Spring系列之HikariCP连接池
上两篇文章,我们讲到了Spring中如何配置单数据源和多数据源,配置数据源的时候,连接池有很多选择,在SpringBoot 1.0中使用的是Tomcat的DataSource,在SpringBoot 2.0中,我们使用默认连接池是HikariCP,本文讲一下HikariCP。
为什么SpringBoot 2.0要选择HikariCP来作为默认的连接池呢?
我们先看一下官网的一张对比图。
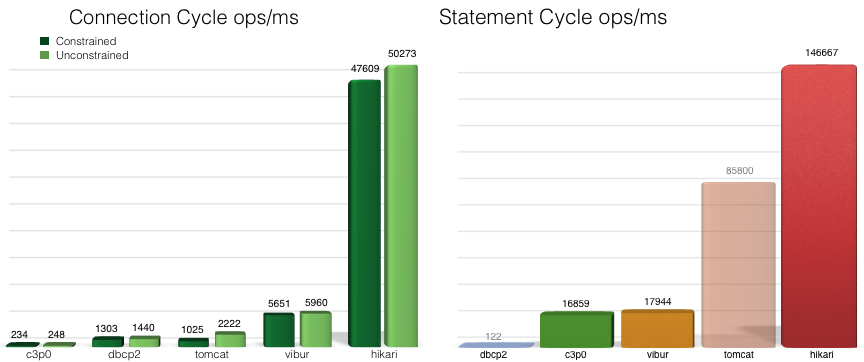
一个连接周期定义为单个DataSource.getConnection()/ Connection.close()。 一个语句周期定义为单个Connection.prepareStatement(), Statement.execute(), Statement.close()
从上图看出,HikariCP和常见的连接池相比,优势非常明显。
为什么HikariCP那么快呢?根据官网概要总结了以下几点
- 字节码精简 :字节码级别优化(很多⽅法通过 JavaAssist ⽣成),直到编译后的字节码最少,这样,CPU缓存可以加载更多的程序代码;
- 优化代理和拦截器:减少代码,例如HikariCP的Statement proxy只有100行代码,只有BoneCP的十分之一;
- 自定义数组类型:(FastStatementList)代替ArrayList:避免每次get()调用都要进行range check,避免调用remove()时的从头到尾的扫描;
- 自定义集合类型(ConcurrentBag:提高并发读写的效率;
- 代理类的优化(⽐如,⽤ invokestatic 代替了 invokevirtual)
- 其他针对BoneCP缺陷的优化,比如对于耗时超过一个CPU时间片的方法调用的研究(但没说具体怎么优化)。
既然HikariCP那么快,接下来就看一下在Spring中怎么使用HikariCP?
在Spring Boot 2.x中
• 默认使⽤ HikariCP
• 配置 spring.datasource.hikari.* 配置
在Spring Boot 1.x中
• 默认使⽤ Tomcat 连接池,需要移除 tomcat-jdbc 依赖
• 在application.properties文件中加上spring.datasource.type=com.zaxxer.hikari.HikariDataSource
我们来看一下SpringBoot2.0怎么使用配置HikariDataSource的
下面是org.springframework.boot.autoconfigure.jdbc.DataSourceConfiguration中的相关代码
/**
* 下面的三个注解意思是当classpath中有HikariDataSource.class,并且Spring上下文中没有配置DataSource的bean
* 并且spring.datasource.type的值是com.zaxxer.hikari.HikariDataSource的时候,SpringBoot自动帮我们选择默认的连接池是HikariDataSource
*/
@ConditionalOnClass({HikariDataSource.class})
@ConditionalOnMissingBean({DataSource.class})
@ConditionalOnProperty(name = {"spring.datasource.type"},havingValue = "com.zaxxer.hikari.HikariDataSource",matchIfMissing = true)
static class Hikari {
Hikari() {
}
@Bean
@ConfigurationProperties(prefix = "spring.datasource.hikari")
HikariDataSource dataSource(DataSourceProperties properties) {
HikariDataSource dataSource = (HikariDataSource)DataSourceConfiguration.createDataSource(properties, HikariDataSource.class);
if (StringUtils.hasText(properties.getName())) {
dataSource.setPoolName(properties.getName());
}
return dataSource;
}
}
最后看看,HikariCp配置的参数有哪些?
# 不同数据源这四个配置都会用到
spring.datasource.url=jdbc:mysql://localhost:3306/test
spring.datasource.username=root
spring.datasource.password=123456
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
#以下的配置项是hikari特有的配置
# 等待连接池分配连接的最大时长(毫秒),超过这个时长还没可用的连接则发生SQLException, 默认:30秒
spring.datasource.hikari.connection-timeout=30000
# 最小连接数
spring.datasource.hikari.minimum-idle=5
# 最大连接数
spring.datasource.hikari.maximum-pool-size=15
# 自动提交
spring.datasource.hikari.auto-commit=true
# 一个连接idle状态的最大时长(毫秒),超时则被释放(retired),默认:10分钟
spring.datasource.hikari.idle-timeout=600000
# 连接池名字
spring.datasource.hikari.pool-name=DatebookHikariCP
# 一个连接的生命时长(毫秒),超时而且没被使用则被释放(retired),默认:30分钟 1800000ms,建议设置比数据库超时时长少60秒
spring.datasource.hikari.max-lifetime=28740000
spring.datasource.hikari.connection-test-query=SELECT 1
#以下是针对MYSQL驱动的配置参数
# 在每个连接中缓存的语句的数量。默认值为保守值25。建议将其设置为250-500之间
spring.datasource.hikari.prepStmtCacheSize = 300
# 缓存的已准备SQL语句的最大长度,默认值是256,但是往往这个长度不够用
spring.datasource.hikari.prepStmtCacheSqlLimit = 2048
# 缓存开关,如果这里设置为false,上面两个参数都不生效
spring.datasource.hikari.cachePrepStmts = true
#较新版本的 MySQL 支持服务器端准备好的语句,这可以提供实质性的性能提升
spring.datasource.hikari.useServerPrepStmts = true
HikariCP官方地址: https://github.com/brettwooldridge/HikariCP/wiki
Spring系列之HikariCP连接池的更多相关文章
- 在 Spring Boot 中使用 HikariCP 连接池
上次帮小王解决了如何在 Spring Boot 中使用 JDBC 连接 MySQL 后,我就一直在等,等他问我第三个问题,比如说如何在 Spring Boot 中使用 HikariCP 连接池.但我等 ...
- 深入理解Spring Boot数据源与连接池原理
Create by yster@foxmail.com 2018-8-2 一:开始 在使用Spring Boot数据源之前,我们一般会导入相关依赖.其中数据源核心依赖就是spring‐boot‐s ...
- SpringBoot 使用Hikaricp连接池
1.添加pom.xml依赖 如果是SpringBoot2.0,那么默认的连接池就是Hikaricp,不需要配置 其他的,如果继承 <parent> <groupId>org.s ...
- Spring Boot之默认连接池配置策略
注意:如果我们使用spring-boot-starter-jdbc 或 spring-boot-starter-data-jpa “starters”坐标,Spring Boot将自动配置Hikari ...
- Java代码生成器加入postgresql数据库、HikariCP连接池、swagger2支持!
目录 前言 PostgreSql VS MySql HikariCP VS Druid Swagger2 自定义参数配置一览 结语 前言 最近几天又抽时间给代码生成器增加了几个新功能(预计今晚发布 ...
- HikariCP连接池
1.HikariCP连接池是什么? HikariCP是数据库连接池,而且是号称史上最快的,而且目前来看确实是这样的,SpringBoot2.0也已经采用HikariCP作为默认连接池配置. githu ...
- spring boot配置druid连接池连接mysql
Spring Boot 集成教程 Spring Boot 介绍 Spring Boot 开发环境搭建(Eclipse) Spring Boot Hello World (restful接口)例子 sp ...
- Spring boot中配置HikariCP连接池
# jdbc_config datasourcespring.datasource.driver-class-name=com.mysql.cj.jdbc.Driverspring.datasourc ...
- spring引入HikariCP连接池
1.导入jar包 2.applicationContext.xml中配置 <bean id="dataSource" class="com.zaxxer.hikar ...
随机推荐
- 「NOIP2017」宝藏
「NOIP2017」宝藏 题解 博客阅读效果更佳 又到了一年一度NOIPCSP-S 赛前复习做真题的时间 于是就遇上了这道题 首先观察数据范围 \(1 \le n \le 12\) ,那么极大可能性是 ...
- C语言:冒泡排序例子
//冒泡排序 //14个数字排序:14个数的组合:14*13/2=91次 理论上比较91次 ,实际只有39次进行了变量交换 #include <stdio.h> void bubble_s ...
- C语言:转义字符 ++a例子
#include <stdio.h> int main() { printf("a\bwhat\'s\tyour\tname\n"); int k; printf(&q ...
- 在 .NET 中创建对象的几种方式的对比
在 .net 中,创建一个对象最简单的方法是直接使用 new (), 在实际的项目中,我们可能还会用到反射的方法来创建对象,如果你看过 Microsoft.Extensions.DependencyI ...
- ES6 对象定义简写及常用的扩展方法
1.ES6 对象定义简写 es6提供了对象定义里的属性,方法简写方式: 假如属性和变量名一样,可以省略,包括定义对象方法function也可以省略 <script type="text ...
- 高版本(8以上)tomcat不支持rest中的delete和put方式请求怎么办
出现问题 当我们去访问delete方式和put方式: 后来才知道tomcat8以上是不支持delete方式和put方式 解决方法: 在跳转目标的jsp头文件上改为(加上了isErrorPage=&qu ...
- 深入学习Netty(5)——Netty是如何解决TCP粘包/拆包问题的?
前言 学习Netty避免不了要去了解TCP粘包/拆包问题,熟悉各个编解码器是如何解决TCP粘包/拆包问题的,同时需要知道TCP粘包/拆包问题是怎么产生的. 在此博文前,可以先学习了解前几篇博文: 深入 ...
- 【搜索】单词方阵 luogu-1101
题目描述 给一n×n的字母方阵,内可能蕴含多个"yizhong"单词.单词在方阵中是沿着同一方向连续摆放的.摆放可沿着8个方向的任一方向,同一单词摆放时不再改变方向,单词与单词之间 ...
- MySQL架构及优化原理
1 MySQL架构原理 1.1 MySQL架构原理参看下述链接: https://blog.csdn.net/hguisu/article/details/7106342 1.2 MySQL优化详解参 ...
- js学习笔记之字符串统计出现次数最多的字符
1.方法:把字符串中字符替换为空,并和之前的字符串的长度相减,得到已经被替换的字符的数量,依次比较获得出现次数最多的字符 var str ="adadfdfseffserfefsefseef ...