python基础-第九篇-9.1初了解Python线程、进程、协程
了解相关概念之前,我们先来看一张图

进程:
- 优点:同时利用多个cpu,能够同时进行多个操作
- 缺点:耗费资源(重新开辟内存空间)
线程:
- 优点:共享内存,IO操作时候,创造并发操作
- 缺点:抢占资源
通过对比,我们可以得出:
- 由于计算多用到cpu,所以多进程适合计算密集型
- 由于IO操作不用到cpu,所以多线程适合IO密集型
- 进程不是越多越好,cpu个数=进程个数
- 线程也不是越多越好,具体案例具体分析,请求上下文切换耗时
- 计算机中执行任务的最小单位:线程
- 进程和线程的目的都是提高效率
- 另外,GIL全局解释器锁,这个是Python独有的,作用是一个进程里一次只能执行一个线程,当然这个锁只适用于需要调用cpu的情况
Python线程
Threading用于提供线程相关的操作,线程是应用程序中工作的最小单元
import threading
import time def show(arg):
time.sleep(1)
print('thread'+str(arg)) for i in range(10):
t = threading.Thread(target=show,args=(i,))
t.start() print('main thread stop')
上述代码创建了10个前台线程,然后控制器就交给了cpu,cpu根据指定算法进行调度,分片执行指令
更多方法:
- start 线程准备就绪,等待CPU调度
- setName 为线程设置名称
- getName 获取线程名称
- setDaemon 设置为后台线程或前台线程(默认)
如果是后台线程,主线程执行过程中,后台线程也在进行,主线程执行完毕后,后台线程不论成功与否,均停止
如果是前台线程,主线程执行过程中,前台线程也在进行,主线程执行完毕后,等待前台线程也执行完成后,程序停止
- join 逐个执行每个线程,执行完毕后继续往下执行
- run 线程被cpu调度后自动执行线程对象的run方法
自定义线程类:
import threading
import time class MyThread(threading.Thread): def __init__(self,num):
threading.Thread.__init__(self)
self.num = num def run(self): #定义每个线程要运行的函数 print('running on number:%s'%self.num)
time.sleep(3) if __name__ == '__main__':
t1 = MyThread(1)
t2 = MyThread(2)
t1.start()
t2.start()
不过我们有个疑问啦,在定义的这个类中,根本没涉及调用run函数,这是怎么实现的呢??
那我们去看下源码就明白了,其实是start方法再起作用
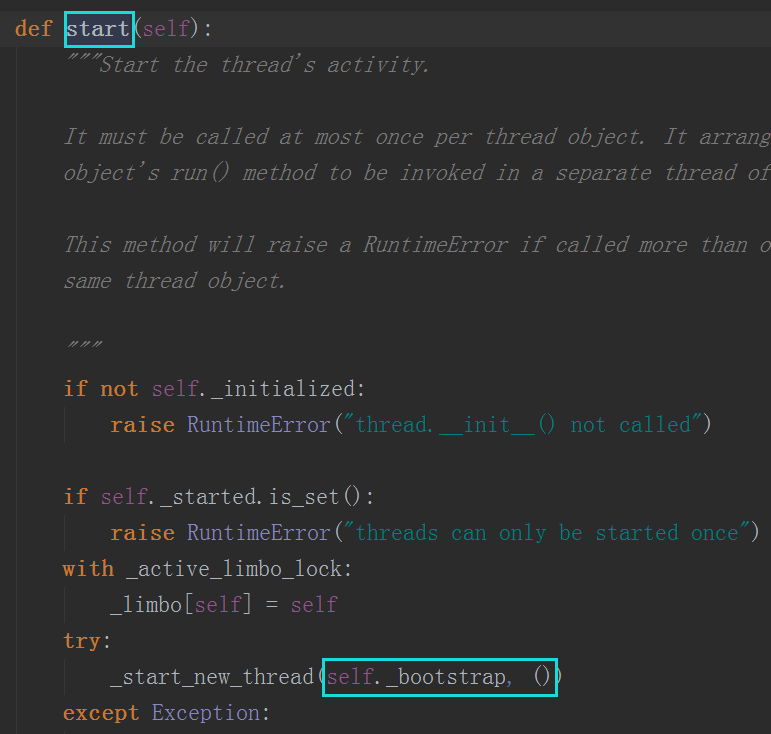


所以start方法在底层是调用了run方法
线程锁(Lock、RLock)
由于线程之间是进行随机调度,所以不可避免的存在多个线程同时修改同一条数据,从而可能会出现脏数据,所以出现了线程锁,同一时刻只允许一个线程执行操作。
未上锁的:
import threading
import time num = 0 def show(arg):
global num
time.sleep(1)
num += 1
print(num) for i in range(10):
t = threading.Thread(target=show,args=(i,))
t.start() print('main thread stop')
上锁的:
import threading
import time num = 0
lock = threading.RLock() def func():
lock.acquire()
global num
num += 1
time.sleep(1)
print(num)
lock.release() for i in range(10):
t = threading.Thread(target=func)
t.start()
我们会发现,这两段代码输出的结果都一样,并没有产生脏数据,但是细心你会发现:打印结果的过程是不同的,未加锁的--可以说是几乎同时打印结果,而加了锁的,则是一个一个打印,这就是锁在起作用,对同一资源,在一个点上只能执行一个线程。
事件(event)
Python线程的事件用于主线程控制其他线程的执行,事件主要提供了三个方法:set、wait、clear
事件处理的机制:全局定义了一个‘flag’,如果‘flag’值为False,那么当程序执行event.wait方法时就会阻塞,如果‘Flag’值为True,那么event.wait方法时便不再阻塞
- clear 将‘Flag’设置为False
- set 将‘Flag’设置为True
import threading
import time def do(event):
print('start')
event.wait()
print('execute') event_obj = threading.Event()
for i in range(10):
t = threading.Thread(target=do,args=(event_obj,))
t.start() event_obj.clear()
# time.sleep(2)
inp = input('input:')
if inp == 'true':
event_obj.set()
import threading
import time event = threading.Event() def func():
print('%s wait for event...'%threading.currentThread().getName())
#等待--阻塞
event.wait() #收到事件后进入运行状态
print('%s recv event.'%threading.currentThread().getName()) t1 = threading.Thread(target=func)
t2 = threading.Thread(target=func)
t1.start()
t2.start() time.sleep(2) #发出事件通知
print('MainThread set event.')
event.set()
信号量(Semaphore)
Semaphore是同时允许一定数量的线程更改数据,比如厕所有3个坑,那最多只允许3个人上厕所,后面的人只能等里面有人出来了才能再进去。
import threading,time def run(n):
semaphore.acquire()
time.sleep(1)
print('run the thread:%s'%n)
semaphore.release() if __name__ == '__main__':
num = 0
#最多允许5个线程同时运行
semaphore = threading.BoundedSemaphore(5)
for i in range(20):
t = threading.Thread(target=run,args=(i,))
t.start()
条件(Condition)
使用线程等待,只有满足某条件时,才释放n个线程
- acquire 给线程上锁
- wait wait方法释放当前线程占用的锁,同时挂起线程,直至被唤醒或超时(需timeout参数)。当线程被唤醒并重新占有锁的时候,程序才会继续执行下去。
- notify 唤醒一个挂起的线程(如果存在挂起的线程),不会释放所占用的锁
- notifyall 调用这个方法将通知等待池中所有线程,这些线程都将进入锁定池尝试获得锁定,此方法不会释放锁定,使用前线程必须已获得锁定。否则将抛出异常
import threading
import time
def consumer(cond):
with cond:
print("consumer before wait")
cond.wait()
print("consumer after wait") def producer(cond):
with cond:
print("producer before notifyAll")
cond.notifyAll()
print("producer after notifyAll") condition = threading.Condition()
c1 = threading.Thread(name="c1", target=consumer, args=(condition,))
c2 = threading.Thread(name="c2", target=consumer, args=(condition,)) p = threading.Thread(name="p", target=producer, args=(condition,)) c1.start()
time.sleep(2)
c2.start()
time.sleep(2)
p.start() # consumer()线程要等待producer()设置了Condition之后才能继续。
import threading def run(n):
con.acquire()
con.wait()
print('run the thread:%s'%n)
con.release() if __name__ == '__main__': con = threading.Condition()
for i in range(10):
t = threading.Thread(target=run,args=(i,))
t.start() while True:
inp = input('>>>')
if inp == 'q':
break con.acquire()
con.notify(int(inp))
con.release()
Python进程
from multiprocessing import Process
import time def foo(i):
print('say hi',i) if __name__ == '__main__':
for i in range(10):
p = Process(target=foo,args=(i,))
p.start()
我们可以看到,进程和线程代码实现几乎是相同的,对于进程而言,模块是multiprocessing,另外,在创建进程前,加了一个__name__的验证,这是由于操作系统的原因,反正你只要加上了就可以了。
另外,我们已经提到过,创建进程就等同搭建了一个进程环境,消耗内存是不小的(相对线程)。
进程数据共享
由于进程创建时,数据是各持有一份的,默认情况下进程间是无法共享数据的。
from multiprocessing import Process
import time li = [] def foo(i):
li.append(i)
print('say hi',li) if __name__ == '__main__':
for i in range(10):
p = Process(target=foo,args=(i,))
p.start() print('ending',li) 结果为:
say hi [1]
say hi [0]
say hi [2]
say hi [3]
say hi [4]
say hi [5]
say hi [6]
say hi [7]
ending []
say hi [8]
say hi [9]
从结果里,我们也知道,进程间数据是不共享的,列表元素没有实现累加。
不过,如果你硬要实现共享的话,办法还是有的,请往下看:
方法一:引用数组Array
from multiprocessing import Process,Array def Foo(temp,i):
temp[i] = 100+i
for item in temp:
print(i,'----->',item) if __name__ == '__main__':
temp = Array('i', [11, 22, 33, 44]) for i in range(2):
p = Process(target=Foo,args=(temp,i,))
p.start()
方法二:manage.dict()
from multiprocessing import Process,Manager def Foo(dic,i):
dic[i] = 100 + i
print(dic.values()) if __name__ == '__main__':
manage = Manager()
dic = manage.dict() for i in range(2):
p = Process(target=Foo,args=(dic,i,))
p.start()
p.join()
方法三:multiprocessing.Queue
from multiprocessing import Process, Queue def f(i,q):
print(i,q.get()) if __name__ == '__main__':
q = Queue() q.put("h1")
q.put("h2")
q.put("h3") for i in range(10):
p = Process(target=f, args=(i,q,))
p.start()
当创建进程时(非使用时),共享数据会被拿到子进程中,当进程中执行完毕后,再赋值给原值,另外涉及数据共享就必定存在同一份数据被多个进程同时修改,所以在multiprocessing模块里也也提供了RLock类。
进程池
进程池内部维护一个进程序列,当使用时,则去进程池中获取一个进程,如果进程池序列中没有可使用的进程,那么程序就会等待,直到进程池中有可用进程为止。
apply(func[, args[, kwds]]) :使用arg和kwds参数调用func函数,结果返回前会一直阻塞,由于这个原因,apply_async()更适合并发执行,另外,func函数仅被pool中的一个进程运行。
apply_async(func[, args[, kwds[, callback[, error_callback]]]]) : apply()方法的一个变体,会返回一个结果对象。如果callback被指定,那么callback可以接收一个参数然后被调用,当结果准备好回调时 会调用callback,调用失败时,则用error_callback替换callback。 Callbacks应被立即完成,否则处理结果的线程会被阻塞。
close() : 阻止更多的任务提交到pool,待任务完成后,工作进程会退出。
terminate() : 不管任务是否完成,立即停止工作进程。在对pool对象进程垃圾回收的时候,会立即调用terminate()。
join() : wait工作线程的退出,在调用join()前,必须调用close() or terminate()。这样是因为被终止的进程需要被父进程调用wait(join等价与wait),否则进程会成为僵尸进程
- apply 每一个任务是排队进行
- apply_async 每一个任务都并发进行,可以设置回调函数
from multiprocessing import Process,Pool
import time def Foo(i):
time.sleep(2)
return i+100 def Bar(arg):
print(arg) if __name__ == '__main__':
pool = Pool(5) for i in range(10):
pool.apply_async(func=Foo,args=(i,),callback=Bar) print('end')
pool.close()
pool.join() #进程池中进程执行完毕后再关闭
print('really end')
队列(queue)
适用于多线程编程的先进先出数据结构,可以用来安全的传递多线程信息。
- q = queue.Queue(maxsize=0) 构造一个先进显出队列,maxsize指定队列长度,参数不填默认表示队列长度无限制。
- q.join() 等到队列为kong的时候,在执行别的操作
- q.put(item, block=True, timeout=None) 将item放入Queue尾部,item必须存在,可以参数block默认为True,表示当队列满时,会等待队列给出可用位置,为False时为非阻塞,此时如果队列已满,会引发queue.Full 异常。 可选参数timeout,表示 会阻塞设置的时间,过后,如果队列无法给出放入item的位置,则引发 queue.Full 异常
- q.get(block=True, timeout=None) 移除并返回队列头部的一个值,可选参数block默认为True,表示获取值的时候,如果队列为空,则阻塞,为False时,不阻塞,若此时队列为空,则引发 queue.Empty异常。 可选参数timeout,表示会阻塞设置的时候,过后,如果队列为空,则引发Empty异常。
import threading
import queue que = queue.Queue(10) def s(i):
que.put(i) def x(i):
g = que.get(i)
print('get',g) for i in range(1,13):
t = threading.Thread(target=s,args=(i,))
t.start() for i in range(1,11):
t = threading.Thread(target=x,args=(i,))
t.start() print('size',que.qsize()) 结果为:
get 1
get 2
get 3
get 4
get 5
get 6
get 7
get 8
get 9
get 10
size
Python协程
线程和进程的操作是由程序触发系统接口,最后的执行者是系统;而协程的操作则是程序员
协程存在的意义:对于多线程应用,cpu通过切片来切换线程间的执行,线程切换时需要耗时(保存状态,下次继续)。协程,则只使用一个线程,在一个线程中规定某个代码执行顺序。
协程的适用场景:当程序中存在大量不需要cpu的操作时(IO),适用于协程。例如:爬虫
greenlet
from greenlet import greenlet def test1():
print 12
gr2.switch()
print 34
gr2.switch() def test2():
print 56
gr1.switch()
print 78 gr1 = greenlet(test1)
gr2 = greenlet(test2)
gr1.switch()
gevent
import gevent def foo():
print('Running in foo')
gevent.sleep(0)
print('Explicit context switch to foo again') def bar():
print('Explicit context to bar')
gevent.sleep(0)
print('Implicit context switch back to bar') gevent.joinall([
gevent.spawn(foo),
gevent.spawn(bar),
])
from gevent import monkey; monkey.patch_all()
import gevent
import urllib2 def f(url):
print('GET: %s' % url)
resp = urllib2.urlopen(url)
data = resp.read()
print('%d bytes received from %s.' % (len(data), url)) gevent.joinall([
gevent.spawn(f, 'https://www.python.org/'),
gevent.spawn(f, 'https://www.yahoo.com/'),
gevent.spawn(f, 'https://github.com/'),
])
遇到IO自动切换
欢迎大家对我的博客内容提出质疑和提问!谢谢
笔者:拍省先生
python基础-第九篇-9.1初了解Python线程、进程、协程的更多相关文章
- Python学习笔记整理总结【网络编程】【线程/进程/协程/IO多路模型/select/poll/epoll/selector】
一.socket(单链接) 1.socket:应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口.在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socke ...
- 15.python并发编程(线程--进程--协程)
一.进程:1.定义:进程最小的资源单位,本质就是一个程序在一个数据集上的一次动态执行(运行)的过程2.组成:进程一般由程序,数据集,进程控制三部分组成:(1)程序:用来描述进程要完成哪些功能以及如何完 ...
- python 线程 进程 协程 学习
转载自大神博客:http://www.cnblogs.com/aylin/p/5601969.html 仅供学习使用···· python 线程与进程简介 进程与线程的历史 我们都知道计算机是由硬件和 ...
- python之并发编程(线程\进程\协程)
一.进程和线程 1.进程 假如有两个程序A和B,程序A在执行到一半的过程中,需要读取大量的数据输入(I/O操作),而此时CPU只能静静地等待任务A读取完数据才能继续执行,这样就白白浪费了CPU资源.是 ...
- python基础-第九篇-9.2线程与多线程
单线程 import time beginTime = time.time() for a in range(10): print(a) time.sleep(1) shijian = time.ti ...
- python基础-第九篇-9.3线程池
简单版 import queue import threading class ThreadPool(object): def __init__(self, max_num=20): self.que ...
- python中线程 进程 协程
多线程:#线程的并发是利用cpu上下文的切换(是并发,不是并行)#多线程执行的顺序是无序的#多线程共享全局变量#线程是继承在进程里的,没有进程就没有线程#GIL全局解释器锁#只要在进行耗时的IO操作的 ...
- python基础之进程、线程、协程篇
一.多任务(多线程) 多线程特点:(1)线程的并发是利用cpu上下文的切换(是并发,不是并行)(2)多线程执行的顺序是无序的(3)多线程共享全局变量(4)线程是继承在进程里的,没有进程就没有线程(5) ...
- 图解Python 【第八篇】:网络编程-进程、线程和协程
本节内容一览图: 本章内容: 同步和异步 线程(线程锁.threading.Event.queue 队列.生产者消费者模型.自定义线程池) 进程(数据共享.进程池) 协程 一.同步和异步 你叫我去吃饭 ...
随机推荐
- [Spring Framework]学习笔记--@Component等stereotype的基础
在继续讲解Spring MVC之前,需要说一下常用的几个用来标记stereotype的annotation. @Component,@Controller,@Repository,@Service. ...
- IIS短文件名泄露漏洞危害及防范方法(转)
攻击方法(转自http://blog.sina.com.cn/s/blog_64a3795a01017xqt.html) 一直在寻找一种方法,如果我可以使用通配符"*" 和 &qu ...
- JS学习笔记(1)--sort排序
sort() 方法用于对数组的元素进行排序. 请注意,数组在原数组上进行排序,不生成副本. 说明 如果调用该方法时没有使用参数,将按字母顺序对数组中的元素进行排序,说得更精确点,是按照字符编码的顺序进 ...
- (C#)程序员必读的一些书籍
前言 ·貌似公司里很著名的一句话,在这里套用过来了,WP研发工程师,首先是WPF/SL研发工程师,WPF/SL研发工程师首先是是个C#研发工程师,C#研发工程师首先Windows研发工程师.Windo ...
- Soursight Insight 使用小结
1.Soursight Insight中添加自需要的文件过滤器: options->document options ->add type document type name:scatt ...
- 测试网站访问速度的方法(GTmetrix)
全方位的免费网站速度测试工具 — GTmetrix 它结合了Google Page Speed和Yahoo! YSlow的网页速度测试功能,并且提供可行的建议帮你改善网站速度.会根据网站的具体情况, ...
- 【BZOJ】1619: [Usaco2008 Nov]Guarding the Farm 保卫牧场(dfs)
http://www.lydsy.com/JudgeOnline/problem.php?id=1619 首先不得不说,,题目没看懂.... 原来就是找一个下降的联通块.... 排序后dfs标记即可. ...
- Spring Boot注解(annotation)列表
(1)@SpringBootApplication 申明让spring boot自动给程序进行必要的配置,这个配置等同于: @Configuration ,@EnableAutoConfigurati ...
- hdu 1058:Humble Numbers(动态规划 DP)
Humble Numbers Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)To ...
- 剑指 offer set 17 判断一棵树是否是平衡树
总结 1. 书上给出一个简洁代码, 说是会重复遍历. 2. 框架相同, 可以写出下面的代码 class Solution { public: bool ans; int getHeight(TreeN ...