Tutorial_6 运行结果
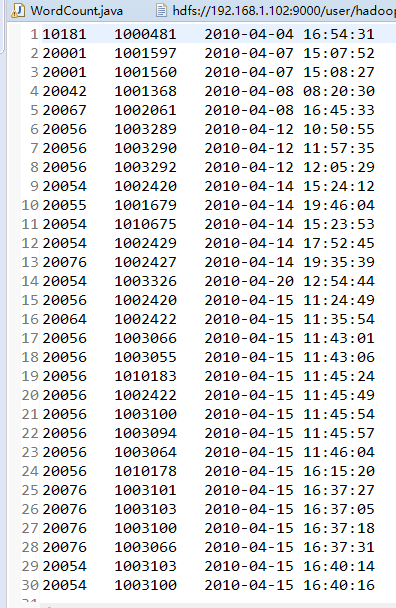
1.buyer_favorites.txt
2.代码
package mapreduce; import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer; import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser; public class WordCount {
public WordCount() {
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
// String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
String input = "hdfs://192.168.1.102:9000/user/hadoop/input/buyer_favorite1.txt";
String output = "hdfs://192.168.1.102:9000/user/hadoop/output";
String[] otherArgs = new String[] { input, output }; /* 直接设置输入参数 */
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
} Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
} FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
} public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable(); public IntSumReducer() {
} public void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
int sum = 0; IntWritable val;
for (Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable) i$.next();
} this.result.set(sum);
context.write(key, this.result);
}
} public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text(); public TokenizerMapper() {
} public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString(), "\t"); while (itr.hasMoreTokens()) {
this.word.set(itr.nextToken().split(" ")[0]);
context.write(this.word, one);
} }
}
}
3.运行结果

4.遇到的问题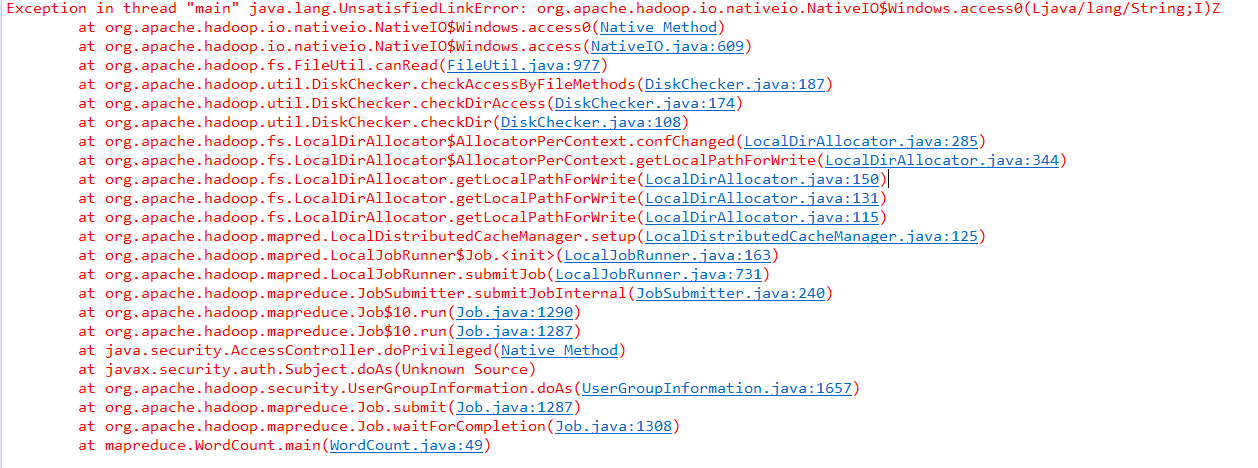
解决办法:
分析:
C:\Windows\System32下缺少hadoop.dll,把这个文件拷贝到C:\Windows\System32下面即可。
解决:
hadoop-common-2.2.0-bin-master下的bin的hadoop.dll放到C:\Windows\System32下,然后重启电脑,也许还没那么简单,还是出现这样的问题。(原博主是这么写的,实际上只是将hadoop.dll粘到了 C:\Windows\System32目录下就行了)
————————————————
声明:仅解决办法参考CSDN博客,文末附原文链接。
原文链接:https://blog.csdn.net/congcong68/article/details/42043093
Tutorial_6 运行结果的更多相关文章
- ASP.NET Aries 入门开发教程1:框架下载与运行
背景: 鉴于框架的使用者越来越多,文档太少,不少用户反映框架的入门门槛太高. 好吧,再辛苦下,抽时间写教程吧! 步骤1:下载框架源码 开源地址:https://github.com/cyq1162/A ...
- 在传统.NET Framework 上运行ASP.NET Core项目
新的项目我们想用ASP.NET Core来开发,但是苦于我们历史的遗产很多,比如<使用 JavaScriptService 在.NET Core 里实现DES加密算法>,我们要估计等到.N ...
- Sublime Text3配置在可交互环境下运行python快捷键
安装插件 在Sublime Text3下面写代码感觉很不错,但是写Python的时候遇到了一些问题. 用Sublime Text3打开python文件,或者在Sublime Text3下写好pytho ...
- hadoop 2.7.3本地环境运行官方wordcount-基于HDFS
接上篇<hadoop 2.7.3本地环境运行官方wordcount>.继续在本地模式下测试,本次使用hdfs. 2 本地模式使用fs计数wodcount 上面是直接使用的是linux的文件 ...
- hadoop 2.7.3本地环境运行官方wordcount
hadoop 2.7.3本地环境运行官方wordcount 基本环境: 系统:win7 虚机环境:virtualBox 虚机:centos 7 hadoop版本:2.7.3 本次先以独立模式(本地模式 ...
- Docker笔记一:基于Docker容器构建并运行 nginx + php + mysql ( mariadb ) 服务环境
首先为什么要自己编写Dockerfile来构建 nginx.php.mariadb这三个镜像呢?一是希望更深入了解Dockerfile的使用,也就能初步了解docker镜像是如何被构建的:二是希望将来 ...
- Linux scp 设置nohup后台运行
Linux scp 设置nohup后台运行 1.正常执行scp命令 2.输入ctrl + z 暂停任务 3.bg将其放入后台 4.disown -h 将这个作业忽略HUP信号 5.测试会话中断,任务继 ...
- 在docker中运行ASP.NET Core Web API应用程序(附AWS Windows Server 2016 widt Container实战案例)
环境准备 1.亚马逊EC2 Windows Server 2016 with Container 2.Visual Studio 2015 Enterprise(Profresianal要装Updat ...
- Android数据存储之Android 6.0运行时权限下文件存储的思考
前言: 在我们做App开发的过程中基本上都会用到文件存储,所以文件存储对于我们来说是相当熟悉了,不过自从Android 6.0发布之后,基于运行时权限机制访问外置sdcard是需要动态申请权限,所以以 ...
随机推荐
- NVIDIA TensorRT高性能深度学习推理
NVIDIA TensorRT高性能深度学习推理 NVIDIA TensorRT 是用于高性能深度学习推理的 SDK.此 SDK 包含深度学习推理优化器和运行时环境,可为深度学习推理应用提供低延迟和高 ...
- string大小写转换
string大小写转换 源码: 1 #include <string> 2 #include <iostream> 3 #include <algorithm> 4 ...
- centos 7查看系统网络情况netstat
查看系统网络情况 netstat ➢ 基本语法 netstat [选项] ➢ 选项说明 -an 按一定顺序排列输出 -p 显示哪个进程在调用 应用案例 请查看服务名为 sshd 的服务的信息. ➢ N ...
- 「模拟8.29」chinese(性质)·physics·chemistry(概率期望)
T1 chinese 根据他的问题i*f[i]我们容易联想到,答案其实是每种方案中每个点的贡献为1的加和 我们可以转变问题,每个点在所有方案的贡献 进而其实询问就是1-k的取值,有多少中方案再取个和 ...
- 555定时器(1)单稳态触发器电路及Multisim实例仿真
555定时器(Timer)因内部有3个5K欧姆分压电阻而得名,是一种多用途的模数混合集成电路,它能方便地组成施密特触发器.单稳态触发器与多谐振荡器,而且成本低,性能可靠,在各种领域获得了广泛的应用. ...
- QTreeView 使用 QStandardItemModel
QTreeView 使用 QStandardItemModel @ 目录 QTreeView 使用 QStandardItemModel 前言 一.直接上图 二.添加同级结点项 1.思路 2.实现 二 ...
- hdu1233 最小生成树Prim算法和Kruskal算法
Prim算法 时间复杂度:O(\(N^2\),N为结点数) 说明:先任意找一个点标记,然后每次找一条最短的两端分别为标记和未标记的边加进来,再把未标记的点标记上.即每次加入一条合法的最短的边,每次扩展 ...
- mapboxgl绘制3D线
最近遇到个需求,使用mapboxgl绘制行政区划图层,要求把行政区划拔高做出立体效果,以便突出显示. 拿到这个需求后,感觉很简单呀,只需要用fill-extrusion方式绘制就可以啦,实现出来是这个 ...
- 快速了解ARP
目录 前言 一.MAC 1.MAC地址三种帧 二.ARP 1.五种ARP 三.ARP老化 四.什么时候会发送免费ARP 五.代理ARP 六.ARP欺骗 总结 前言 分别介绍MAC地址和五种ARP报文 ...
- 单片机项目中使用新IC芯片的调试方法
前两天,一位小伙伴咨询我一款新IC芯片怎么使用,借此机会我顺便把我日常工作中经常用到的一种调试方法介绍给小伙伴们,希望对对大家有所帮助.准备仓促,文中难免有技术性错误,欢迎大家给予指正,并给出好的建议 ...