从Rest到Graphql
一.引言

ok,如图所示,我在去年曾经写过一篇文章《闲侃前后端分离的必要性》。嗯,我知道肯定很多人没看过。所以我做一个总结,其实啰里八嗦了一篇文章,就是想说一下现在的大型互联网项目一般是如下两种架构之一 - 前后端半分离架构 - 前后端分离架构
区别分离和半分离的标志在于Controller层由不由前端控制,Controller在前端手里,前端手里握着组装数据的逻辑,那就是前后端分离!否则就是半分离!
那么,半分离和分离的架构是长下面这样的
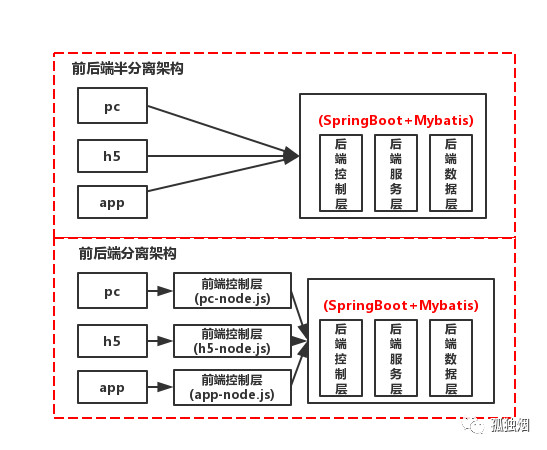
ps:中小型公司慎重,不要玩前后端分离架构!前端工作量贼大!
那么用上了前后端分离架构后,后端的API一般会按照Restful风格来设计!ResultFul推荐每个URL能操作具体的资源,而且能准确描述服务器对资源的处理动作,通常服务器对资源支持get/post/put/delete/等,用来实现资源的增删改查。前后端分离的架构下,这些api-url是对接的桥梁,采用ResultFul接口地址含义才更清晰、见名知意。
那么,在实践RestFul风格的API的有一个致命的缺陷,是神马类?嗯,带着你的疑惑开始本文
二.正文
RestFul的缺陷
假设,此时我们有两个资源分别是Book和Author,这两个资源对应的ER图如下
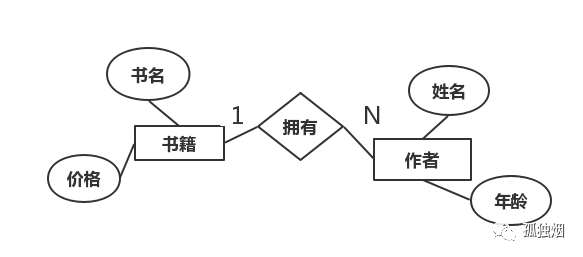
相应的API有
POST /books
GET /books/{id}
POST /authors
GET /authors/{id}
我们有一个需求,需要查询id=1的图书信息!
那我们的请求地址是这样的
GET /books/1
返回结果是这样的
[{
"id": 1,
"bookname": Harry Potter,
"price": 56.00,
"author_id": 2
}]
这时候前端MM拿到这个结果后,傻了眼!这里怎么能直接返回author_id呢,难道直接把author_id显示在界面上么?不可能啊,界面上要显示的是author_name才行!
OK,那么在这种情况下,有两种方式可以解决问题!
(1) 跟后端沟通,让他增加一个接口
嗯,我们复习一下什么是VO对象。
VO(View Object):视图对象,用于展示层,它的作用是把某个指定页面(或组件)的所有数据封装起来。
那可以让后端封装一个接口,后端帮你把数据拼装好,提供API如下
GET /bookVOs/1
这样直接返回的结果就是
[{
"id": 1,
"bookname": Harry Potter,
"price": 56.00,
"author_name": J. K. Rowling
}]
当然,因为你这是临时让后端加接口,可能会有如下情形产生

OK,回到正题,这样做的缺点主要有两个
前后端强耦合在一起,前端界面发生变动,后端VO对象跟着一起变
如果BookVO对象在手机端、PC端、APP端的显示内容都不一样,你可能在项目中会有BookPcVO类、BookH5VO类、BookAppVO类,VO类大大膨胀!
(2) 自己做适配
这个也很简单,前端获得结果后,取出author_id: 2这条记录,然后再去调用地址
GET /authors/2
得到结果,然后进行组装显示!
当然,这个时候会有如下情形产生(这就是我注孤生的原因!)

当然,这种做法的缺点也很明显
- 返回了一堆前端并不需要的数据
- 徒增前后端的交互次数
ok,通过上面的描述,大家应该能体会到Rest的缺点:REST接口时返回的数据格式、数据类型都是后端预先定义好的,如果返回的数据格式并不是调用者所期望的,调用者在处理上比较麻烦!
那么,有没有办法让前端自定灵活的使用查询语句,自己想捞什么数据就捞什么数据呢?
有的,那就是Graphql!
Graphql的出现
Graphql其实要这样理解
Graphql=grap(图)+query+lanage
是一种基于图的查询语言!那么,这张图长什么样?
OK,首先你要声明一下,你的图结构,嗯,用的就是Graphql的语法啦,像下面这样
type Book {
id: Int
bookname: String
authors: [Author]
}
type Author {
id: Int
name: String
age: String
}
type Query {
getBook(id: Int): Book
}
schema {
query: Query
}
对上面的语句进行一下解释。这里一共声明了三个类Book、Author、Query!其实,Book和Author大家都可以猜都出来是指啥,需要注意的一点是authors: [Author]这个地方,用了一个[]的语法,这代表Author是一个数组!
唯一需要说明的是,Query是什么鬼?
Query在这儿表明了该类型是这张图的入口,也就是根节点!我们的查询必须从根节点里的属性开始!这里我为了便于说明,只列了一个属性,也就是getBook,该属性是入口,必须从入口开始查!
那么,生成的图是长下面这样的

这里还有一个Resolver的概念,就是说,GragphQL解析到getBook方法的时候,方法体内容是啥?是在Resovler中定义的,我这里就不贴配置了,感兴趣的可以自己去官网阅读!
OK,接下来就是第二个问题,怎么查?
根据上面我说的,只能从根开始,根是getBook,那语句怎么写呢?如下所示
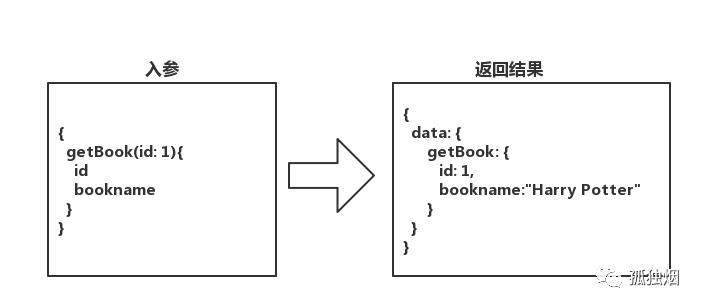
那你想加个字段,显示作者名字呢?直接像下面这么写

采用这种语法结构,后端的数据模型就变成了一张图,前端可以定制化自己的输出结构,同时可以减少前后端的沟通成本,提高灵活性!
一些疑问
(1)java语言中,对Graphql的支持如何?
在java中,有个jar包为graphql-java-tools提供了对Java的支持。
另外,考虑到现在大多是springboot项目,有大神封装好了starter包,供你们的springboot项目使用!
只需在项目中引入
<!-- graphql -->
<dependency>
<groupId>com.graphql-java</groupId>
<artifactId>graphql-spring-boot-starter</artifactId>
<version>4.0.0</version>
</dependency>
<dependency>
<groupId>com.graphql-java</groupId>
<artifactId>graphql-java-tools</artifactId>
<version>4.3.0</version>
</dependency>
即可让你的springboot项目拥有graphql的功能,非常方便!
(2)这样做不会加重前后端工作量么?
说句实在话,摸着良心说,前期确实加重了前后端的工作量!
对前端而言:需要去了解Graphql的语法!
对后端而言:不仅需要了解Graphql的语法,还需要去编写Schema和Resovler!
所以短期内,确实增加了工作量!但是从长远来看,同时降低了前后端的工作量!
第一,前端不用了解后端的数据结构,GraphQL自己生成可交互式的接口文档,前端可以自己测试调用
第二,后端不用在编写什么接口文档,GrapQL自动帮你生成,用起来非常舒心!
从Rest到Graphql的更多相关文章
- Facebook的Web开发三板斧:React.js、Relay和GraphQL
2015-02-26 孙镜涛 InfoQ Eric Florenzano最近在自己的博客上发表了一篇题为<Facebook教我们如何构建网站>的文章,他认为软件开发有些时候需要比较大的跨 ...
- facebook graphql
思想先进,前端直接从后台调用所需要的数据. 最简单的理解: 从"select * from 学生表" 进化为"select name, sex from 学生表" ...
- Graphql介绍(Introduction to GraphQL)
Introduction to GraphQL GraphQL介绍 Learn about GraphQL, how it works, and how to use it in this seri ...
- graphql 新API 开发方式
我们知道 GraphQL 使用 Schema 来描述数据,并通过制定和实现 GraphQL 规范 定义了支持 Schema 查询的 DSQL (Domain Specific Query Langua ...
- [GraphQL] Use GraphQLNonNull for Required Fields
While certain fields in a GraphQL Schema can be optional, there are some fields or arguments that ar ...
- [GraphQL] Use Arguments in a GraphQL Query
In GraphQL, every field and nested object is able to take in arguments of varying types in order to ...
- [GraphQL] Write a GraphQL Schema in JavaScript
Writing out a GraphQL Schema in the common GraphQL Language can work for simple GraphQL Schemas, but ...
- [GraphQL] Serve a GraphQL Schema as Middleware in Express
If we have a GraphQL Schema expressed in terms of JavaScript, then we have a convenient package avai ...
- [GraphQL] Use GraphQL's List Type for Collections
In order to handle collections of items in a GraphQL Schema, GraphQL has a List Type. In this video, ...
- [GraphQL] Use GraphQL's Object Type for Basic Types
We can create the most basic components of our GraphQL Schema using GraphQL's Object Types. These ty ...
随机推荐
- scrapy获取58同城数据
1. scrapy项目的结构 项目名字 项目名字 spiders文件夹 (存储的是爬虫文件) init 自定义的爬虫文件 核心功能文件 **************** init items 定义数据 ...
- Python爬虫中的URLError\HTTPError异常类,异常的抛出
# _*_ coding : utf-8 _*_# @Time : 2021/11/2 14:20# @Author : 秋泊酱 import urllib.request import urllib ...
- 15. mac安装多版本jdk
一.jdk下载地址 jdk官网下载地址:http://jdk.java.net/archive/ 二.安装jdk Mac的JDK都是安装到一个指定目录的:/Library/Java/JavaVirtu ...
- 使用VSCode编写,发布cnblogs
WriteCnBlog插件作者写的教程: https://www.cnblogs.com/caipeiyu/p/11774968.html
- Javascript复制内容到剪贴板,解决navigator.clipboard Cannot read property 'writeText' of undefined
起因 最近帮同事实现了一个小功能--复制文本到剪贴板,主要参考了前端大神阮一峰的博客,根据 navigator.clipboard 返回的 Clipboard 对象的方法 writeText() 写文 ...
- 【JAVA】笔记(12)---集合(1)-概述篇
楔子: 1.集合相当于一个容器,数组虽然也相当于一个容器,但是集合的特性更符合我们日常开发的需求,所以集合的使用更加频繁: 2.集合特性: 1)集合的长度可变,数组一经初始化,长度固定: 2)集合可以 ...
- Vulnhub-DarkHole_1 题解
Vulnhub-DarkHole_1-Writeup 靶机地址:DARKHOLE: 1 Difficulty: Easy 扫描与发现 使用arp-scan发现目标IP arp-scan -l 使用nm ...
- 爬虫——正则表达式爬取豆瓣电影TOP前250的中英文名
正则表达式爬取豆瓣电影TOP前250的中英文名 1.首先要实现网页的数据的爬取.新建test.py文件 test.py 1 import requests 2 3 def get_Html_text( ...
- P6072 『MdOI R1』Path
考虑我们有这样操作. 我们只要维护两点在子树内和两点在子树外的异或和即可. 前者可以类似于线段树合并的trie树合并. 后者有两种做法: 一种是把dfn序翻倍:然后子树补变成了一个区间最大异或问题,可 ...
- Mysql-单个left join 计算逻辑(一对多问题)
BUG背景: 我们有一个订单表 和 一个 物流表 它们通过 订单ID 进行一对一的关系绑定.但是由于物流表在保存订单信息的时候没有做判断该订单是否已经有物流信息,这就变成同一个订单id在物流表中存在多 ...