plat-win', 'C:\\Python27\\lib\\lib-tk', 'C:\\Python27', 'C:\\Python27\\lib\\site-packages', 'C:\\Python27\\lib\\site-packages\\win32', 'C:\\Python27\\lib\\site-packages\\win32\\lib', 'C:\\Python27\\lib\\site-packages\\Pythonwin', 'C:\\Python27\\lib\\site-packages\\wx-3.0-msw']
前面两个路径是我运行的代码所在的目录,往下看,我们可以看到'C:\\Python27\\lib\\site-packages'这个目录,在这个目录下,python会自动加载sitecustomize.py。
2.将文件格式设定为utf-8编码。就是在每个.py文件(python源文件)的首行加入这一行声明:
#-*- coding: utf-8 -*-
事实上python只认#、coding和编码字符创,其他的只为了好看,是的你没看错,只为了好看而已。
3.定义任一字符串变量s的时候,如果该字符串包括非字幕数字以外的字符,尤其是含有中文字符的时候,用下面任一声明方式:
s=u"abc中文"
s="abc中文".decode("utf-8")
4.在实际处理字符的过程中如果遇到不知道什么编码的,建议下载一个第三方包chardet,然后用下面的方法去分析即可
import chardet
s1="中文abc"
print chardet.detect(s1) s2=u"中文abc".encode("GBK")
print chardet.detect(s2)
注意第二段代码,chardet分析GBK编码或者GB2312编码的字符的时候总是分析为“KOI8-R”编码,原因网上搜索了也不知道为啥,估计是内部的一个不够。其他编码可以正常分析得到。
注意chardet不能去分析unicode,不然会报错,当然这也可以作为探测的一种手段吧,如果报错那么说明当前的字符串是unicode呗。
import chardet
s3=u"abc中文"
print chardet.detect(s3) Traceback (most recent call last):
File "D:\Test.py", line 81, in <module>
print chardet.detect(s3)
File "C:\Python27\lib\site-packages\chardet\__init__.py", line 25, in detect
raise ValueError('Expected a bytes object, not a unicode object')
ValueError: Expected a bytes object, not a unicode object
基于Python的数据分析(2):字符串编码的更多相关文章
- 基于Python的数据分析(1):配置安装环境
数据分析是一个历史久远的东西,但是直到近代微型计算机的普及,数据分析的价值才得到大家的重视.到了今天,数据分析已经成为企业生产运维的一个核心组成部分. 据我自己做数据分析的经验来看,目前数据分析按照使 ...
- 基于Python的数据分析(3):文件和时间
在接下来的章节中,我会重点介绍一下我自己写的基于之前做python数据分析的打包接口文件common_lib,可以认为是专用于python的第三方支持库.common_lib目前包括文件操作.时间操作 ...
- Python学习 Day 3 字符串 编码 list tuple 循环 dict set
字符串和编码 字符 ASCII Unicode UTF-8 A 1000001 00000000 01000001 1000001 中 x 01001110 00101101 11100100 101 ...
- python基础语法_字符串编码
Python常用字符编码 http://www.cnblogs.com/schut/p/8406897.html Python常见字符编码间的转换 在字符串写入文件时,有时会因编码问题导致无法 ...
- 基于Python的数据分析:数据库索引效率探究
索引在数据库中是一个很特殊的存在,它的目的就是为了提高数据查询得效率.同样,它也有弊端,更新一个带索引的表的时间比更新一个没有带索引的时间更长.有得有失.我希望做一些研究测试,搞清楚索引对于我们使用数 ...
- 利用Python进行数据分析
最近在阅读<利用Python进行数据分析>,本篇博文作为读书笔记 ,记录一下阅读书签和实践心得. 准备工作 python环境配置好了,可以参见我之前的博文<基于Python的数据分析 ...
- 数据分析:基于Python的自定义文件格式转换系统
*:first-child { margin-top: 0 !important; } body>*:last-child { margin-bottom: 0 !important; } /* ...
- python字符串编码理解(转载)
(转载)字符编码和python使用encode,decode转换utf-8, gbk, gb2312 (http://www.cnblogs.com/jxzheng/p/5186490.html) A ...
- 对字符串进行base64加解密---基于python
本文介绍Python 2.7中的base64模块,该模块提供了基于rfc3548的Base16, 32, 64编解码的接口.官方文档,参考这里. 当前接口基于rfc3548的Base16/32/64编 ...
随机推荐
- 从Perforce到Git的迁移
公司经过多次兼并.收购之后,开发团队使用的工具自然会出现鱼龙混杂的现象.就拿源代码管理工具来说,我们同时在使用的就有Perforce.Team Foundation.Subversion等.为了节省成 ...
- Dynamics CRM 2011/2013 section的隐藏
代码如下 Xrm.Page.ui.tabs.get("TabName").sections.get("SectionName").setVisi ...
- 【Android 应用开发】Activity 状态保存 OnSaveInstanceState参数解析
作者 : 韩曙亮 转载请著名出处 : http://blog.csdn.net/shulianghan/article/details/38297083 一. 相关方法简介 1. 状态保存方法示例 p ...
- Linux0.11中对文本文件进行修改的策略
现在,假设 hello.txt 是硬盘上已有的一个文件,而且内容为 "hello, world" ,在文件的当前指针设置完毕后,我们来介绍 sys_read , sys_write ...
- 【Unity Shaders】Using Textures for Effects——通过修改UV坐标来滚动textures
本系列主要参考<Unity Shaders and Effects Cookbook>一书(感谢原书作者),同时会加上一点个人理解或拓展. 这里是本书所有的插图.这里是本书所需的代码和资源 ...
- ORACLE收集统计信息
1. 理解什么是统计信息 优化器统计信息就是一个更加详细描述数据库和数据库对象的集合,这些统计信息被用于查询优化器,让其为每条SQL语句选择最佳的执行计划.优化器统计信息包括: · ...
- 11_Android中HttpClient的应用,读取网络xml及xml解析流,Handler的应用,LayoutInflater的使用,SmartImageView的使用
1 所需的web项目结构如下: 2 new.xml的文件内容如下: <?xml version="1.0" encoding="UTF-8" ?&g ...
- python,os操作文件,文件路径(上一级目录)
python获取文件上一级目录:取文件所在目录的上一级目录 os.path.abspath(os.path.join(os.path.dirname('settings.py'),os.path.pa ...
- 数据结构基础(1) --Swap & Bubble-Sort & Select-Sort
Swap的简单实现 //C语言方式(by-pointer): template <typename Type> bool swapByPointer(Type *pointer1, Typ ...
- 更改EBS服务器域名/IP
more: 341322.1 : How to change the hostname of an Applications Tier using AutoConfig 338003.1 : How ...