JUC 并发编程--08,线程池,三大方法,七大参数,4种拒绝策略,代码演示
三大方法:
//线程池核心线程数为n, 最大线程数为 n
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(n);
源码: 可以看到核心线程数, 和最大线程数相同, 这种线程池伸缩性,扩展性不好

//线程池核心线程数为1, 最大线程数为 1
ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor();
源码: 可以看到核心线程数, 和最大线程数都是1, 实际生产中这种线程池用的很少,基本不会用

//缓存线程池: 无限大小
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
源码: 核心线程数为0, 最大线程数为Integer.MAX_VALUE = 21亿多, 实际生产中几乎永远不会达到最大线程数, 而且越来越多任务堆积在阻塞队列中,会造成 OOM

实际代码中我们都是使用自定义的线程池: 阿里巴巴开发手册中也是强烈建议,不要用jdk自带的线程池,而要自己定义,这样代码人能够清楚的看到线程池的资源配置
下面是我们自定义的线程池: 7大参数:
/**
* 线程池 四大拒绝策略: 拒绝策略什么时候生效: 当队列满了,且正在运行的线程数量>=最大maimumPoolSize, 此时拒绝策略生效
* AbortPolicy: 丢弃任务,直接抛异常
* DiscardPolicy 丢弃任务, 不抛异常
* DiscardOldestPolicy: 丢弃队列最前面的任务,然后重新提交被拒绝的任务
* CallerRunsPolicy: 由调用线程(提交任务的线程)处理该任务
**/
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(
2, //核心线程数
5,//最大线程数
3,// 多余空闲线程存活时间, 当线程池的线程数量超过corePoolSize,, 当空闲线程的空闲时间超过了 这个时间,多余的线程会被销毁,直到只剩下核心线程数量为止
TimeUnit.SECONDS,//空闲时间的单位
new ArrayBlockingQueue<>(3),//阻塞队列,
Executors.defaultThreadFactory(),//默认的线程工厂
//new ThreadPoolExecutor.AbortPolicy());//拒绝策略 : 直接丢弃,抛异常
//new ThreadPoolExecutor.DiscardPolicy());
new ThreadPoolExecutor.DiscardOldestPolicy());
//new ThreadPoolExecutor.CallerRunsPolicy());
文字描述,线程池原理描述: 自定义一个线程池: 核心线程数为2, 最大线程数为5,阻塞队列的大小为3,
1: 当调用execute()方法添加一个请求时候,线程池会做如下判断
*1.1: 如果正在运行的线程数量 小于 corePoolSize,那么马上创建线程执行这个任务
*1.2: 如果正在运行的线程数量 大于/等于 corePoolSize, 那么将这个任务加入阻塞队列
*1.3: 如果这时候 阻塞队列满了,且正在运行的线程数量 小于 maximumPoolSize , 那么就创建 非核心线程 立刻运行这个任务(稍后代码验证,这里是新开一个非核心线程立即执行这个任务 )
*1.4: 如果队列满了, 且正在运行的线程数量 大于/等于 maximumPoolSize , 那么线程池开启拒绝策略来执行
3: 当一个线程完成任务,他会从阻塞队列中取下一个任务来执行
4: 当一个线程无事可做 且超过一定时间(keepAliveTime)时,线程池会判断: 如果当前运行的线程 大于 corePoolSize, 那么这个线程就停掉.
问:
1, 目前自定义的这个线程池, 什么时候开启拒绝策略? 答:当有8个任务, 当队列满,且正在运行的线程等于最大线程数, 最大线程数为5, 队列为3,所以为 8, 当有8个任务时候,此时不抛异常,但是已经开启了拒绝策略,第九个来的时候,就抛异常
2, 如果这时候 阻塞队列满了,且正在运行的线程数量 小于 maximumPoolSize , 那么就创建 非核心线程 立刻运行这个任务 ? 这个怎么证明
3, 四大拒绝策略怎么理解,证明的效果是?
/**
* 线程池 四大拒绝策略: 拒绝策略什么时候生效: 当队列满了,且正在运行的线程数量>=最大maimumPoolSize, 此时拒绝策略生效
* AbortPolicy: 丢弃任务,直接抛异常
* DiscardPolicy 丢弃任务, 不抛异常
* DiscardOldestPolicy: 丢弃队列最前面的任务,然后重新提交被拒绝的任务
* CallerRunsPolicy: 由调用线程(提交任务的线程)处理该任务
**/
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(
2, //核心线程数
5,//最大线程数
3,// 多余空闲线程存活时间, 当线程池的线程数量超过corePoolSize,, 当空闲线程的空闲时间超过了 这个时间,多余的线程会被销毁,直到只剩下核心线程数量为止
TimeUnit.SECONDS,//空闲时间的单位
new ArrayBlockingQueue<>(3),//阻塞队列,
Executors.defaultThreadFactory(),//默认的线程工厂
new ThreadPoolExecutor.AbortPolicy());//拒绝策略 : 直接丢弃,抛异常
//new ThreadPoolExecutor.DiscardPolicy());
//new ThreadPoolExecutor.DiscardOldestPolicy());
//new ThreadPoolExecutor.CallerRunsPolicy());
//这个线程池拒绝策略生效: 当线程数量>=8 时候, 开始生效, =8的时候,拒绝策略已经生效,但是没有新的线程进来,所以不报异常
try {
for (int i = 1; i <= 6; i++) {
int stmp = i;
poolExecutor.execute(()->{
System.out.println(Thread.currentThread().getName() + "--线程--接待的客户为:" + stmp);
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
poolExecutor.shutdown();
}
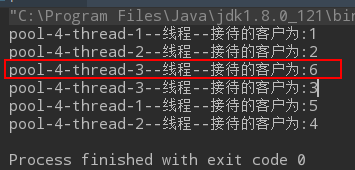
运行结果: 核心线程为2, 最大线程数为5, 6个任务过来 , 2个任务直接执行, 3,4,5任务进入阻塞队列, 此时还有一个任务6, 且,队列满,正在运行的线程数为2, 所以此时新开一个线程,来执行任务6,而且任务6 这个是立即执行的
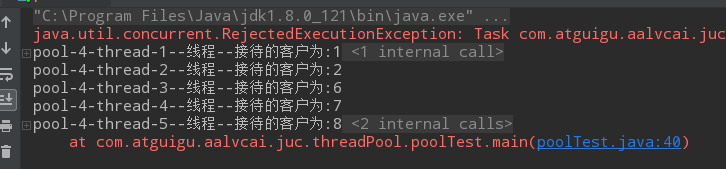
如果6个任务的基础上,是9个任务过来, 会发现正在运行的线程数为2, 队列中3个任务, 还有4个任务,且2<最大线程数5, 会创建3个线程,此时还有1个任务,所以此时会执行拒绝策略,由于采用的拒绝策略是abortPolicy, 所以直接抛异常
实际代码中我们都是使用的自定义线程池,这个参数,最大线程数是如何设置的?
答: 这里主要看自己的业务类型, 如果业务CPU型(就是说业务中计算的很多,而且是密集型计算,一计算内存就飙升), 线程数就设置为: cpu核数+1
如果业务是IO型,(就是说很多线程从数据库中取数据等等),这种情况下: 线程最大数就设置为: cpu核数 * 2
或者这样设置: cpu核数 / (1- 阻塞系数) 这个阻塞系数一般为0.8~0.9 如果取0.9, 线程数就为: cpu核数/0.1
JUC 并发编程--08,线程池,三大方法,七大参数,4种拒绝策略,代码演示的更多相关文章
- JUC之线程池-三大方法-七大参数-四种拒绝策略
线程池:重点 三大方法 七大参数 四种拒绝策略 使用池化技术的理由: 我们的程序伴随着创建销毁线程十分浪费资源, 所以使用线程池,先创建线程,随用随取,用完归还 简单来说就是节约了资源. 使用线程池的 ...
- 并发编程 13—— 线程池的使用 之 配置ThreadPoolExecutor 和 饱和策略
Java并发编程实践 目录 并发编程 01—— ThreadLocal 并发编程 02—— ConcurrentHashMap 并发编程 03—— 阻塞队列和生产者-消费者模式 并发编程 04—— 闭 ...
- Java并发编程:线程池的使用
Java并发编程:线程池的使用 在前面的文章中,我们使用线程的时候就去创建一个线程,这样实现起来非常简便,但是就会有一个问题: 如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了, ...
- Java并发编程:线程池的使用(转)
Java并发编程:线程池的使用 在前面的文章中,我们使用线程的时候就去创建一个线程,这样实现起来非常简便,但是就会有一个问题: 如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了, ...
- Java并发编程:线程池的使用(转载)
转载自:https://www.cnblogs.com/dolphin0520/p/3932921.html Java并发编程:线程池的使用 在前面的文章中,我们使用线程的时候就去创建一个线程,这样实 ...
- Java并发编程:线程池的使用(转载)
文章出处:http://www.cnblogs.com/dolphin0520/p/3932921.html Java并发编程:线程池的使用 在前面的文章中,我们使用线程的时候就去创建一个线程,这样实 ...
- [转]Java并发编程:线程池的使用
Java并发编程:线程池的使用 在前面的文章中,我们使用线程的时候就去创建一个线程,这样实现起来非常简便,但是就会有一个问题: 如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了, ...
- 《转载》Python并发编程之线程池/进程池--concurrent.futures模块
本文转载自Python并发编程之线程池/进程池--concurrent.futures模块 一.关于concurrent.futures模块 Python标准库为我们提供了threading和mult ...
- 【转】Java并发编程:线程池的使用
Java并发编程:线程池的使用 在前面的文章中,我们使用线程的时候就去创建一个线程,这样实现起来非常简便,但是就会有一个问题: 如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了, ...
随机推荐
- Linux中Tomcat和Jboss的安装和部署
目录 JDK环境 yum源安装JDK 源码包安装JDK Tomcat的安装 yum源安装 目录结构: 源码包安装 目录结构: 目录中主要的文件: JBoss的安装 目录结构: Tomcat是Apach ...
- Linux中的.bash_ 文件详解
目录 .bash_history .bash_logout .bash_profile .bashrc 每个用户的根目录下都有四个这样的 bash文件,他们是隐藏文件,需要使用-a参数才会显示出来 . ...
- 每天一道面试题LeetCode 01 -- 两数之和
Two Sum 两数之和 Given an array of integers, find two numbers such that they add up to a specific target ...
- JavaScript实现减速返回顶部
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 真正的原生JS数据双向绑定(实时同步)
真正的原生JS数据双向绑定(实时同步) 接触过vue之后我感觉数据双向绑定实在是太好用了,然后就想着到底是什么原理,今天在简书上看到了一位老师的文章 js实现数据双向绑定 然后写出了我自己的代码 wi ...
- ArrayList方法源码分析
本文将从ArrayList类的存储结构.初始化.增删数据.扩容处理以及元素迭代等几个方面,分析该类常用方法的源码. 数据存储设计 该类用一个Object类型的数组存储容器的元素.对于容量为空的情况,提 ...
- Linux_LVM管理
一.Ivm的应用场景及其弊端 1.应用场景: 随着公司的发展,数据增长较快,最初规划的磁盘容量不够用了 2.弊端: 数据不是直接存放在硬盘上,而是在硬盘的.上面又虚拟出来--层逻辑卷存放数据,故而增加 ...
- k8s用 ConfigMap 管理配置(13)
一.ConfigMap介绍 Secret 可以为 Pod 提供密码.Token.私钥等敏感数据:对于一些非敏感数据,比如应用的配置信息,则可以用 ConfigMap ConfigMap 的创建和使用方 ...
- kvm虚拟机迁移(6)
一.迁移简介 迁移: 系统的迁移是指把源主机上的操作系统和应用程序移动到目的主机,并且能够在目的主机上正常运行. 在没有虚拟机的时代,物理机之间的迁移依靠的是系统备份和恢复技术.在源主机上实 ...
- mysql基础之查询缓存、存储引擎
一.查询缓存 "查询缓存",就是将查询的结果缓存下载,如果查询语句完全相同,则直接返回缓存中的结果. 如果应用程序在某个场景中,需要经常执行大量的相同的查询,而且查询出的数据不会经 ...